 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Neural Machine Translation with Normalizing Flows
May 28, 2020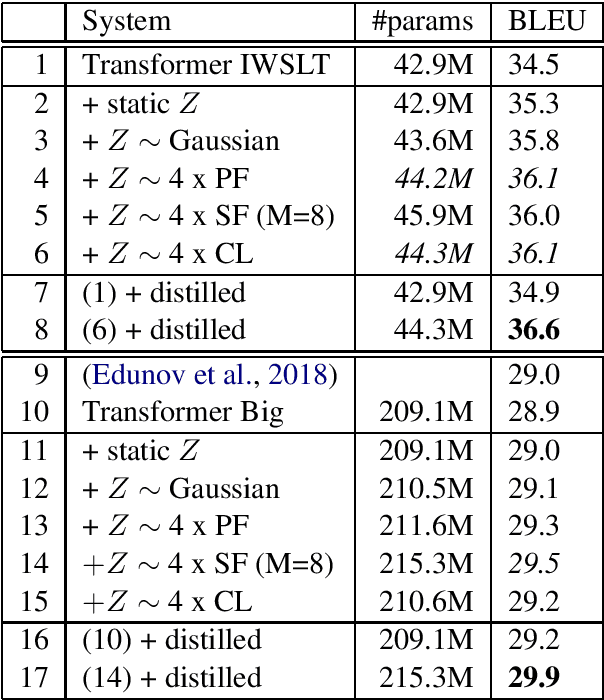

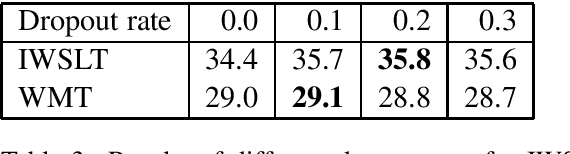

Variational Neural Machine Translation (VNMT) is an attractive framework for modeling the generation of target translations, conditioned not only on the source sentence but also on some latent random variables. The latent variable modeling may introduce useful statistical dependencies that can improve translation accuracy. Unfortunately, learning informative latent variables is non-trivial, as the latent space can be prohibitively large, and the latent codes are prone to be ignored by many translation models at training time. Previous works impose strong assumptions on the distribution of the latent code and limit the choice of the NMT architecture. In this paper, we propose to apply the VNMT framework to the state-of-the-art Transformer and introduce a more flexible approximate posterior based on normalizing flows. We demonstrate the efficacy of our proposal under both in-domain and out-of-domain conditions, significantly outperforming strong baselines.
Speech Translation and the End-to-End Promise: Taking Stock of Where We Are
Apr 14, 2020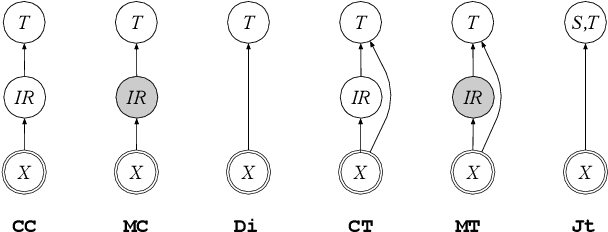


Over its three decade history, speech translation has experienced several shifts in its primary research themes; moving from loosely coupled cascades of speech recognition and machine translation, to exploring questions of tight coupling, and finally to end-to-end models that have recently attracted much attention. This paper provides a brief survey of these developments, along with a discussion of the main challenges of traditional approaches which stem from committing to intermediate representations from the speech recognizer, and from training cascaded models separately towards different objectives. Recent end-to-end modeling techniques promise a principled way of overcoming these issues by allowing joint training of all model components and removing the need for explicit intermediate representations. However, a closer look reveals that many end-to-end models fall short of solving these issues, due to compromises made to address data scarcity. This paper provides a unifying categorization and nomenclature that covers both traditional and recent approaches and that may help researchers by highlighting both trade-offs and open research questions.
Low Latency ASR for Simultaneous Speech Translation
Mar 22, 2020

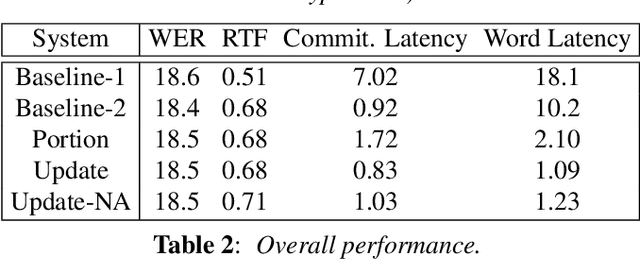
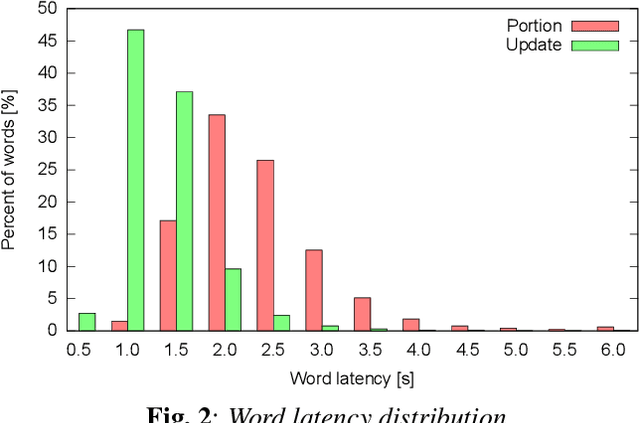
User studies have shown that reducing the latency of our simultaneous lecture translation system should be the most important goal. We therefore have worked on several techniques for reducing the latency for both components, the automatic speech recognition and the speech translation module. Since the commonly used commitment latency is not appropriate in our case of continuous stream decoding, we focused on word latency. We used it to analyze the performance of our current system and to identify opportunities for improvements. In order to minimize the latency we combined run-on decoding with a technique for identifying stable partial hypotheses when stream decoding and a protocol for dynamic output update that allows to revise the most recent parts of the transcription. This combination reduces the latency at word level, where the words are final and will never be updated again in the future, from 18.1s to 1.1s without sacrificing performance in terms of word error rate.
Self-Attentional Models for Lattice Inputs
Jun 04, 2019
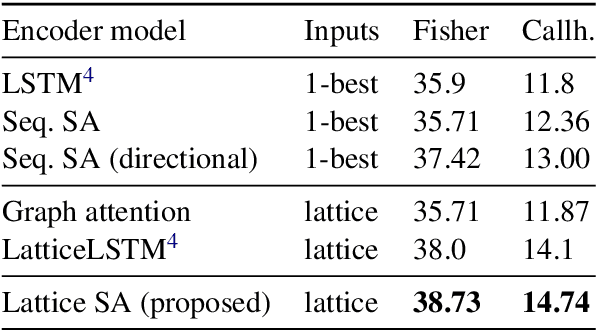
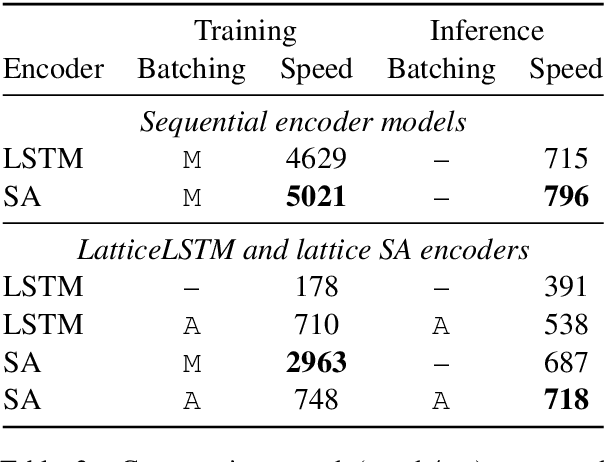
Lattices are an efficient and effective method to encode ambiguity of upstream systems in natural language processing tasks, for example to compactly capture multiple speech recognition hypotheses, or to represent multiple linguistic analyses. Previous work has extended recurrent neural networks to model lattice inputs and achieved improvements in various tasks, but these models suffer from very slow computation speeds. This paper extends the recently proposed paradigm of self-attention to handle lattice inputs. Self-attention is a sequence modeling technique that relates inputs to one another by computing pairwise similarities and has gained popularity for both its strong results and its computational efficiency. To extend such models to handle lattices, we introduce probabilistic reachability masks that incorporate lattice structure into the model and support lattice scores if available. We also propose a method for adapting positional embeddings to lattice structures. We apply the proposed model to a speech translation task and find that it outperforms all examined baselines while being much faster to compute than previous neural lattice models during both training and inference.
Exploring Phoneme-Level Speech Representations for End-to-End Speech Translation
Jun 04, 2019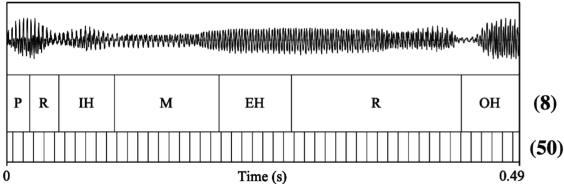

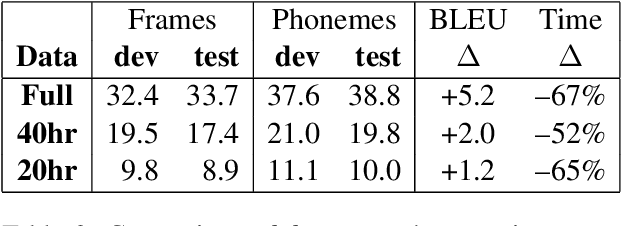
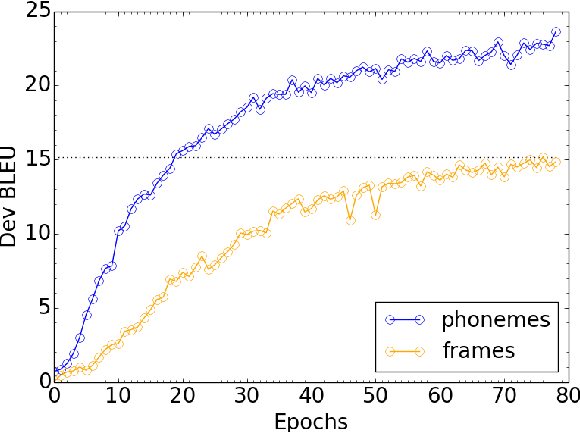
Previous work on end-to-end translation from speech has primarily used frame-level features as speech representations, which creates longer, sparser sequences than text. We show that a naive method to create compressed phoneme-like speech representations is far more effective and efficient for translation than traditional frame-level speech features. Specifically, we generate phoneme labels for speech frames and average consecutive frames with the same label to create shorter, higher-level source sequences for translation. We see improvements of up to 5 BLEU on both our high and low resource language pairs, with a reduction in training time of 60%. Our improvements hold across multiple data sizes and two language pairs.
Fluent Translations from Disfluent Speech in End-to-End Speech Translation
Jun 03, 2019
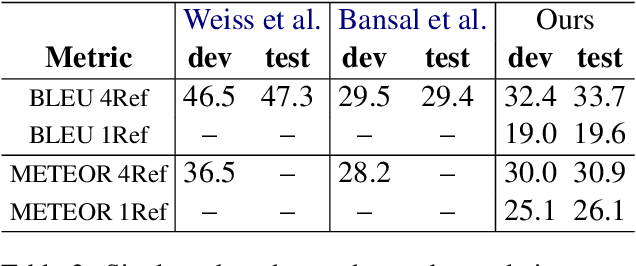
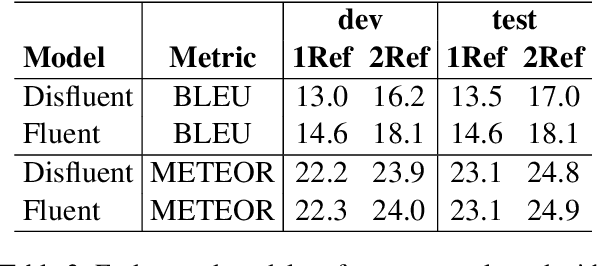
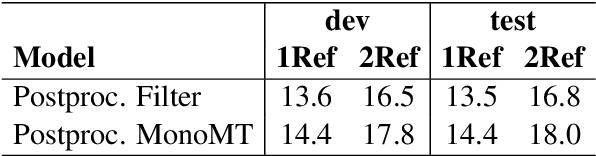
Spoken language translation applications for speech suffer due to conversational speech phenomena, particularly the presence of disfluencies. With the rise of end-to-end speech translation models, processing steps such as disfluency removal that were previously an intermediate step between speech recognition and machine translation need to be incorporated into model architectures. We use a sequence-to-sequence model to translate from noisy, disfluent speech to fluent text with disfluencies removed using the recently collected `copy-edited' references for the Fisher Spanish-English dataset. We are able to directly generate fluent translations and introduce considerations about how to evaluate success on this task. This work provides a baseline for a new task, the translation of conversational speech with joint removal of disfluencies.
Attention-Passing Models for Robust and Data-Efficient End-to-End Speech Translation
Apr 15, 2019Speech translation has traditionally been approached through cascaded models consisting of a speech recognizer trained on a corpus of transcribed speech, and a machine translation system trained on parallel texts. Several recent works have shown the feasibility of collapsing the cascade into a single, direct model that can be trained in an end-to-end fashion on a corpus of translated speech. However, experiments are inconclusive on whether the cascade or the direct model is stronger, and have only been conducted under the unrealistic assumption that both are trained on equal amounts of data, ignoring other available speech recognition and machine translation corpora. In this paper, we demonstrate that direct speech translation models require more data to perform well than cascaded models, and while they allow including auxiliary data through multi-task training, they are poor at exploiting such data, putting them at a severe disadvantage. As a remedy, we propose the use of end-to-end trainable models with two attention mechanisms, the first establishing source speech to source text alignments, the second modeling source to target text alignment. We show that such models naturally decompose into multi-task-trainable recognition and translation tasks and propose an attention-passing technique that alleviates error propagation issues in a previous formulation of a model with two attention stages. Our proposed model outperforms all examined baselines and is able to exploit auxiliary training data much more effectively than direct attentional models.
Paraphrases as Foreign Languages in Multilingual Neural Machine Translation
Aug 25, 2018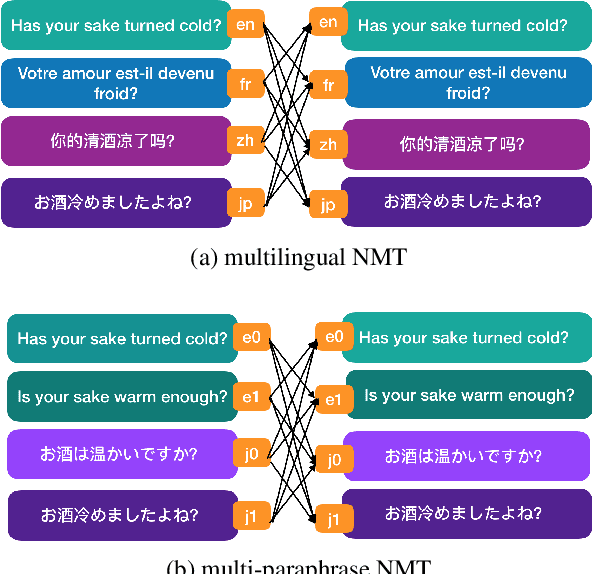

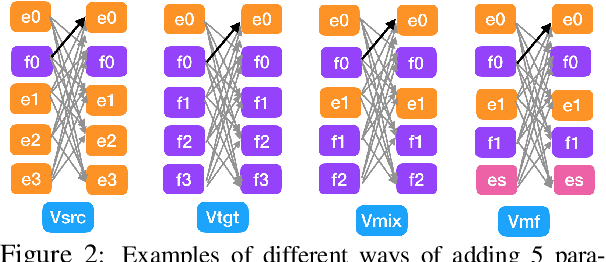
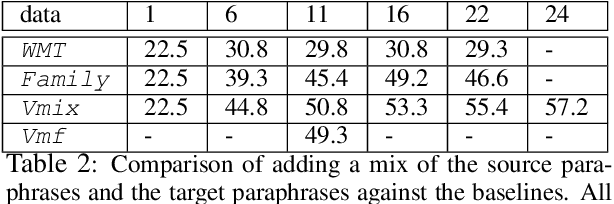
Using paraphrases, the expression of the same semantic meaning in different words, to improve generalization and translation performance is often useful. However, prior works only explore the use of paraphrases at the word or phrase level, not at the sentence or document level. Unlike previous works, we use different translations of the whole training data that are consistent in structure as paraphrases at the corpus level. Our corpus contains parallel paraphrases in multiple languages from various sources. We treat paraphrases as foreign languages, tag source sentences with paraphrase labels, and train in the style of multilingual Neural Machine Translation (NMT). Experimental results indicate that adding paraphrases improves the rare word translation, increases entropy and diversity in lexical choice. Moreover, adding the source paraphrases improves translation performance more effectively than adding the target paraphrases. Combining both the source and the target paraphrases boosts performance further; combining paraphrases with multilingual data also helps but has mixed performance. We achieve a BLEU score of 57.2 for French-to-English translation, training on 24 paraphrases of the Bible, which is ~+27 above the WMT'14 baseline.
Massively Parallel Cross-Lingual Learning in Low-Resource Target Language Translation
Aug 25, 2018
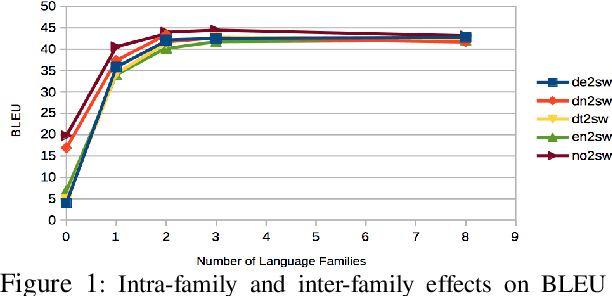
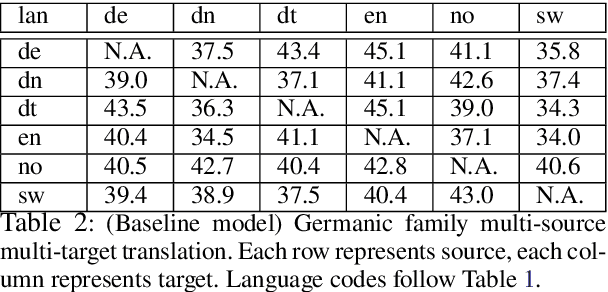
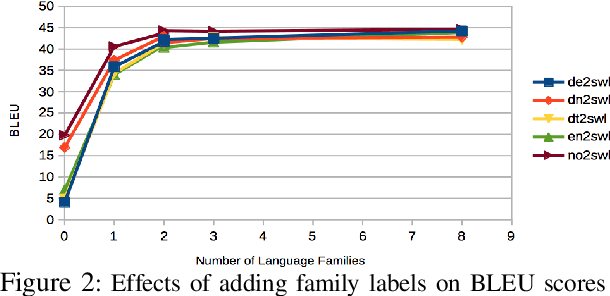
We work on translation from rich-resource languages to low-resource languages. The main challenges we identify are the lack of low-resource language data, effective methods for cross-lingual transfer, and the variable-binding problem that is common in neural systems. We build a translation system that addresses these challenges using eight European language families as our test ground. Firstly, we add the source and the target family labels and study intra-family and inter-family influences for effective cross-lingual transfer. We achieve an improvement of +9.9 in BLEU score for English-Swedish translation using eight families compared to the single-family multi-source multi-target baseline. Moreover, we find that training on two neighboring families closest to the low-resource language is often enough. Secondly, we construct an ablation study and find that reasonably good results can be achieved even with considerably less target data. Thirdly, we address the variable-binding problem by building an order-preserving named entity translation model. We obtain 60.6% accuracy in qualitative evaluation where our translations are akin to human translations in a preliminary study.
Low-Latency Neural Speech Translation
Aug 01, 2018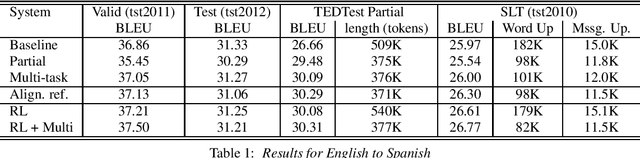
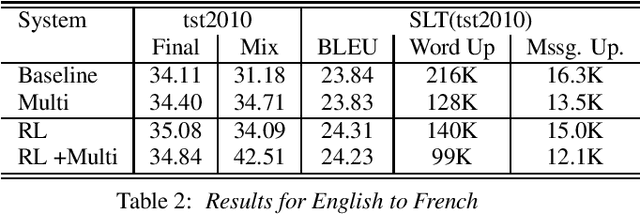
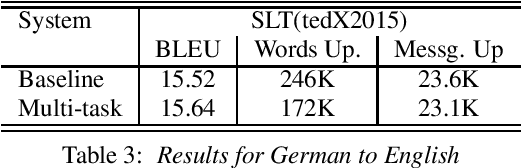
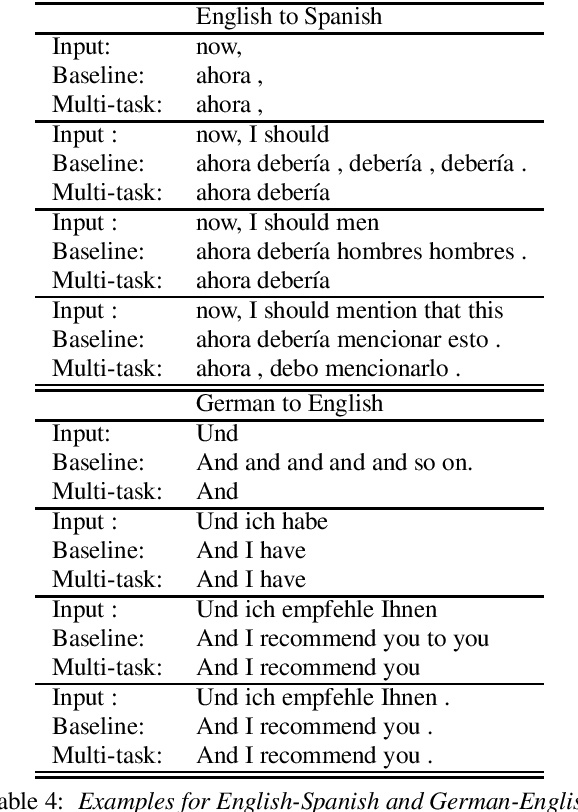
Through the development of neural machine translation, the quality of machine translation systems has been improved significantly. By exploiting advancements in deep learning, systems are now able to better approximate the complex mapping from source sentences to target sentences. But with this ability, new challenges also arise. An example is the translation of partial sentences in low-latency speech translation. Since the model has only seen complete sentences in training, it will always try to generate a complete sentence, though the input may only be a partial sentence. We show that NMT systems can be adapted to scenarios where no task-specific training data is available. Furthermore, this is possible without losing performance on the original training data. We achieve this by creating artificial data and by using multi-task learning. After adaptation, we are able to reduce the number of corrections displayed during incremental output construction by 45%, without a decrease in translation quality.