 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Data Integration
Mar 28, 2026Data comes in many forms. From a shallow perspective, they can be viewed as being either in structured (e.g., as a relation, as key-value pairs) or unstructured (e.g., text, image) formats. So far, machines have been fairly good at processing and reasoning over structured data that follows a precise schema. However, the heterogeneity of data poses a significant challenge on how well diverse categories of data can be meaningfully stored and processed. Data Integration, a crucial part of the data engineering pipeline, addresses this by combining disparate data sources and providing unified data access to end-users. Until now, most data integration systems have leaned on only combining structured data sources. Nevertheless, unstructured data (a.k.a. free text) also contains a plethora of knowledge waiting to be utilized. Thus, in this chapter, we firstly make the case for the integration of textual data, to later present its challenges, state of the art and open problems.
BN-AuthProf: Benchmarking Machine Learning for Bangla Author Profiling on Social Media Texts
Dec 03, 2024Author profiling, the analysis of texts to uncover attributes such as gender and age of the author, has become essential with the widespread use of social media platforms. This paper focuses on author profiling in the Bangla language, aiming to extract valuable insights about anonymous authors based on their writing style on social media. The primary objective is to introduce and benchmark the performance of machine learning approaches on a newly created Bangla Author Profiling dataset, BN-AuthProf. The dataset comprises 30,131 social media posts from 300 authors, labeled by their age and gender. Authors' identities and sensitive information were anonymized to ensure privacy. Various classical machine learning and deep learning techniques were employed to evaluate the dataset. For gender classification, the best accuracy achieved was 80% using Support Vector Machine (SVM), while a Multinomial Naive Bayes (MNB) classifier achieved the best F1 score of 0.756. For age classification, MNB attained a maximum accuracy score of 91% with an F1 score of 0.905. This research highlights the effectiveness of machine learning in gender and age classification for Bangla author profiling, with practical implications spanning marketing, security, forensic linguistics, education, and criminal investigations, considering privacy and biases.
N-gram Statistical Stemmer for Bangla Corpus
Dec 25, 2019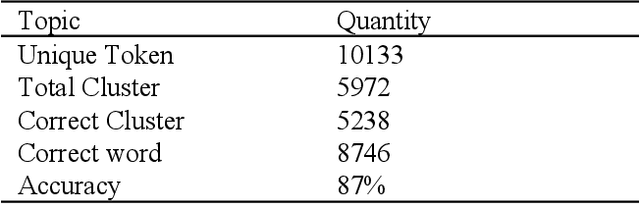
Stemming is a process that can be utilized to trim inflected words to stem or root form. It is useful for enhancing the retrieval effectiveness, especially for text search in order to solve the mismatch problems. Previous research on Bangla stemming mostly relied on eliminating multiple suffixes from a solitary word through a recursive rule based procedure to recover progressively applicable relative root. Our proposed system has enhanced the aforementioned exploration by actualizing one of the stemming algorithms called N-gram stemming. By utilizing an affiliation measure called dice coefficient, related sets of words are clustered depending on their character structure. The smallest word in one cluster may be considered as the stem. We additionally analyzed Affinity Propagation clustering algorithms with coefficient similarity as well as with median similarity. Our result indicates N-gram stemming techniques to be effective in general which gave us around 87% accurate clusters.