 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Embedded Swin-UMamba for DeepLesion Segmentation
Aug 08, 2025Segmentation of lesions on CT enables automatic measurement for clinical assessment of chronic diseases (e.g., lymphoma). Integrating large language models (LLMs) into the lesion segmentation workflow offers the potential to combine imaging features with descriptions of lesion characteristics from the radiology reports. In this study, we investigate the feasibility of integrating text into the Swin-UMamba architecture for the task of lesion segmentation. The publicly available ULS23 DeepLesion dataset was used along with short-form descriptions of the findings from the reports. On the test dataset, a high Dice Score of 82% and low Hausdorff distance of 6.58 (pixels) was obtained for lesion segmentation. The proposed Text-Swin-UMamba model outperformed prior approaches: 37% improvement over the LLM-driven LanGuideMedSeg model (p < 0.001),and surpassed the purely image-based xLSTM-UNet and nnUNet models by 1.74% and 0.22%, respectively. The dataset and code can be accessed at https://github.com/ruida/LLM-Swin-UMamba
Gaze2Segment: A Pilot Study for Integrating Eye-Tracking Technology into Medical Image Segmentation
Aug 10, 2016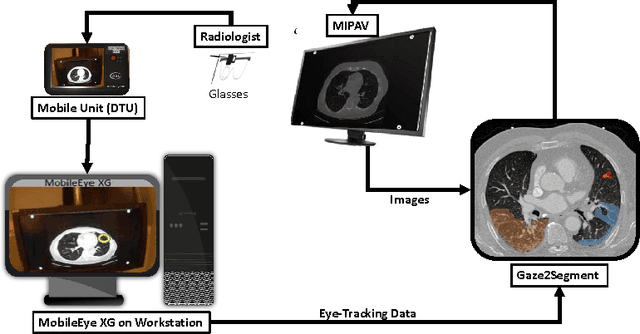
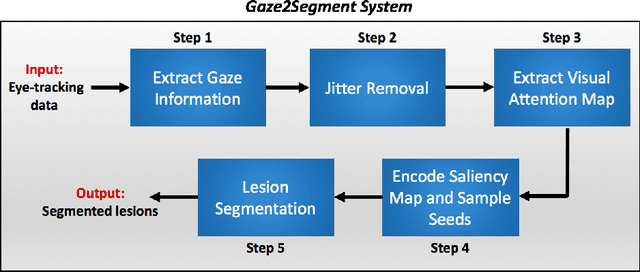
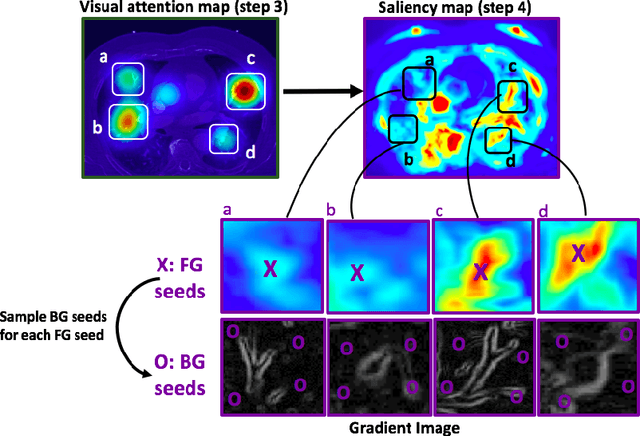
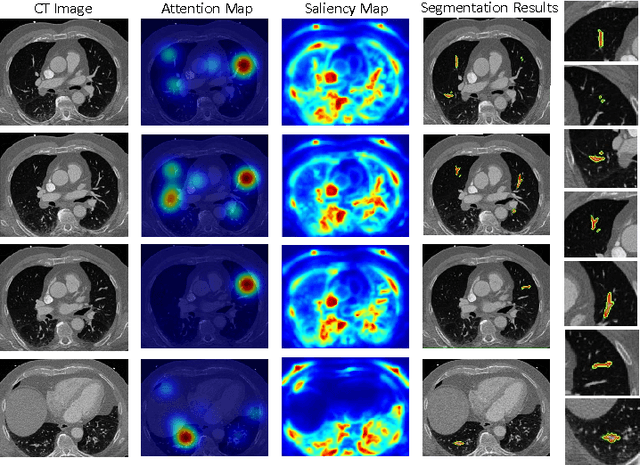
This study introduced a novel system, called Gaze2Segment, integrating biological and computer vision techniques to support radiologists' reading experience with an automatic image segmentation task. During diagnostic assessment of lung CT scans, the radiologists' gaze information were used to create a visual attention map. This map was then combined with a computer-derived saliency map, extracted from the gray-scale CT images. The visual attention map was used as an input for indicating roughly the location of a object of interest. With computer-derived saliency information, on the other hand, we aimed at finding foreground and background cues for the object of interest. At the final step, these cues were used to initiate a seed-based delineation process. Segmentation accuracy of the proposed Gaze2Segment was found to be 86% with dice similarity coefficient and 1.45 mm with Hausdorff distance. To the best of our knowledge, Gaze2Segment is the first true integration of eye-tracking technology into a medical image segmentation task without the need for any further user-interaction.