 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving predictions of Bayesian neural networks via local linearization
Aug 19, 2020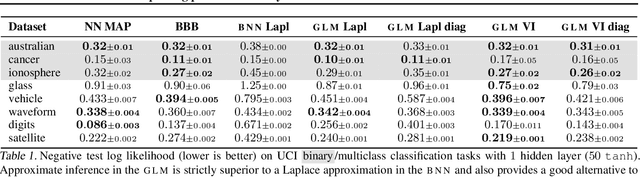
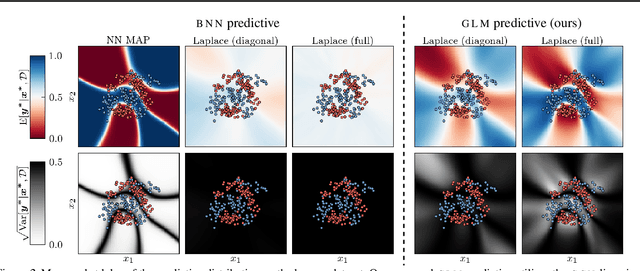
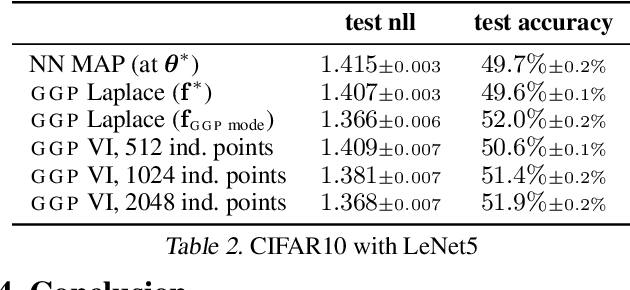

In this paper we argue that in Bayesian deep learning, the frequently utilized generalized Gauss-Newton (GGN) approximation should be understood as a modification of the underlying probabilistic model and should be considered separately from further approximate inference techniques. Applying the GGN approximation turns a BNN into a locally linearized generalized linear model or, equivalently, a Gaussian process. Because we then use this linearized model for inference, we should also predict using this modified likelihood rather than the original BNN likelihood. This formulation extends previous results to general likelihoods and alleviates underfitting behaviour observed e.g. by Ritter et al. (2018). We demonstrate our approach on several UCI classification datasets as well as CIFAR10.
Interpretable and Differentially Private Predictions
Jun 05, 2019
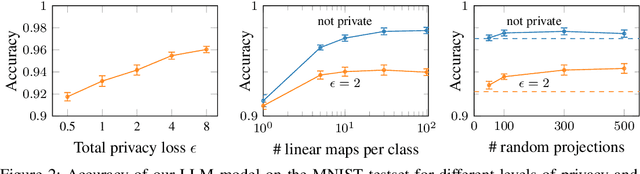

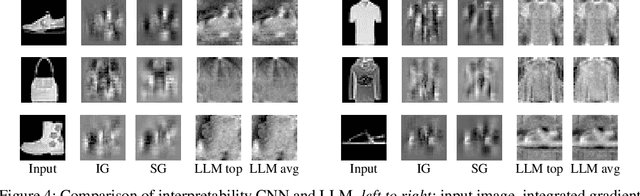
Interpretable predictions, where it is clear why a machine learning model has made a particular decision, can compromise privacy by revealing the characteristics of individual data points. This raises the central question addressed in this paper: Can models be interpretable without compromising privacy? For complex big data fit by correspondingly rich models, balancing privacy and explainability is particularly challenging, such that this question has remained largely unexplored. In this paper, we propose a family of simple models in the aim of approximating complex models using several locally linear maps per class to provide high classification accuracy, as well as differentially private explanations on the classification. We illustrate the usefulness of our approach on several image benchmark datasets as well as a medical dataset.
Resampled Priors for Variational Autoencoders
Oct 26, 2018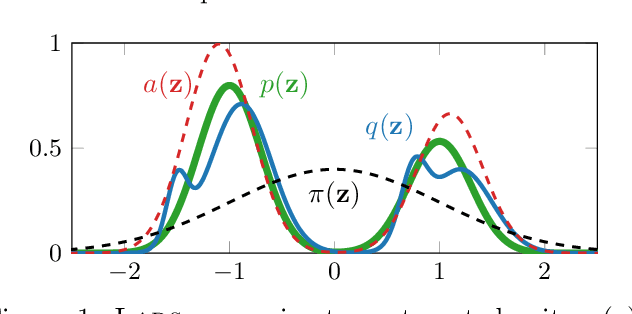
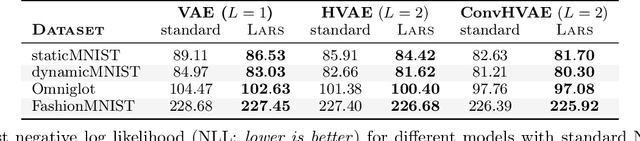
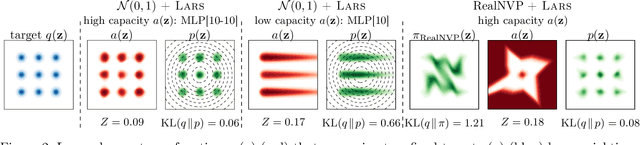

We propose Learned Accept/Reject Sampling (LARS), a method for constructing richer priors using rejection sampling with a learned acceptance function. This work is motivated by recent analyses of the VAE objective, which pointed out that commonly used simple priors can lead to underfitting. As the distribution induced by LARS involves an intractable normalizing constant, we show how to estimate it and its gradients efficiently. We demonstrate that LARS priors improve VAE performance on several standard datasets both when they are learned jointly with the rest of the model and when they are fitted to a pretrained model. Finally, we show that LARS can be combined with existing methods for defining flexible priors for an additional boost in performance.
Learning Invariances using the Marginal Likelihood
Aug 16, 2018
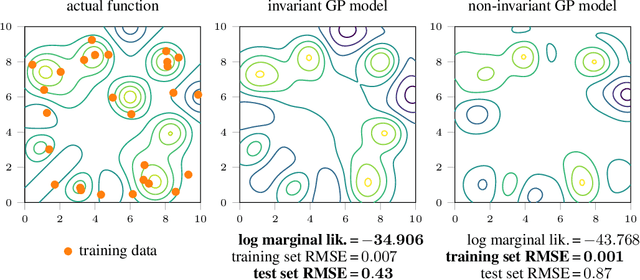
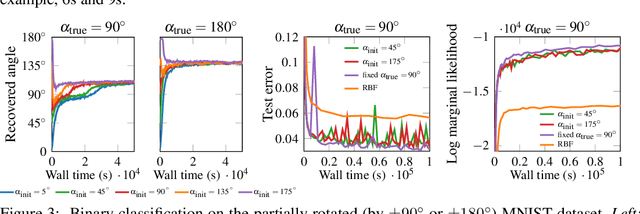
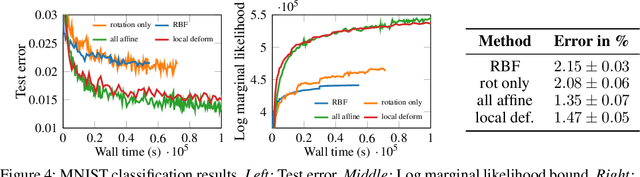
Generalising well in supervised learning tasks relies on correctly extrapolating the training data to a large region of the input space. One way to achieve this is to constrain the predictions to be invariant to transformations on the input that are known to be irrelevant (e.g. translation). Commonly, this is done through data augmentation, where the training set is enlarged by applying hand-crafted transformations to the inputs. We argue that invariances should instead be incorporated in the model structure, and learned using the marginal likelihood, which correctly rewards the reduced complexity of invariant models. We demonstrate this for Gaussian process models, due to the ease with which their marginal likelihood can be estimated. Our main contribution is a variational inference scheme for Gaussian processes containing invariances described by a sampling procedure. We learn the sampling procedure by back-propagating through it to maximise the marginal likelihood.
Decision-Theoretic Meta-Learning: Versatile and Efficient Amortization of Few-Shot Learning
May 31, 2018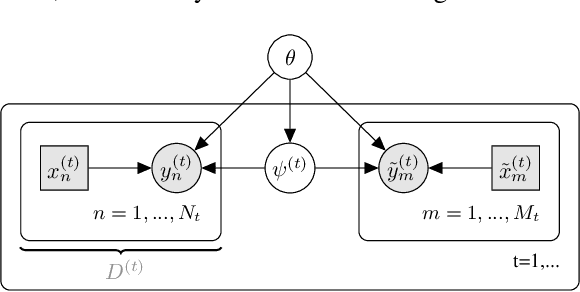

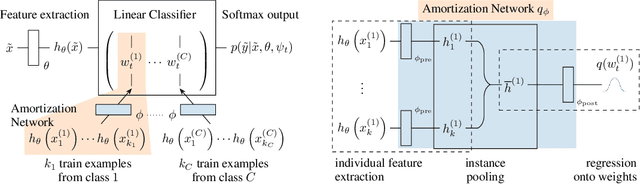
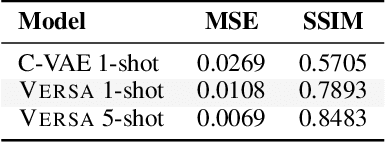
This paper develops a general framework for data efficient and versatile deep learning. The new framework comprises three elements: 1) Discriminative probabilistic models from multi-task learning that leverage shared statistical information across tasks. 2) A novel Bayesian decision theoretic approach to meta-learning probabilistic inference across many tasks. 3) A fast, flexible, and simple to train amortization network that can automatically generalize and extrapolate to a wide range of settings. The VERSA algorithm, a particular instance of the framework, is evaluated on a suite of supervised few-shot learning tasks. VERSA achieves state-of-the-art performance in one-shot learning on Omniglot and miniImagenet, and produces compelling results on a one-shot ShapeNet view reconstruction challenge.
Automatic Estimation of Modulation Transfer Functions
May 04, 2018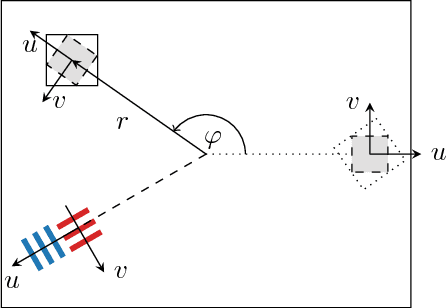
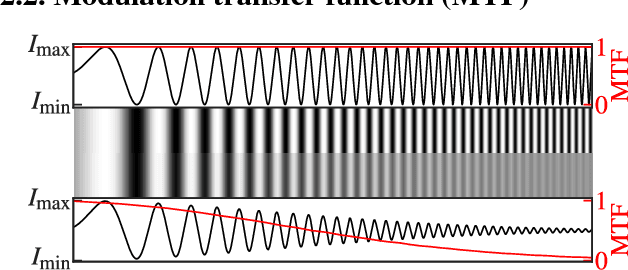
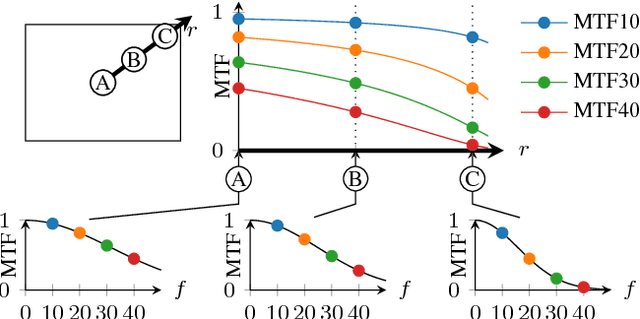
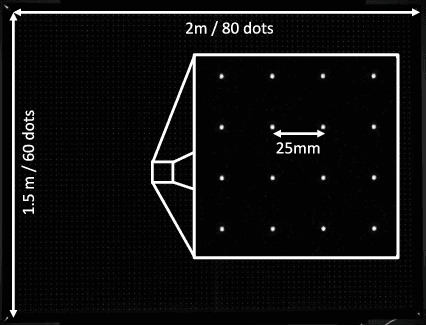
The modulation transfer function (MTF) is widely used to characterise the performance of optical systems. Measuring it is costly and it is thus rarely available for a given lens specimen. Instead, MTFs based on simulations or, at best, MTFs measured on other specimens of the same lens are used. Fortunately, images recorded through an optical system contain ample information about its MTF, only that it is confounded with the statistics of the images. This work presents a method to estimate the MTF of camera lens systems directly from photographs, without the need for expensive equipment. We use a custom grid display to accurately measure the point response of lenses to acquire ground truth training data. We then use the same lenses to record natural images and employ a data-driven supervised learning approach using a convolutional neural network to estimate the MTF on small image patches, aggregating the information into MTF charts over the entire field of view. It generalises to unseen lenses and can be applied for single photographs, with the performance improving if multiple photographs are available.
Discriminative k-shot learning using probabilistic models
Dec 09, 2017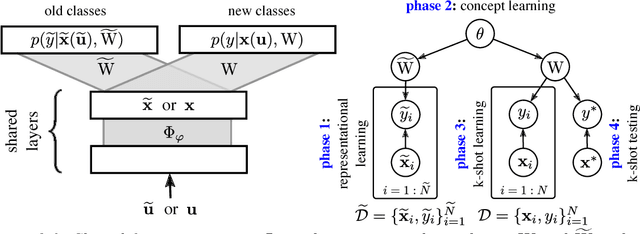
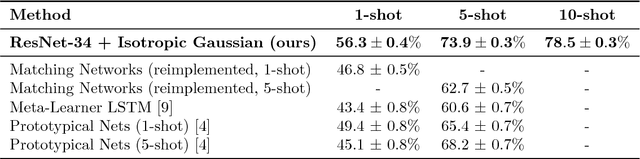
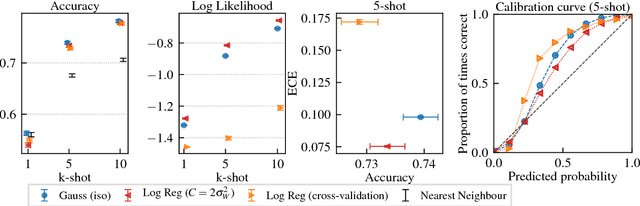

This paper introduces a probabilistic framework for k-shot image classification. The goal is to generalise from an initial large-scale classification task to a separate task comprising new classes and small numbers of examples. The new approach not only leverages the feature-based representation learned by a neural network from the initial task (representational transfer), but also information about the classes (concept transfer). The concept information is encapsulated in a probabilistic model for the final layer weights of the neural network which acts as a prior for probabilistic k-shot learning. We show that even a simple probabilistic model achieves state-of-the-art on a standard k-shot learning dataset by a large margin. Moreover, it is able to accurately model uncertainty, leading to well calibrated classifiers, and is easily extensible and flexible, unlike many recent approaches to k-shot learning.
Understanding Probabilistic Sparse Gaussian Process Approximations
May 30, 2017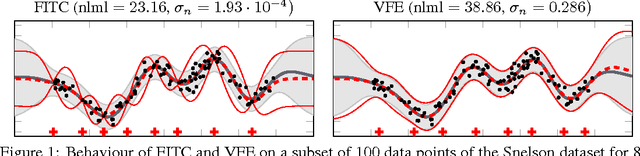
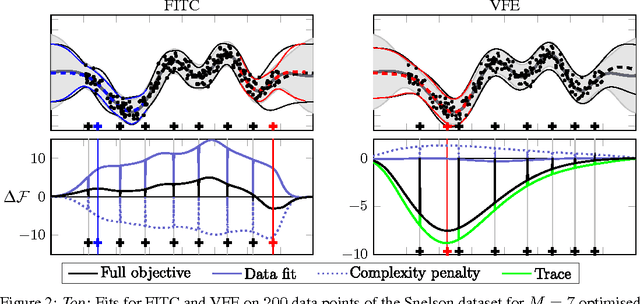
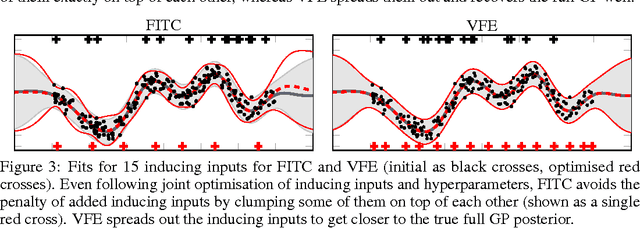

Good sparse approximations are essential for practical inference in Gaussian Processes as the computational cost of exact methods is prohibitive for large datasets. The Fully Independent Training Conditional (FITC) and the Variational Free Energy (VFE) approximations are two recent popular methods. Despite superficial similarities, these approximations have surprisingly different theoretical properties and behave differently in practice. We thoroughly investigate the two methods for regression both analytically and through illustrative examples, and draw conclusions to guide practical application.