 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiply Robust Estimator Circumvents Hyperparameter Tuning of Neural Network Models in Causal Inference
Jul 20, 2023Estimation of the Average Treatment Effect (ATE) is often carried out in 2 steps, wherein the first step, the treatment and outcome are modeled, and in the second step the predictions are inserted into the ATE estimator. In the first steps, numerous models can be fit to the treatment and outcome, including using machine learning algorithms. However, it is a difficult task to choose among the hyperparameter sets which will result in the best causal effect estimation and inference. Multiply Robust (MR) estimator allows us to leverage all the first-step models in a single estimator. We show that MR estimator is $n^r$ consistent if one of the first-step treatment or outcome models is $n^r$ consistent. We also show that MR is the solution to a broad class of estimating equations, and is asymptotically normal if one of the treatment models is $\sqrt{n}$-consistent. The standard error of MR is also calculated which does not require a knowledge of the true models in the first step. Our simulations study supports the theoretical findings.
Doubly Robust Estimation with Machine Learning Predictions
Aug 03, 2021
The estimation of Average Treatment Effect (ATE) as a causal parameter is carried out in two steps, wherein the first step, the treatment, and outcome are modeled to incorporate the potential confounders, and in the second step, the predictions are inserted into the ATE estimators such as the Augmented Inverse Probability Weighting (AIPW) estimator. Due to the concerns regarding the nonlinear or unknown relationships between confounders and the treatment and outcome, there has been an interest in applying non-parametric methods such as Machine Learning (ML) algorithms instead. \cite{farrell2018deep} proposed to use two separate Neural Networks (NNs) where there's no regularization on the network's parameters except the Stochastic Gradient Descent (SGD) in the NN's optimization. Our simulations indicate that the AIPW estimator suffers extensively if no regularization is utilized. We propose the normalization of AIPW (referred to as nAIPW) which can be helpful in some scenarios. nAIPW, provably, has the same properties as AIPW, that is double-robustness and orthogonality \citep{chernozhukov2018double}. Further, if the first step algorithms converge fast enough, under regulatory conditions \citep{chernozhukov2018double}, nAIPW will be asymptotically normal.
The Bias-Variance Tradeoff of Doubly Robust Estimator with Targeted $L_1$ regularized Neural Networks Predictions
Aug 02, 2021
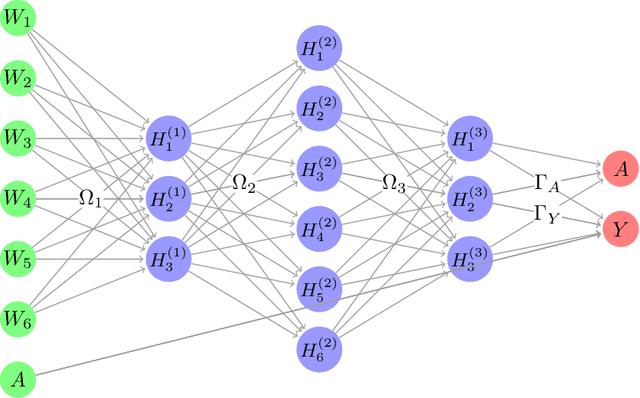
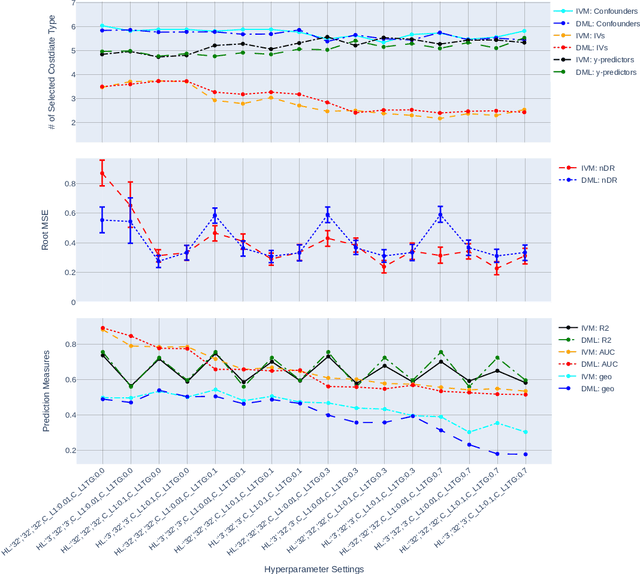
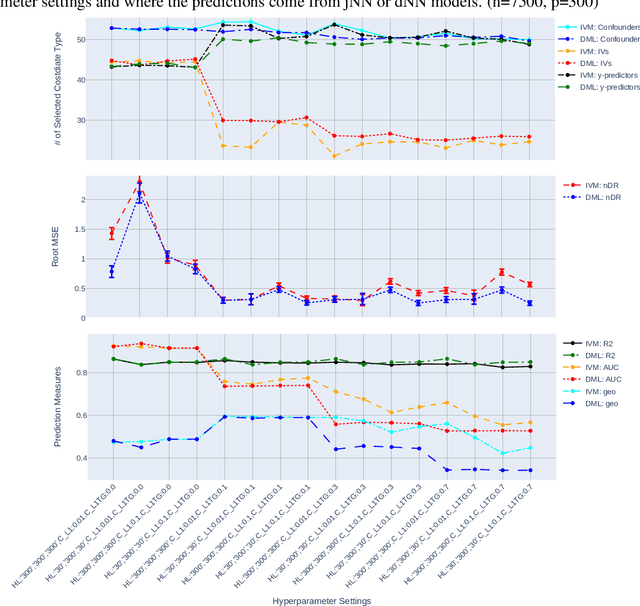
The Doubly Robust (DR) estimation of ATE can be carried out in 2 steps, where in the first step, the treatment and outcome are modeled, and in the second step the predictions are inserted into the DR estimator. The model misspecification in the first step has led researchers to utilize Machine Learning algorithms instead of parametric algorithms. However, existence of strong confounders and/or Instrumental Variables (IVs) can lead the complex ML algorithms to provide perfect predictions for the treatment model which can violate the positivity assumption and elevate the variance of DR estimators. Thus the ML algorithms must be controlled to avoid perfect predictions for the treatment model while still learn the relationship between the confounders and the treatment and outcome. We use two Neural network architectures and investigate how their hyperparameters should be tuned in the presence of confounders and IVs to achieve a low bias-variance tradeoff for ATE estimators such as DR estimator. Through simulation results, we will provide recommendations as to how NNs can be employed for ATE estimation.