 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple and Accurate Uncertainty Quantification from Bias-Variance Decomposition
Feb 13, 2020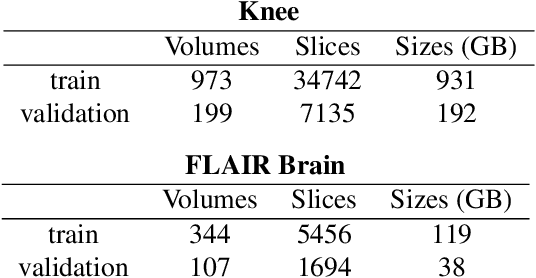
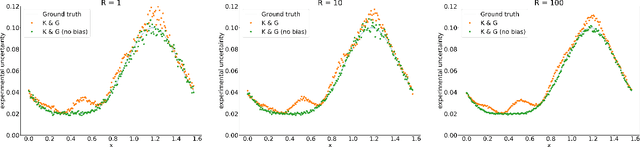
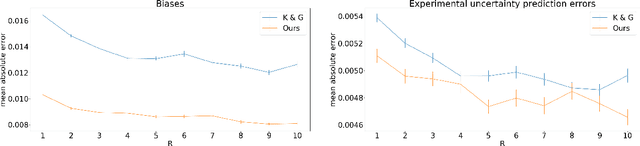
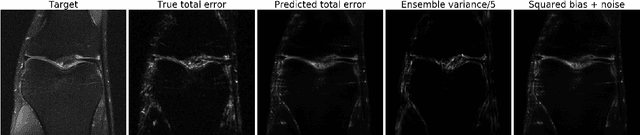
Accurate uncertainty quantification is crucial for many applications where decisions are in play. Examples include medical diagnosis and self-driving vehicles. We propose a new method that is based directly on the bias-variance decomposition, where the parameter uncertainty is given by the variance of an ensemble divided by the number of members in the ensemble, and the aleatoric uncertainty plus the squared bias is estimated by training a separate model that is regressed directly on the errors of the predictor. We demonstrate that this simple sequential procedure provides much more accurate uncertainty estimates than the current state-of-the-art on two MRI reconstruction tasks.
Contrastive Learning of Structured World Models
Jan 05, 2020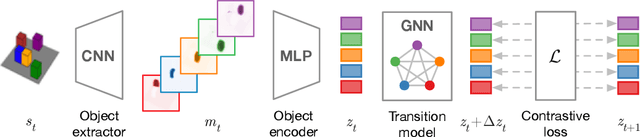
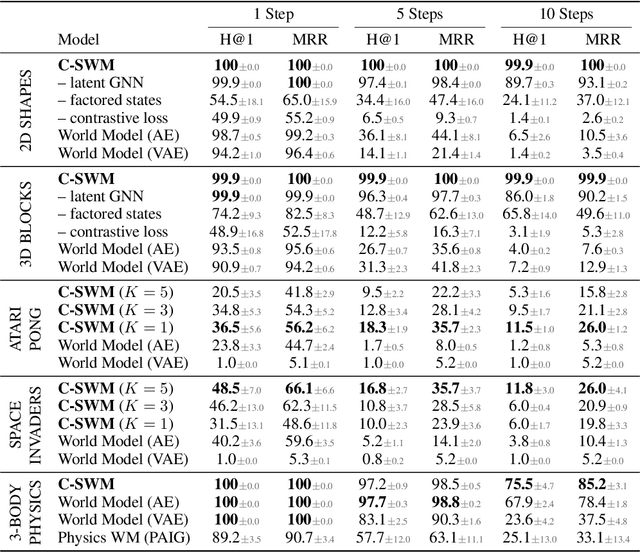
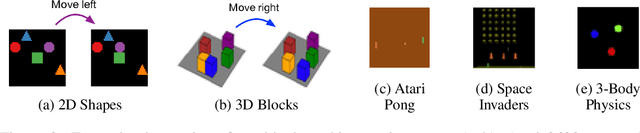

A structured understanding of our world in terms of objects, relations, and hierarchies is an important component of human cognition. Learning such a structured world model from raw sensory data remains a challenge. As a step towards this goal, we introduce Contrastively-trained Structured World Models (C-SWMs). C-SWMs utilize a contrastive approach for representation learning in environments with compositional structure. We structure each state embedding as a set of object representations and their relations, modeled by a graph neural network. This allows objects to be discovered from raw pixel observations without direct supervision as part of the learning process. We evaluate C-SWMs on compositional environments involving multiple interacting objects that can be manipulated independently by an agent, simple Atari games, and a multi-object physics simulation. Our experiments demonstrate that C-SWMs can overcome limitations of models based on pixel reconstruction and outperform typical representatives of this model class in highly structured environments, while learning interpretable object-based representations.
Taxonomy and Evaluation of Structured Compression of Convolutional Neural Networks
Dec 20, 2019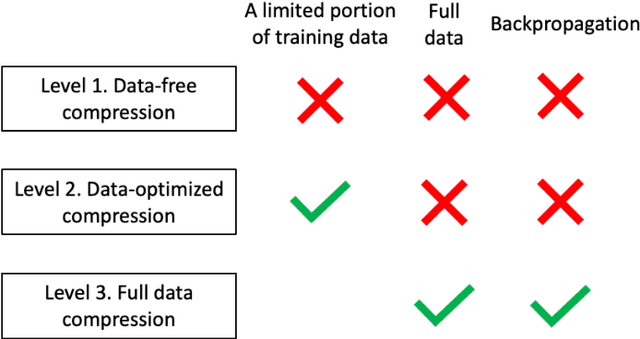
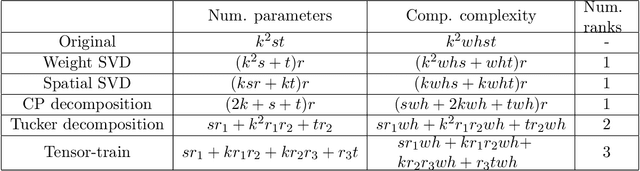

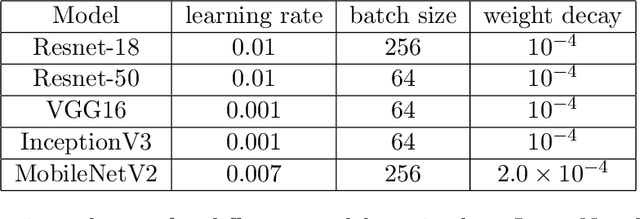
The success of deep neural networks in many real-world applications is leading to new challenges in building more efficient architectures. One effective way of making networks more efficient is neural network compression. We provide an overview of existing neural network compression methods that can be used to make neural networks more efficient by changing the architecture of the network. First, we introduce a new way to categorize all published compression methods, based on the amount of data and compute needed to make the methods work in practice. These are three 'levels of compression solutions'. Second, we provide a taxonomy of tensor factorization based and probabilistic compression methods. Finally, we perform an extensive evaluation of different compression techniques from the literature for models trained on ImageNet. We show that SVD and probabilistic compression or pruning methods are complementary and give the best results of all the considered methods. We also provide practical ways to combine them.
Learning Likelihoods with Conditional Normalizing Flows
Nov 29, 2019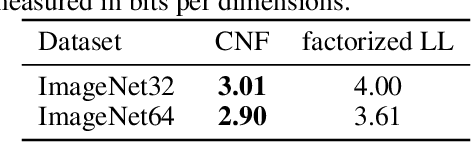

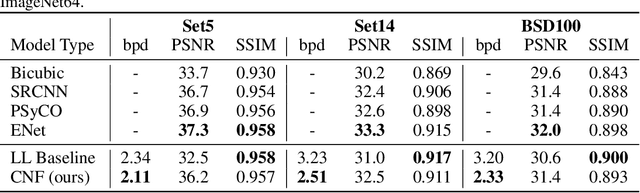
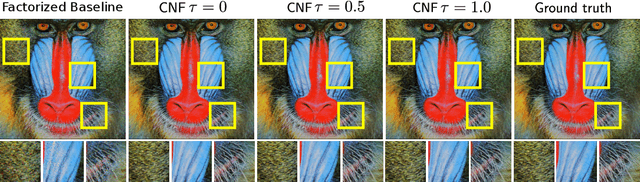
Normalizing Flows (NFs) are able to model complicated distributions p(y) with strong inter-dimensional correlations and high multimodality by transforming a simple base density p(z) through an invertible neural network under the change of variables formula. Such behavior is desirable in multivariate structured prediction tasks, where handcrafted per-pixel loss-based methods inadequately capture strong correlations between output dimensions. We present a study of conditional normalizing flows (CNFs), a class of NFs where the base density to output space mapping is conditioned on an input x, to model conditional densities p(y|x). CNFs are efficient in sampling and inference, they can be trained with a likelihood-based objective, and CNFs, being generative flows, do not suffer from mode collapse or training instabilities. We provide an effective method to train continuous CNFs for binary problems and in particular, we apply these CNFs to super-resolution and vessel segmentation tasks demonstrating competitive performance on standard benchmark datasets in terms of likelihood and conventional metrics.
Invert to Learn to Invert
Nov 25, 2019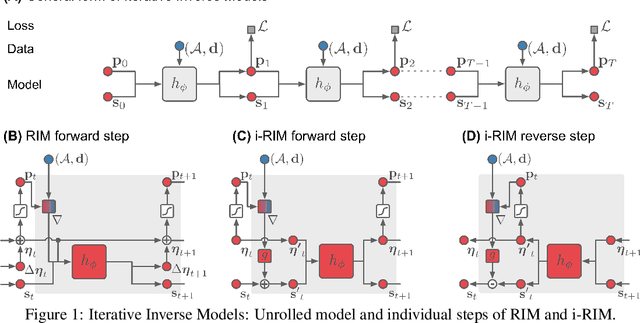
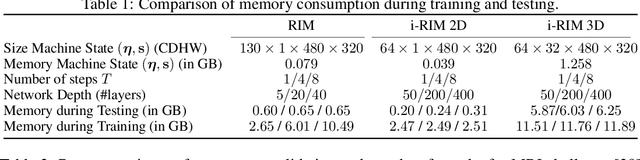
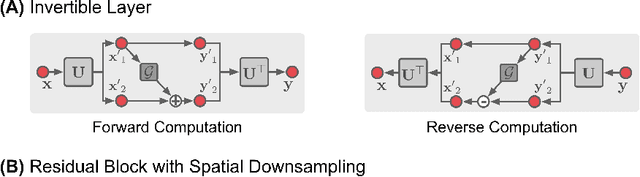
Iterative learning to infer approaches have become popular solvers for inverse problems. However, their memory requirements during training grow linearly with model depth, limiting in practice model expressiveness. In this work, we propose an iterative inverse model with constant memory that relies on invertible networks to avoid storing intermediate activations. As a result, the proposed approach allows us to train models with 400 layers on 3D volumes in an MRI image reconstruction task. In experiments on a public data set, we demonstrate that these deeper, and thus more expressive, networks perform state-of-the-art image reconstruction.
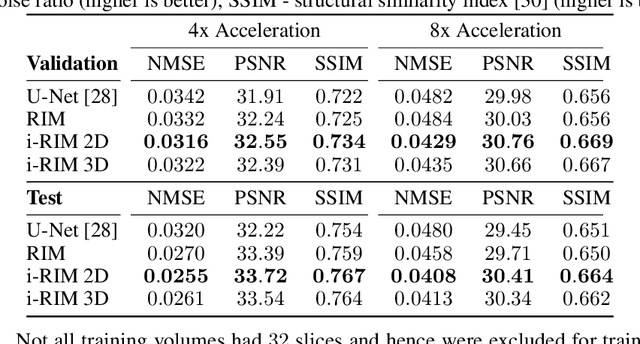
i-RIM applied to the fastMRI challenge
Oct 20, 2019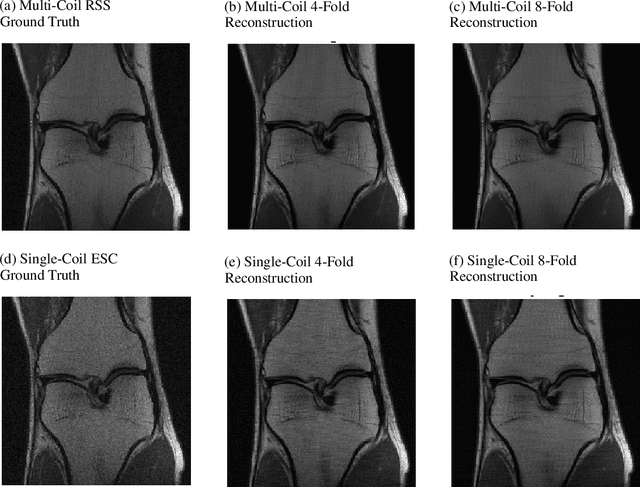
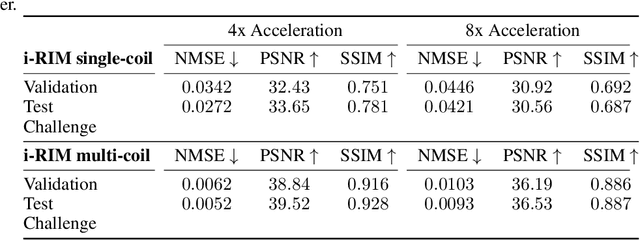
We, team AImsterdam, summarize our submission to the fastMRI challenge (Zbontar et al., 2018). Our approach builds on recent advances in invertible learning to infer models as presented in Putzky and Welling (2019). Both, our single-coil and our multi-coil model share the same basic architecture.
DP-MAC: The Differentially Private Method of Auxiliary Coordinates for Deep Learning
Oct 15, 2019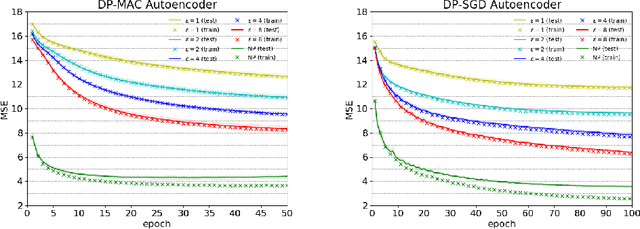
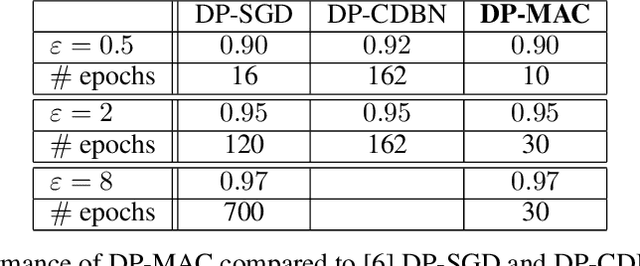
Developing a differentially private deep learning algorithm is challenging, due to the difficulty in analyzing the sensitivity of objective functions that are typically used to train deep neural networks. Many existing methods resort to the stochastic gradient descent algorithm and apply a pre-defined sensitivity to the gradients for privatizing weights. However, their slow convergence typically yields a high cumulative privacy loss. Here, we take a different route by employing the method of auxiliary coordinates, which allows us to independently update the weights per layer by optimizing a per-layer objective function. This objective function can be well approximated by a low-order Taylor's expansion, in which sensitivity analysis becomes tractable. We perturb the coefficients of the expansion for privacy, which we optimize using more advanced optimization routines than SGD for faster convergence. We empirically show that our algorithm provides a decent trained model quality under a modest privacy budget.
An Introduction to Variational Autoencoders
Jul 24, 2019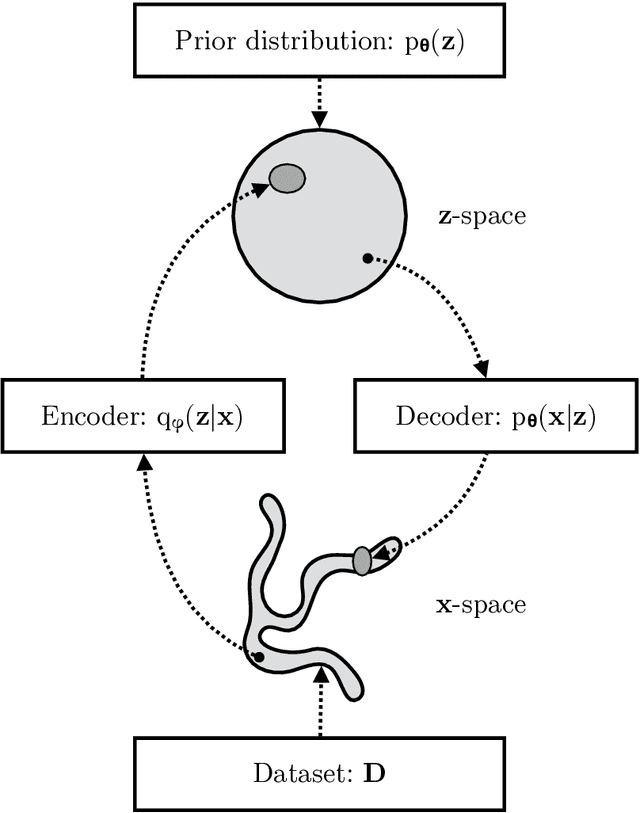
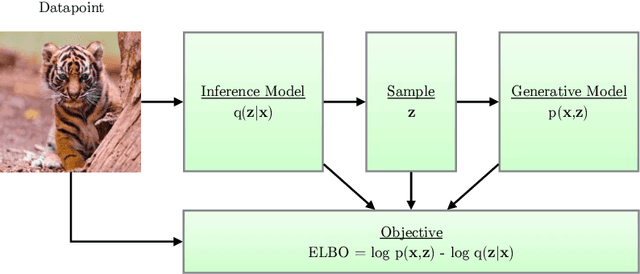
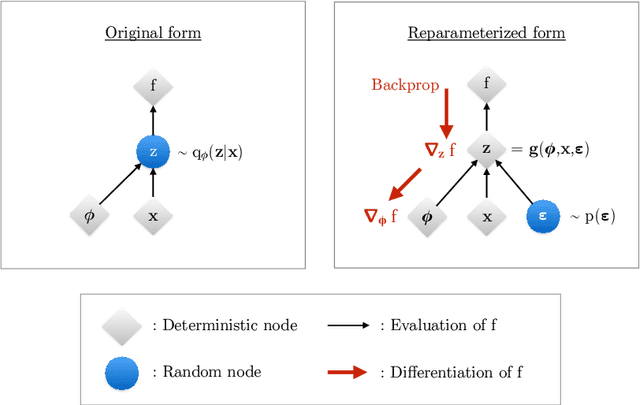
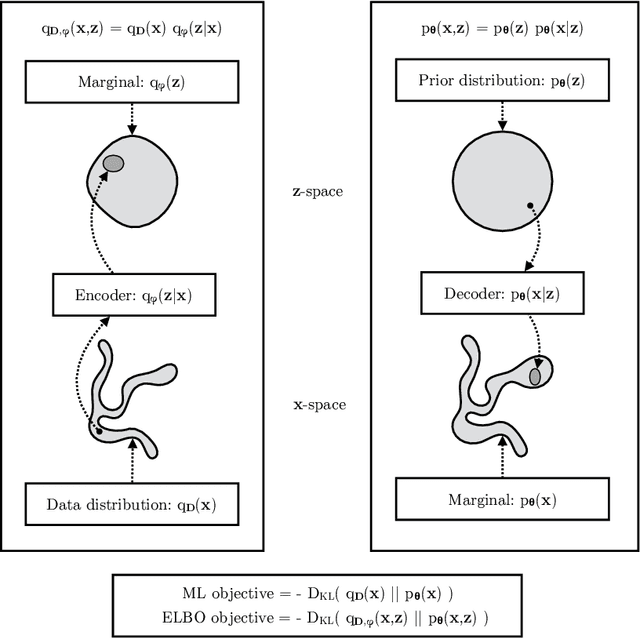
Variational autoencoders provide a principled framework for learning deep latent-variable models and corresponding inference models. In this work, we provide an introduction to variational autoencoders and some important extensions.
Relational Generalized Few-Shot Learning
Jul 22, 2019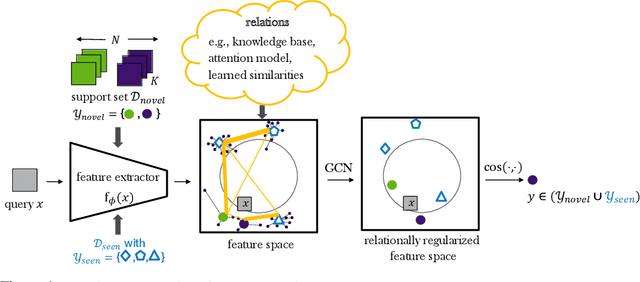
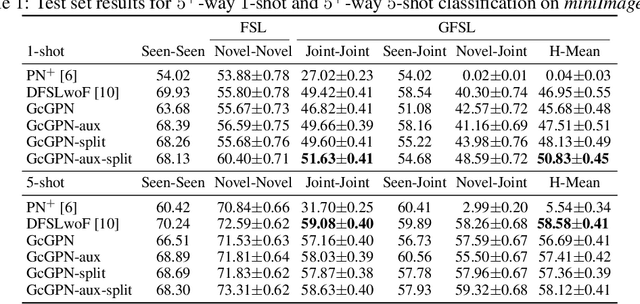
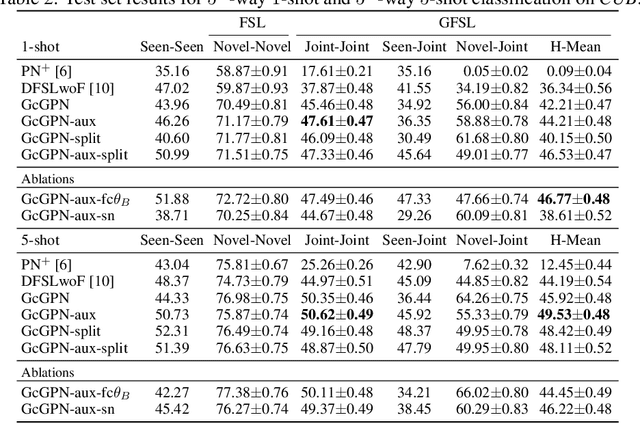
Transferring learned models to novel tasks is a challenging problem, particularly if only very few labeled examples are available. Although this few-shot learning setup has received a lot of attention recently, most proposed methods focus on discriminating novel classes only. Instead, we consider the extended setup of generalized few-shot learning (GFSL), where the model is required to perform classification on the joint label space consisting of both previously seen and novel classes. We propose a graph-based framework that explicitly models relationships between all seen and novel classes in the joint label space. Our model Graph-convolutional Global Prototypical Networks (GcGPN) incorporates these inter-class relations using graph-convolution in order to embed novel class representations into the existing space of previously seen classes in a globally consistent manner. Our approach ensures both fast adaptation and global discrimination, which is the major challenge in GFSL. We demonstrate the benefits of our model on two challenging benchmark datasets.
Batch-Shaped Channel Gated Networks
Jul 15, 2019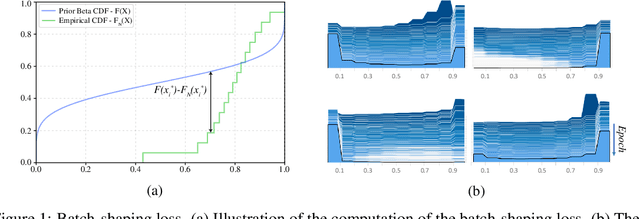
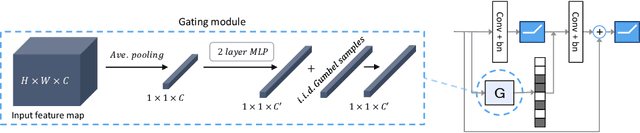
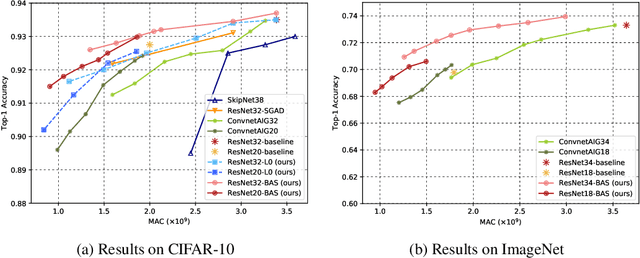
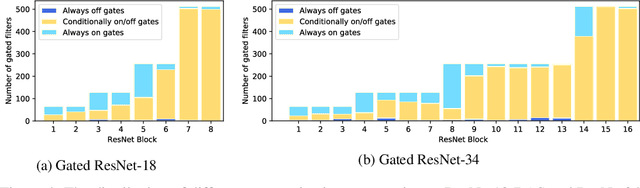
We present a method for gating deep-learning architectures on a fine-grained level. Individual convolutional maps are turned on/off conditionally on features in the network. This method allows us to train neural networks with a large capacity, but lower inference time than the full network. To achieve this, we introduce a new residual block architecture that gates convolutional channels in a fine-grained manner. We also introduce a generally applicable tool "batch-shaping" that matches the marginal aggregate posteriors of features in a neural network to a pre-specified prior distribution. We use this novel technique to force gates to be more conditional on the data. We present results on CIFAR-10 and ImageNet datasets for image classification and Cityscapes for semantic segmentation. Our results show that our method can slim down large architectures conditionally, such that the average computational cost on the data is on par with a smaller architecture, but with higher accuracy. In particular, our ResNet34 gated network achieves a performance of 72.55% top-1 accuracy compared to the 69.76% accuracy of the baseline ResNet18 model, for similar complexity. We also show that the resulting networks automatically learn to use more features for difficult examples and fewer features for simple examples.