 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Compression for Deep Learning
Nov 06, 2017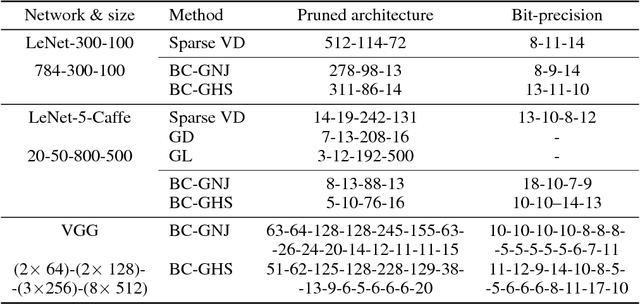

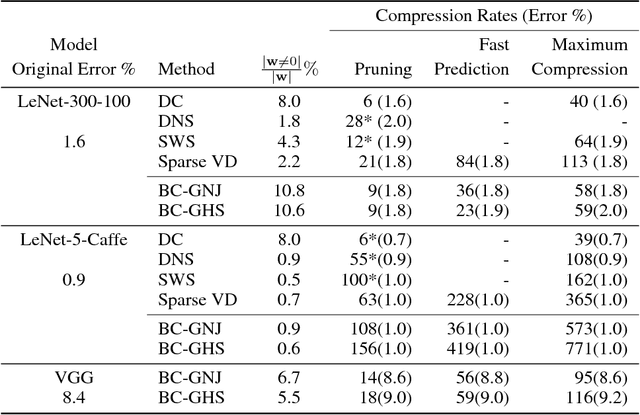
Compression and computational efficiency in deep learning have become a problem of great significance. In this work, we argue that the most principled and effective way to attack this problem is by adopting a Bayesian point of view, where through sparsity inducing priors we prune large parts of the network. We introduce two novelties in this paper: 1) we use hierarchical priors to prune nodes instead of individual weights, and 2) we use the posterior uncertainties to determine the optimal fixed point precision to encode the weights. Both factors significantly contribute to achieving the state of the art in terms of compression rates, while still staying competitive with methods designed to optimize for speed or energy efficiency.
Modeling Relational Data with Graph Convolutional Networks
Oct 26, 2017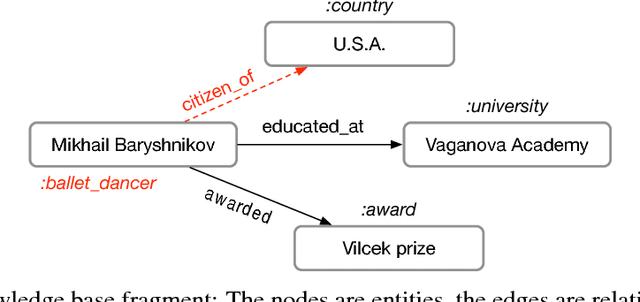


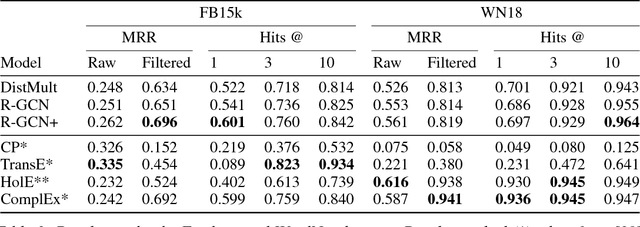
Knowledge graphs enable a wide variety of applications, including question answering and information retrieval. Despite the great effort invested in their creation and maintenance, even the largest (e.g., Yago, DBPedia or Wikidata) remain incomplete. We introduce Relational Graph Convolutional Networks (R-GCNs) and apply them to two standard knowledge base completion tasks: Link prediction (recovery of missing facts, i.e. subject-predicate-object triples) and entity classification (recovery of missing entity attributes). R-GCNs are related to a recent class of neural networks operating on graphs, and are developed specifically to deal with the highly multi-relational data characteristic of realistic knowledge bases. We demonstrate the effectiveness of R-GCNs as a stand-alone model for entity classification. We further show that factorization models for link prediction such as DistMult can be significantly improved by enriching them with an encoder model to accumulate evidence over multiple inference steps in the relational graph, demonstrating a large improvement of 29.8% on FB15k-237 over a decoder-only baseline.
Graph Convolutional Matrix Completion
Oct 25, 2017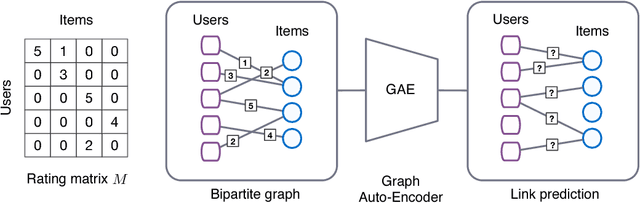
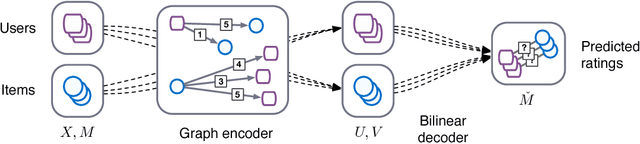
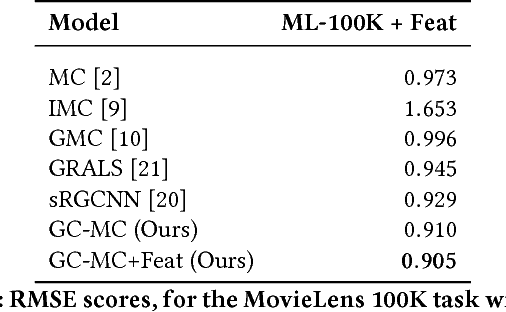
We consider matrix completion for recommender systems from the point of view of link prediction on graphs. Interaction data such as movie ratings can be represented by a bipartite user-item graph with labeled edges denoting observed ratings. Building on recent progress in deep learning on graph-structured data, we propose a graph auto-encoder framework based on differentiable message passing on the bipartite interaction graph. Our model shows competitive performance on standard collaborative filtering benchmarks. In settings where complimentary feature information or structured data such as a social network is available, our framework outperforms recent state-of-the-art methods.
Convolutional Networks for Spherical Signals
Sep 15, 2017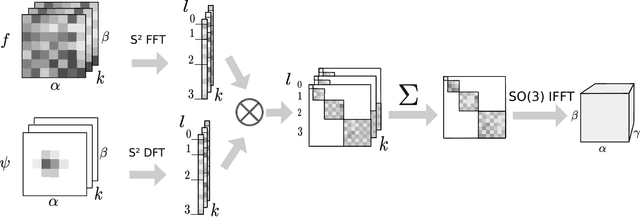
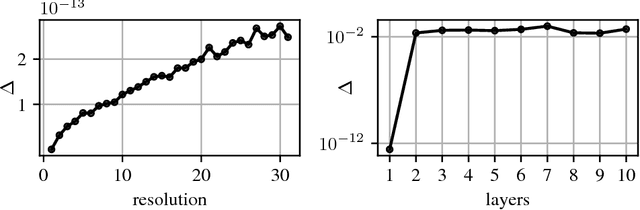
The success of convolutional networks in learning problems involving planar signals such as images is due to their ability to exploit the translation symmetry of the data distribution through weight sharing. Many areas of science and egineering deal with signals with other symmetries, such as rotation invariant data on the sphere. Examples include climate and weather science, astrophysics, and chemistry. In this paper we present spherical convolutional networks. These networks use convolutions on the sphere and rotation group, which results in rotational weight sharing and rotation equivariance. Using a synthetic spherical MNIST dataset, we show that spherical convolutional networks are very effective at dealing with rotationally invariant classification problems.
The Variational Fair Autoencoder
Aug 10, 2017
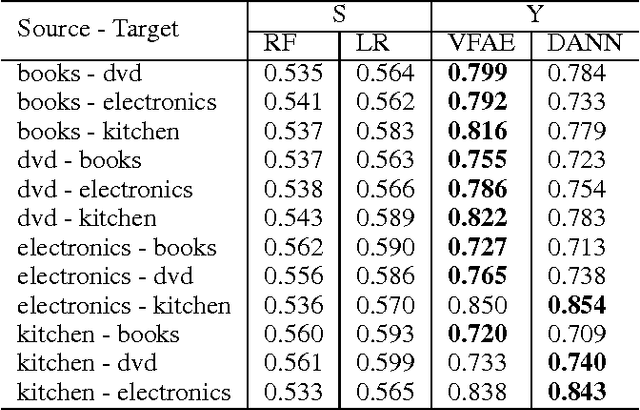
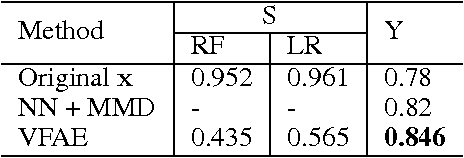
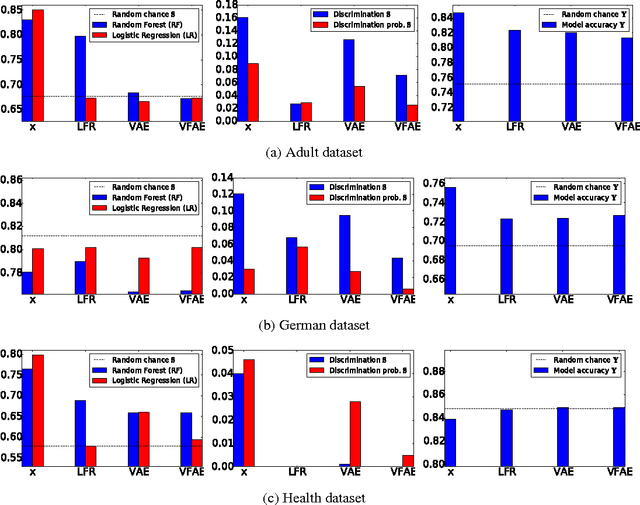
We investigate the problem of learning representations that are invariant to certain nuisance or sensitive factors of variation in the data while retaining as much of the remaining information as possible. Our model is based on a variational autoencoding architecture with priors that encourage independence between sensitive and latent factors of variation. Any subsequent processing, such as classification, can then be performed on this purged latent representation. To remove any remaining dependencies we incorporate an additional penalty term based on the "Maximum Mean Discrepancy" (MMD) measure. We discuss how these architectures can be efficiently trained on data and show in experiments that this method is more effective than previous work in removing unwanted sources of variation while maintaining informative latent representations.
Improving Variational Auto-Encoders using convex combination linear Inverse Autoregressive Flow
Jun 14, 2017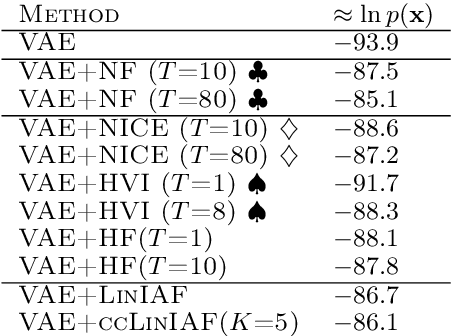

In this paper, we propose a new volume-preserving flow and show that it performs similarly to the linear general normalizing flow. The idea is to enrich a linear Inverse Autoregressive Flow by introducing multiple lower-triangular matrices with ones on the diagonal and combining them using a convex combination. In the experimental studies on MNIST and Histopathology data we show that the proposed approach outperforms other volume-preserving flows and is competitive with current state-of-the-art linear normalizing flow.
Temporally Efficient Deep Learning with Spikes
Jun 13, 2017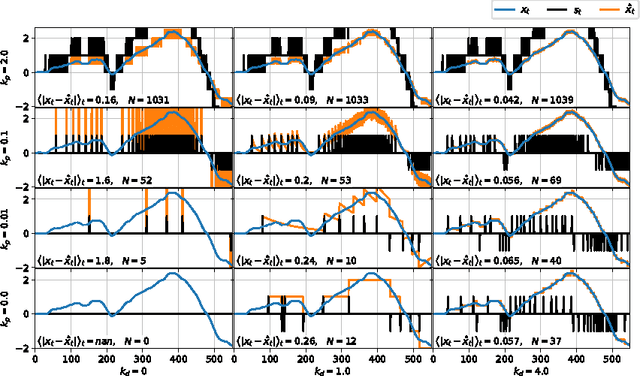
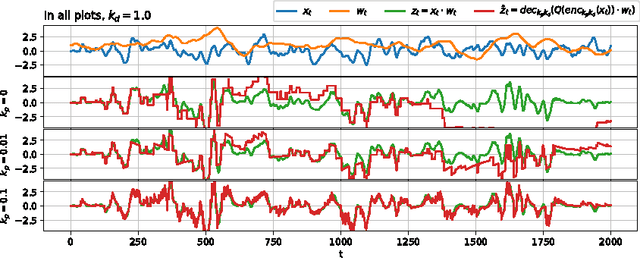
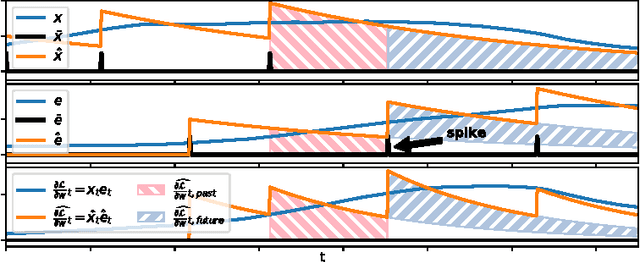
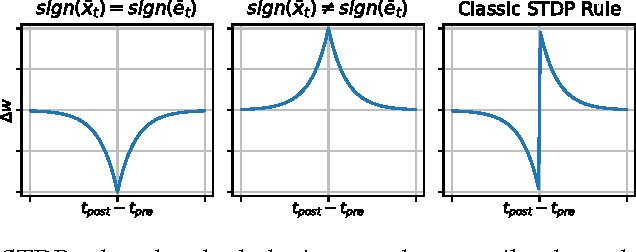
The vast majority of natural sensory data is temporally redundant. Video frames or audio samples which are sampled at nearby points in time tend to have similar values. Typically, deep learning algorithms take no advantage of this redundancy to reduce computation. This can be an obscene waste of energy. We present a variant on backpropagation for neural networks in which computation scales with the rate of change of the data - not the rate at which we process the data. We do this by having neurons communicate a combination of their state, and their temporal change in state. Intriguingly, this simple communication rule give rise to units that resemble biologically-inspired leaky integrate-and-fire neurons, and to a weight-update rule that is equivalent to a form of Spike-Timing Dependent Plasticity (STDP), a synaptic learning rule observed in the brain. We demonstrate that on MNIST and a temporal variant of MNIST, our algorithm performs about as well as a Multilayer Perceptron trained with backpropagation, despite only communicating discrete values between layers.
Recurrent Inference Machines for Solving Inverse Problems
Jun 13, 2017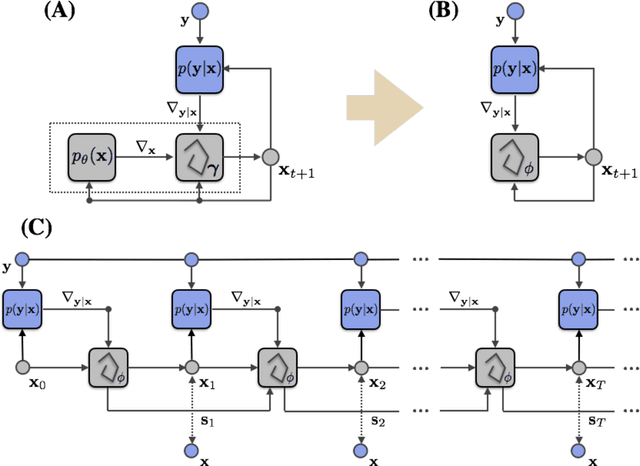
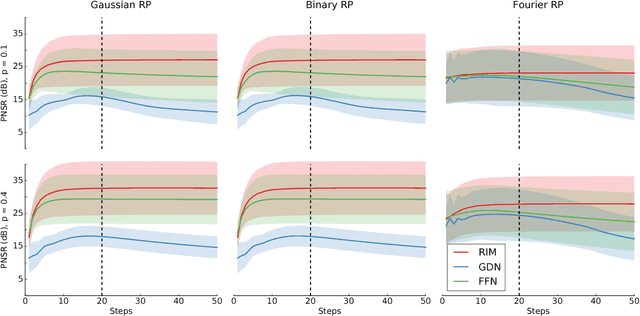
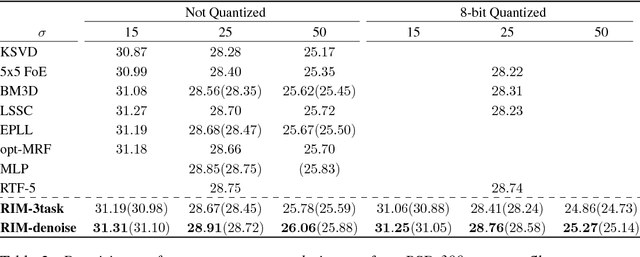

Much of the recent research on solving iterative inference problems focuses on moving away from hand-chosen inference algorithms and towards learned inference. In the latter, the inference process is unrolled in time and interpreted as a recurrent neural network (RNN) which allows for joint learning of model and inference parameters with back-propagation through time. In this framework, the RNN architecture is directly derived from a hand-chosen inference algorithm, effectively limiting its capabilities. We propose a learning framework, called Recurrent Inference Machines (RIM), in which we turn algorithm construction the other way round: Given data and a task, train an RNN to learn an inference algorithm. Because RNNs are Turing complete [1, 2] they are capable to implement any inference algorithm. The framework allows for an abstraction which removes the need for domain knowledge. We demonstrate in several image restoration experiments that this abstraction is effective, allowing us to achieve state-of-the-art performance on image denoising and super-resolution tasks and superior across-task generalization.
Multiplicative Normalizing Flows for Variational Bayesian Neural Networks
Jun 12, 2017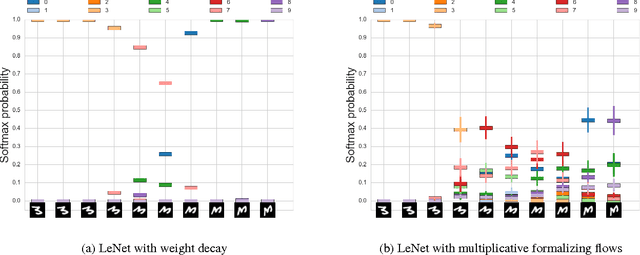
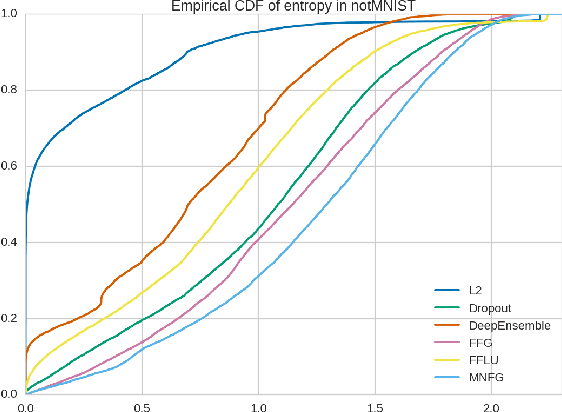
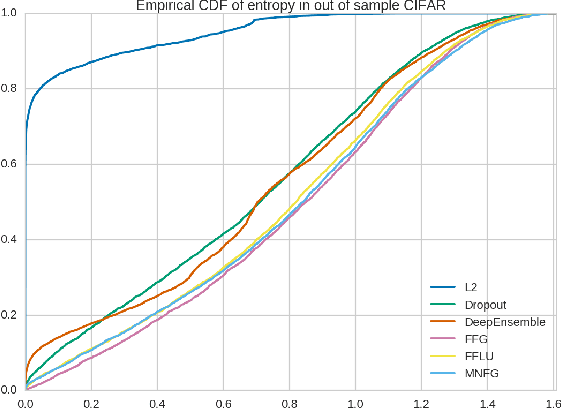
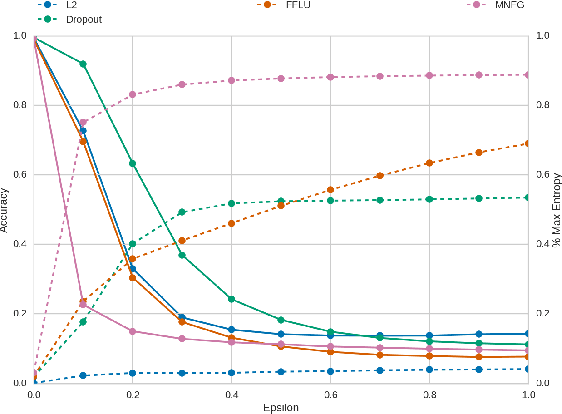
We reinterpret multiplicative noise in neural networks as auxiliary random variables that augment the approximate posterior in a variational setting for Bayesian neural networks. We show that through this interpretation it is both efficient and straightforward to improve the approximation by employing normalizing flows while still allowing for local reparametrizations and a tractable lower bound. In experiments we show that with this new approximation we can significantly improve upon classical mean field for Bayesian neural networks on both predictive accuracy as well as predictive uncertainty.
A New Method to Visualize Deep Neural Networks
Jun 12, 2017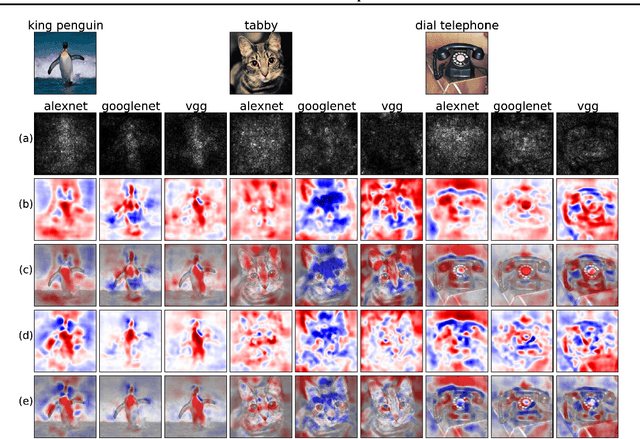


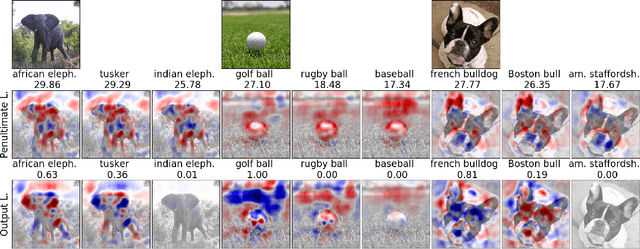
We present a method for visualising the response of a deep neural network to a specific input. For image data for instance our method will highlight areas that provide evidence in favor of, and against choosing a certain class. The method overcomes several shortcomings of previous methods and provides great additional insight into the decision making process of convolutional networks, which is important both to improve models and to accelerate the adoption of such methods in e.g. medicine. In experiments on ImageNet data, we illustrate how the method works and can be applied in different ways to understand deep neural nets.