 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlending 3D Geometry and Machine Learning for Multi-View Stereopsis
May 06, 2025Traditional multi-view stereo (MVS) methods primarily depend on photometric and geometric consistency constraints. In contrast, modern learning-based algorithms often rely on the plane sweep algorithm to infer 3D geometry, applying explicit geometric consistency (GC) checks only as a post-processing step, with no impact on the learning process itself. In this work, we introduce GC MVSNet plus plus, a novel approach that actively enforces geometric consistency of reference view depth maps across multiple source views (multi view) and at various scales (multi scale) during the learning phase (see Fig. 1). This integrated GC check significantly accelerates the learning process by directly penalizing geometrically inconsistent pixels, effectively halving the number of training iterations compared to other MVS methods. Furthermore, we introduce a densely connected cost regularization network with two distinct block designs simple and feature dense optimized to harness dense feature connections for enhanced regularization. Extensive experiments demonstrate that our approach achieves a new state of the art on the DTU and BlendedMVS datasets and secures second place on the Tanks and Temples benchmark. To our knowledge, GC MVSNet plus plus is the first method to enforce multi-view, multi-scale supervised geometric consistency during learning. Our code is available.
GC-MVSNet: Multi-View, Multi-Scale, Geometrically-Consistent Multi-View Stereo
Oct 30, 2023Traditional multi-view stereo (MVS) methods rely heavily on photometric and geometric consistency constraints, but newer machine learning-based MVS methods check geometric consistency across multiple source views only as a post-processing step. In this paper, we present a novel approach that explicitly encourages geometric consistency of reference view depth maps across multiple source views at different scales during learning (see Fig. 1). We find that adding this geometric consistency loss significantly accelerates learning by explicitly penalizing geometrically inconsistent pixels, reducing the training iteration requirements to nearly half that of other MVS methods. Our extensive experiments show that our approach achieves a new state-of-the-art on the DTU and BlendedMVS datasets, and competitive results on the Tanks and Temples benchmark. To the best of our knowledge, GC-MVSNet is the first attempt to enforce multi-view, multi-scale geometric consistency during learning.
* Accepted in WACV 2024
Reinforcement Learning for Semantic Segmentation in Indoor Scenes
Jun 03, 2016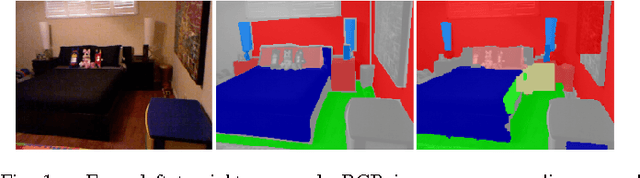

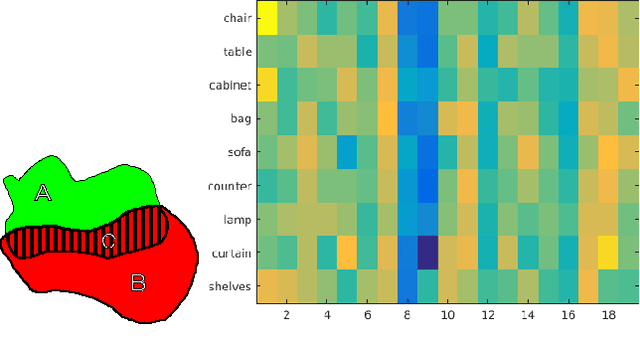

Future advancements in robot autonomy and sophistication of robotics tasks rest on robust, efficient, and task-dependent semantic understanding of the environment. Semantic segmentation is the problem of simultaneous segmentation and categorization of a partition of sensory data. The majority of current approaches tackle this using multi-class segmentation and labeling in a Conditional Random Field (CRF) framework or by generating multiple object hypotheses and combining them sequentially. In practical settings, the subset of semantic labels that are needed depend on the task and particular scene and labelling every single pixel is not always necessary. We pursue these observations in developing a more modular and flexible approach to multi-class parsing of RGBD data based on learning strategies for combining independent binary object-vs-background segmentations in place of the usual monolithic multi-label CRF approach. Parameters for the independent binary segmentation models can be learned very efficiently, and the combination strategy---learned using reinforcement learning---can be set independently and can vary over different tasks and environments. Accuracy is comparable to state-of-art methods on a subset of the NYU-V2 dataset of indoor scenes, while providing additional flexibility and modularity.