 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndian Masked Faces in the Wild Dataset
Jun 17, 2021
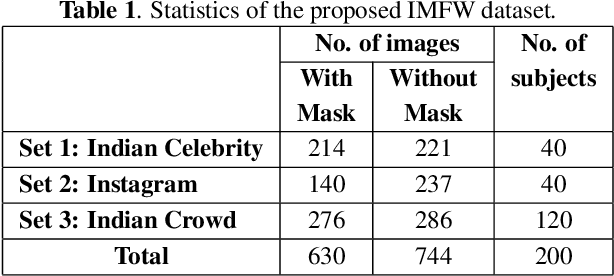
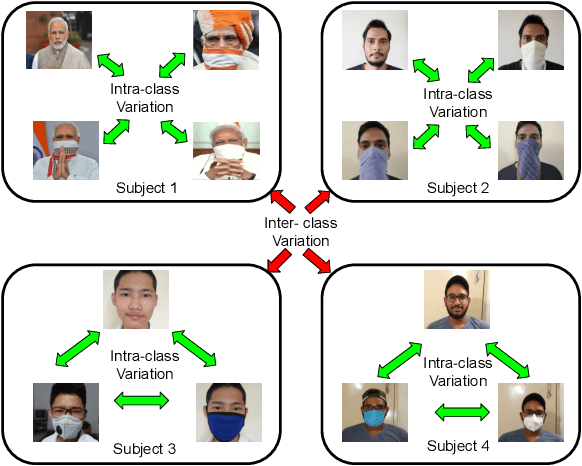
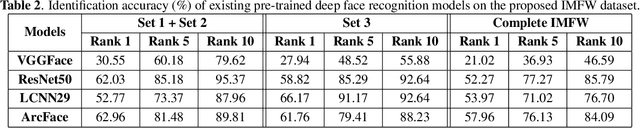
Due to the COVID-19 pandemic, wearing face masks has become a mandate in public places worldwide. Face masks occlude a significant portion of the facial region. Additionally, people wear different types of masks, from simple ones to ones with graphics and prints. These pose new challenges to face recognition algorithms. Researchers have recently proposed a few masked face datasets for designing algorithms to overcome the challenges of masked face recognition. However, existing datasets lack the cultural diversity and collection in the unrestricted settings. Country like India with attire diversity, people are not limited to wearing traditional masks but also clothing like a thin cotton printed towel (locally called as ``gamcha''), ``stoles'', and ``handkerchiefs'' to cover their faces. In this paper, we present a novel \textbf{Indian Masked Faces in the Wild (IMFW)} dataset which contains images with variations in pose, illumination, resolution, and the variety of masks worn by the subjects. We have also benchmarked the performance of existing face recognition models on the proposed IMFW dataset. Experimental results demonstrate the limitations of existing algorithms in presence of diverse conditions.
Enhancing Fine-Grained Classification for Low Resolution Images
May 01, 2021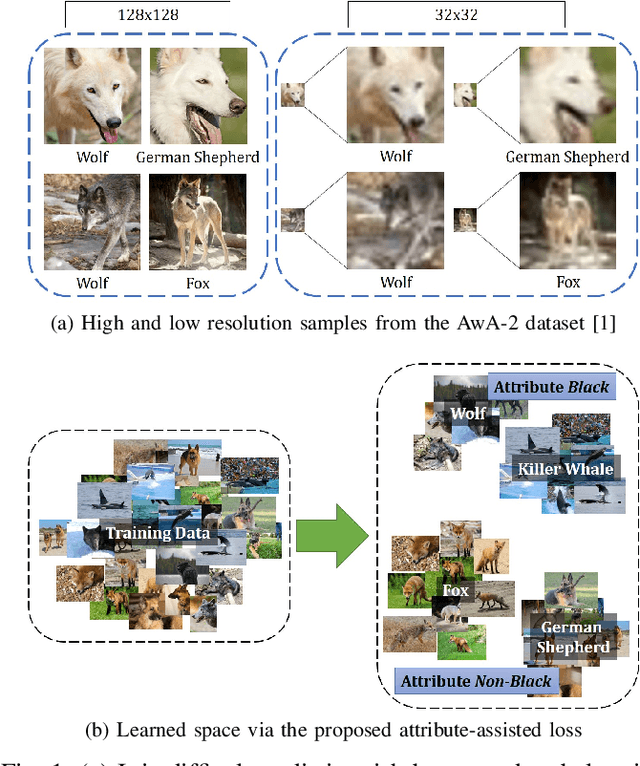
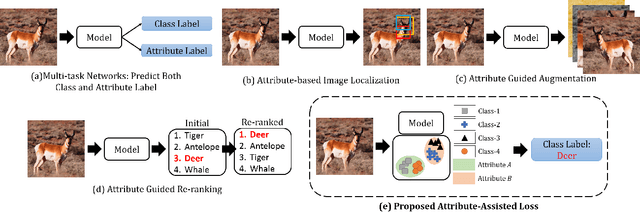

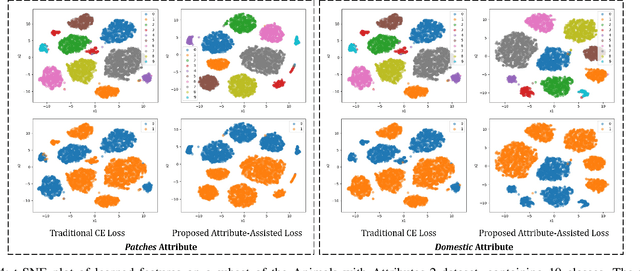
Low resolution fine-grained classification has widespread applicability for applications where data is captured at a distance such as surveillance and mobile photography. While fine-grained classification with high resolution images has received significant attention, limited attention has been given to low resolution images. These images suffer from the inherent challenge of limited information content and the absence of fine details useful for sub-category classification. This results in low inter-class variations across samples of visually similar classes. In order to address these challenges, this research proposes a novel attribute-assisted loss, which utilizes ancillary information to learn discriminative features for classification. The proposed loss function enables a model to learn class-specific discriminative features, while incorporating attribute-level separability. Evaluation is performed on multiple datasets with different models, for four resolutions varying from 32x32 to 224x224. Different experiments demonstrate the efficacy of the proposed attributeassisted loss for low resolution fine-grained classification.
Class Equilibrium using Coulomb's Law
Apr 25, 2021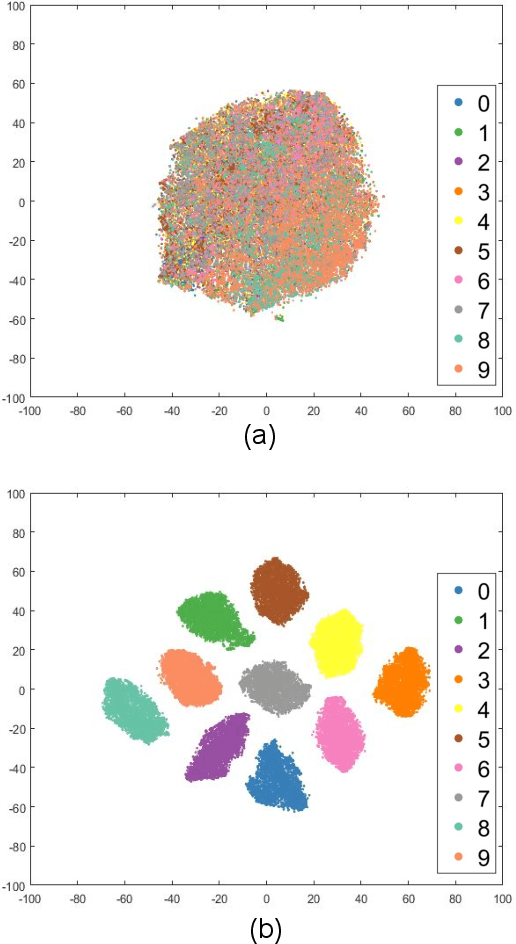
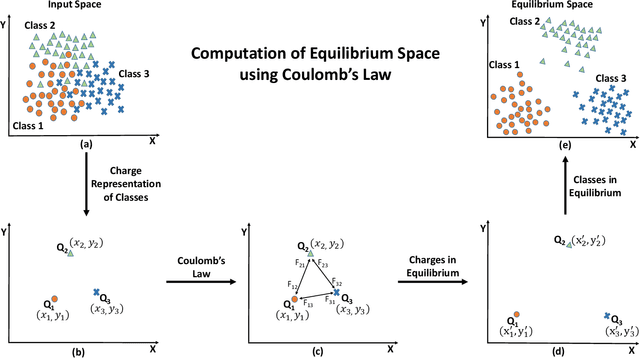
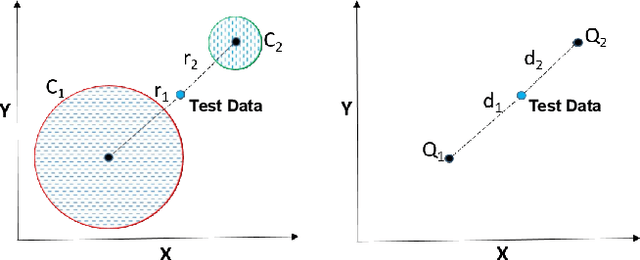
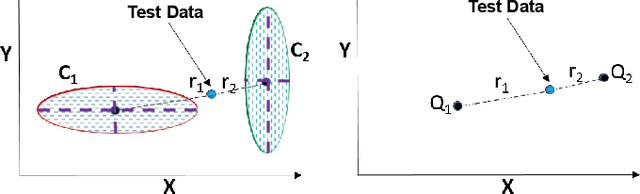
Projection algorithms learn a transformation function to project the data from input space to the feature space, with the objective of increasing the inter-class distance. However, increasing the inter-class distance can affect the intra-class distance. Maintaining an optimal inter-class separation among the classes without affecting the intra-class distance of the data distribution is a challenging task. In this paper, inspired by the Coulomb's law of Electrostatics, we propose a new algorithm to compute the equilibrium space of any data distribution where the separation among the classes is optimal. The algorithm further learns the transformation between the input space and equilibrium space to perform classification in the equilibrium space. The performance of the proposed algorithm is evaluated on four publicly available datasets at three different resolutions. It is observed that the proposed algorithm performs well for low-resolution images.
Age Gap Reducer-GAN for Recognizing Age-Separated Faces
Nov 11, 2020
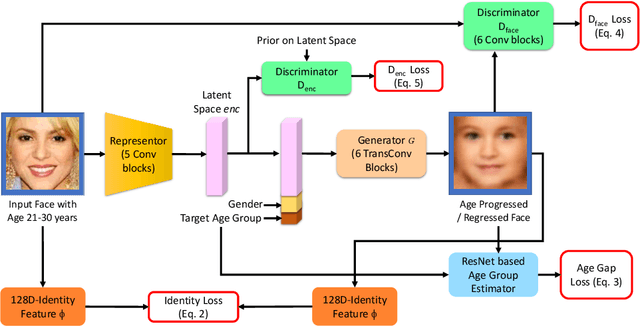

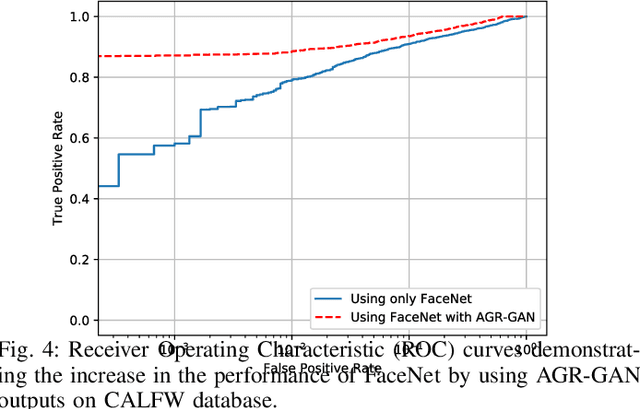
In this paper, we propose a novel algorithm for matching faces with temporal variations caused due to age progression. The proposed generative adversarial network algorithm is a unified framework that combines facial age estimation and age-separated face verification. The key idea of this approach is to learn the age variations across time by conditioning the input image on the subject's gender and the target age group to which the face needs to be progressed. The loss function accounts for reducing the age gap between the original image and generated face image as well as preserving the identity. Both visual fidelity and quantitative evaluations demonstrate the efficacy of the proposed architecture on different facial age databases for age-separated face recognition.
Trustworthy AI
Nov 02, 2020
Modern AI systems are reaping the advantage of novel learning methods. With their increasing usage, we are realizing the limitations and shortfalls of these systems. Brittleness to minor adversarial changes in the input data, ability to explain the decisions, address the bias in their training data, high opacity in terms of revealing the lineage of the system, how they were trained and tested, and under which parameters and conditions they can reliably guarantee a certain level of performance, are some of the most prominent limitations. Ensuring the privacy and security of the data, assigning appropriate credits to data sources, and delivering decent outputs are also required features of an AI system. We propose the tutorial on Trustworthy AI to address six critical issues in enhancing user and public trust in AI systems, namely: (i) bias and fairness, (ii) explainability, (iii) robust mitigation of adversarial attacks, (iv) improved privacy and security in model building, (v) being decent, and (vi) model attribution, including the right level of credit assignment to the data sources, model architectures, and transparency in lineage.
WaveTransform: Crafting Adversarial Examples via Input Decomposition
Oct 29, 2020
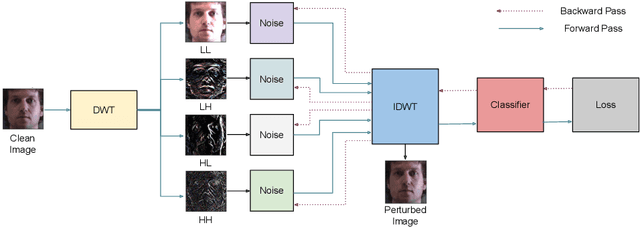
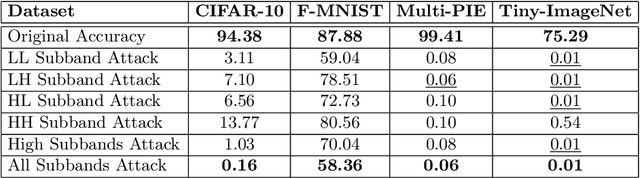
Frequency spectrum has played a significant role in learning unique and discriminating features for object recognition. Both low and high frequency information present in images have been extracted and learnt by a host of representation learning techniques, including deep learning. Inspired by this observation, we introduce a novel class of adversarial attacks, namely `WaveTransform', that creates adversarial noise corresponding to low-frequency and high-frequency subbands, separately (or in combination). The frequency subbands are analyzed using wavelet decomposition; the subbands are corrupted and then used to construct an adversarial example. Experiments are performed using multiple databases and CNN models to establish the effectiveness of the proposed WaveTransform attack and analyze the importance of a particular frequency component. The robustness of the proposed attack is also evaluated through its transferability and resiliency against a recent adversarial defense algorithm. Experiments show that the proposed attack is effective against the defense algorithm and is also transferable across CNNs.
Attack Agnostic Adversarial Defense via Visual Imperceptible Bound
Oct 25, 2020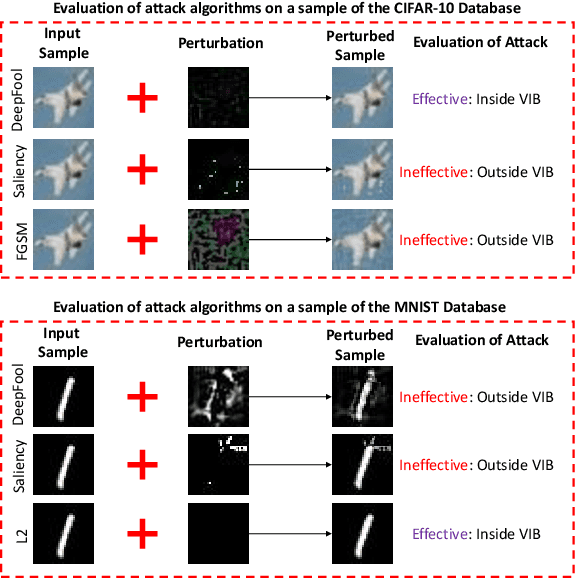
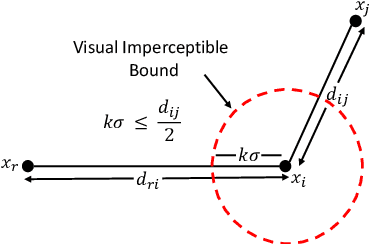
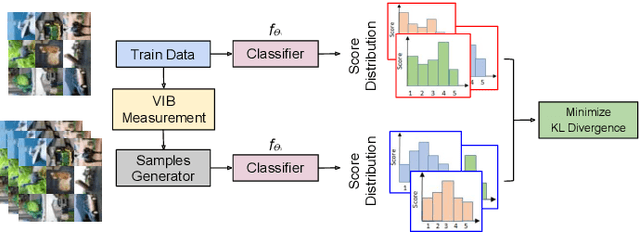
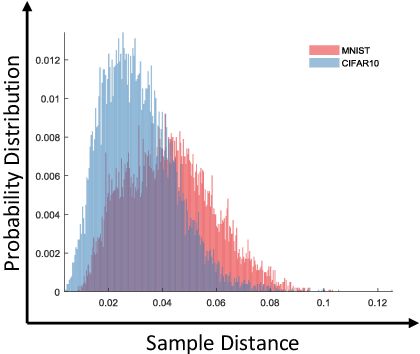
The high susceptibility of deep learning algorithms against structured and unstructured perturbations has motivated the development of efficient adversarial defense algorithms. However, the lack of generalizability of existing defense algorithms and the high variability in the performance of the attack algorithms for different databases raises several questions on the effectiveness of the defense algorithms. In this research, we aim to design a defense model that is robust within a certain bound against both seen and unseen adversarial attacks. This bound is related to the visual appearance of an image, and we termed it as \textit{Visual Imperceptible Bound (VIB)}. To compute this bound, we propose a novel method that uses the database characteristics. The VIB is further used to measure the effectiveness of attack algorithms. The performance of the proposed defense model is evaluated on the MNIST, CIFAR-10, and Tiny ImageNet databases on multiple attacks that include C\&W ($l_2$) and DeepFool. The proposed defense model is not only able to increase the robustness against several attacks but also retain or improve the classification accuracy on an original clean test set. The proposed algorithm is attack agnostic, i.e. it does not require any knowledge of the attack algorithm.
MixNet for Generalized Face Presentation Attack Detection
Oct 25, 2020
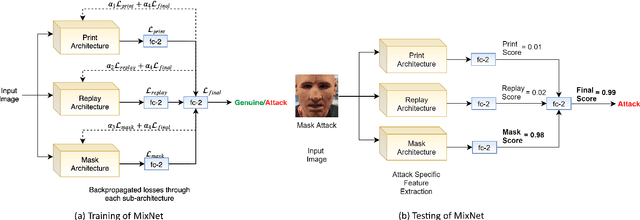

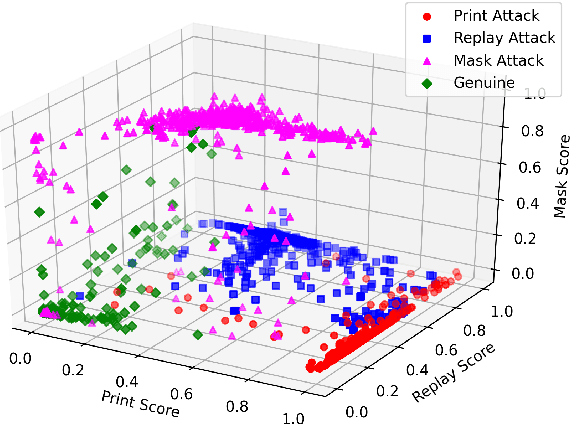
The non-intrusive nature and high accuracy of face recognition algorithms have led to their successful deployment across multiple applications ranging from border access to mobile unlocking and digital payments. However, their vulnerability against sophisticated and cost-effective presentation attack mediums raises essential questions regarding its reliability. In the literature, several presentation attack detection algorithms are presented; however, they are still far behind from reality. The major problem with existing work is the generalizability against multiple attacks both in the seen and unseen setting. The algorithms which are useful for one kind of attack (such as print) perform unsatisfactorily for another type of attack (such as silicone masks). In this research, we have proposed a deep learning-based network termed as \textit{MixNet} to detect presentation attacks in cross-database and unseen attack settings. The proposed algorithm utilizes state-of-the-art convolutional neural network architectures and learns the feature mapping for each attack category. Experiments are performed using multiple challenging face presentation attack databases such as SMAD and Spoof In the Wild (SiW-M) databases. Extensive experiments and comparison with existing state of the art algorithms show the effectiveness of the proposed algorithm.
Generalized Iris Presentation Attack Detection Algorithm under Cross-Database Settings
Oct 25, 2020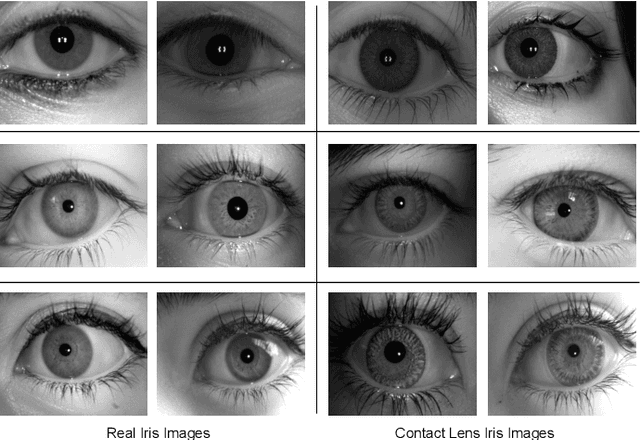

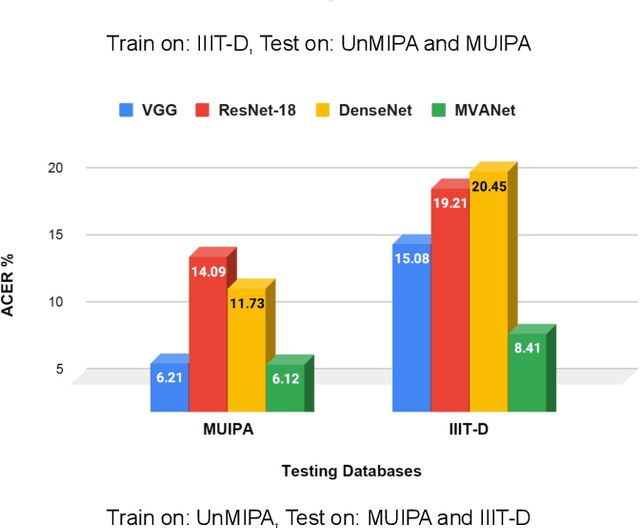

Presentation attacks are posing major challenges to most of the biometric modalities. Iris recognition, which is considered as one of the most accurate biometric modality for person identification, has also been shown to be vulnerable to advanced presentation attacks such as 3D contact lenses and textured lens. While in the literature, several presentation attack detection (PAD) algorithms are presented; a significant limitation is the generalizability against an unseen database, unseen sensor, and different imaging environment. To address this challenge, we propose a generalized deep learning-based PAD network, MVANet, which utilizes multiple representation layers. It is inspired by the simplicity and success of hybrid algorithm or fusion of multiple detection networks. The computational complexity is an essential factor in training deep neural networks; therefore, to reduce the computational complexity while learning multiple feature representation layers, a fixed base model has been used. The performance of the proposed network is demonstrated on multiple databases such as IIITD-WVU MUIPA and IIITD-CLI databases under cross-database training-testing settings, to assess the generalizability of the proposed algorithm.
Unravelling Small Sample Size Problems in the Deep Learning World
Aug 08, 2020



The growth and success of deep learning approaches can be attributed to two major factors: availability of hardware resources and availability of large number of training samples. For problems with large training databases, deep learning models have achieved superlative performances. However, there are a lot of \textit{small sample size or $S^3$} problems for which it is not feasible to collect large training databases. It has been observed that deep learning models do not generalize well on $S^3$ problems and specialized solutions are required. In this paper, we first present a review of deep learning algorithms for small sample size problems in which the algorithms are segregated according to the space in which they operate, i.e. input space, model space, and feature space. Secondly, we present Dynamic Attention Pooling approach which focuses on extracting global information from the most discriminative sub-part of the feature map. The performance of the proposed dynamic attention pooling is analyzed with state-of-the-art ResNet model on relatively small publicly available datasets such as SVHN, C10, C100, and TinyImageNet.