 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Systolic Tensor Array for Efficient CNN Hardware Acceleration
Sep 04, 2020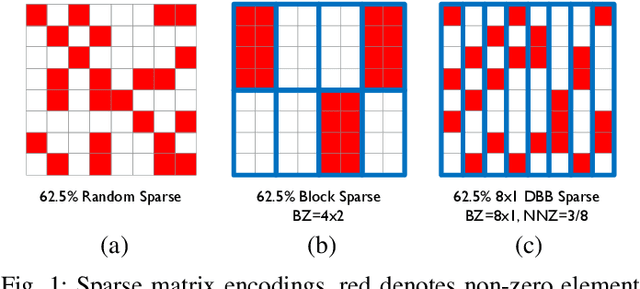
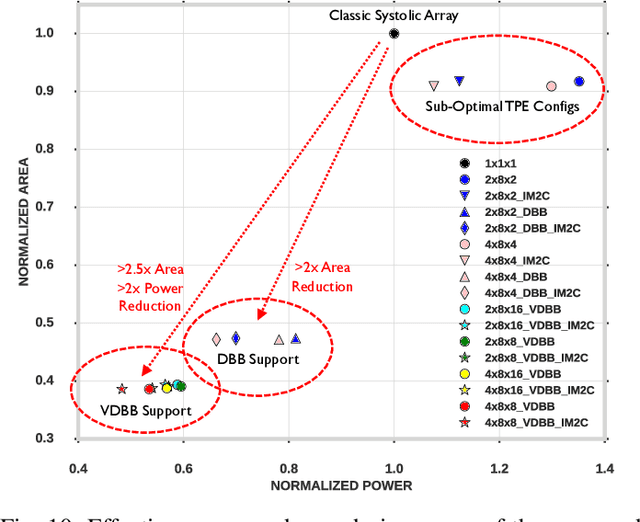

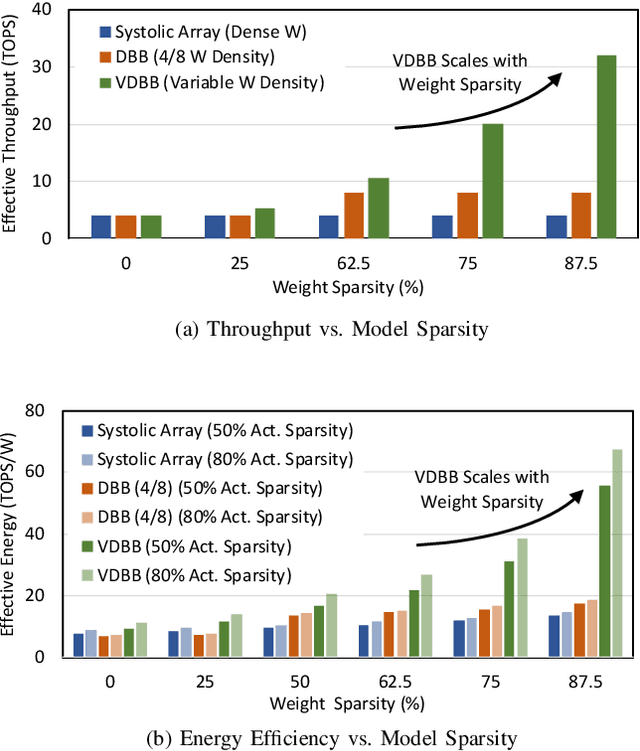
Convolutional neural network (CNN) inference on mobile devices demands efficient hardware acceleration of low-precision (INT8) general matrix multiplication (GEMM). Exploiting data sparsity is a common approach to further accelerate GEMM for CNN inference, and in particular, structural sparsity has the advantages of predictable load balancing and very low index overhead. In this paper, we address a key architectural challenge with structural sparsity: how to provide support for a range of sparsity levels while maintaining high utilization of the hardware. We describe a time unrolled formulation of variable density-bound block (VDBB) sparsity that allows for a configurable number of non-zero elements per block, at constant utilization. We then describe a systolic array microarchitecture that implements this scheme, with two data reuse optimizations. Firstly, we increase reuse in both operands and partial products by increasing the number of MACs per PE. Secondly, we introduce a novel approach of moving the IM2COL transform into the hardware, which allows us to achieve a 3x data bandwidth expansion just before the operands are consumed by the datapath, reducing the SRAM power consumption. The optimizations for weight sparsity, activation sparsity and data reuse are all interrelated and therefore the optimal combination is not obvious. Therefore, we perform an design space evaluation to find the pareto-optimal design characteristics. The resulting design achieves 16.8 TOPS/W in 16nm with modest 50% model sparsity and scales with model sparsity up to 55.7TOPS/W at 87.5%. As well as successfully demonstrating the variable DBB technique, this result significantly outperforms previously reported sparse CNN accelerators.
High Throughput Matrix-Matrix Multiplication between Asymmetric Bit-Width Operands
Aug 03, 2020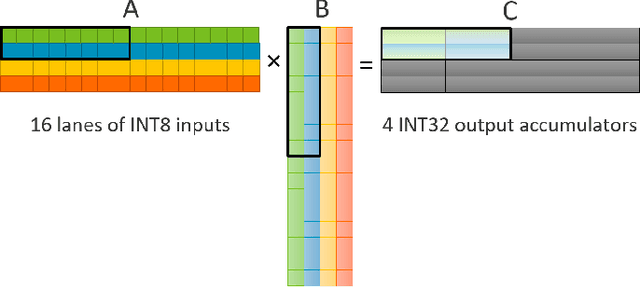
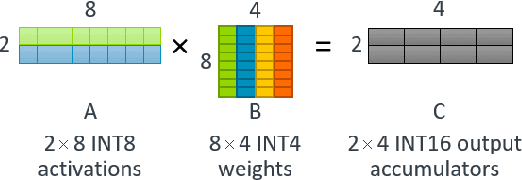
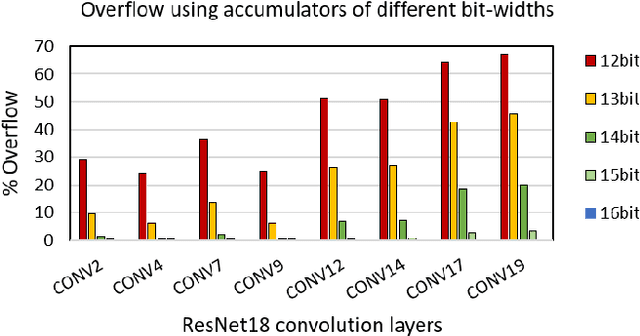
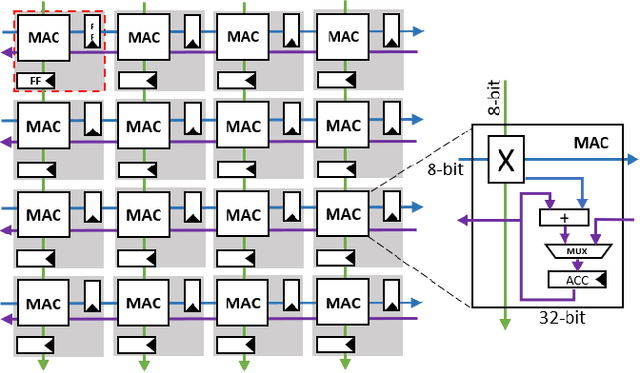
Matrix multiplications between asymmetric bit-width operands, especially between 8- and 4-bit operands are likely to become a fundamental kernel of many important workloads including neural networks and machine learning. While existing SIMD matrix multiplication instructions for symmetric bit-width operands can support operands of mixed precision by zero- or sign-extending the narrow operand to match the size of the other operands, they cannot exploit the benefit of narrow bit-width of one of the operands. We propose a new SIMD matrix multiplication instruction that uses mixed precision on its inputs (8- and 4-bit operands) and accumulates product values into narrower 16-bit output accumulators, in turn allowing the SIMD operation at 128-bit vector width to process a greater number of data elements per instruction to improve processing throughput and memory bandwidth utilization without increasing the register read- and write-port bandwidth in CPUs. The proposed asymmetric-operand-size SIMD instruction offers 2x improvement in throughput of matrix multiplication in comparison to throughput obtained using existing symmetric-operand-size instructions while causing negligible (0.05%) overflow from 16-bit accumulators for representative machine learning workloads. The asymmetric-operand-size instruction not only can improve matrix multiplication throughput in CPUs, but also can be effective to support multiply-and-accumulate (MAC) operation between 8- and 4-bit operands in state-of-the-art DNN hardware accelerators (e.g., systolic array microarchitecture in Google TPU, etc.) and offer similar improvement in matrix multiply performance seamlessly without violating the various implementation constraints. We demonstrate how a systolic array architecture designed for symmetric-operand-size instructions could be modified to support an asymmetric-operand-sized instruction.
Efficient Residue Number System Based Winograd Convolution
Jul 23, 2020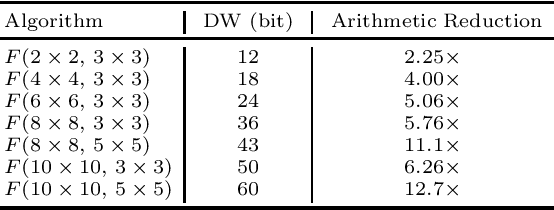
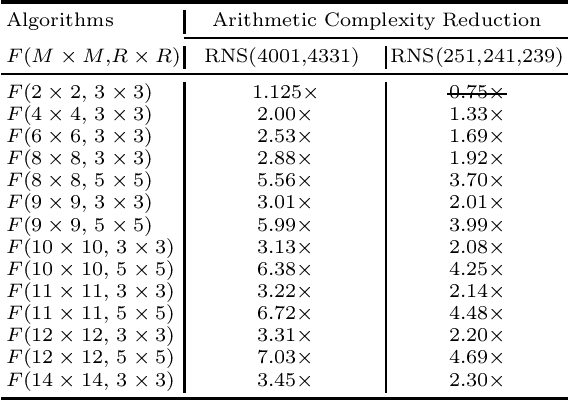
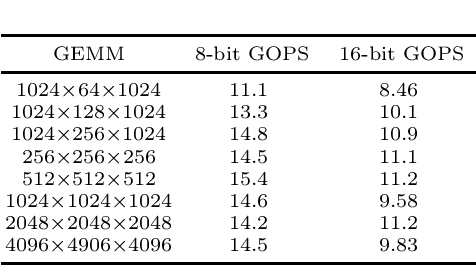
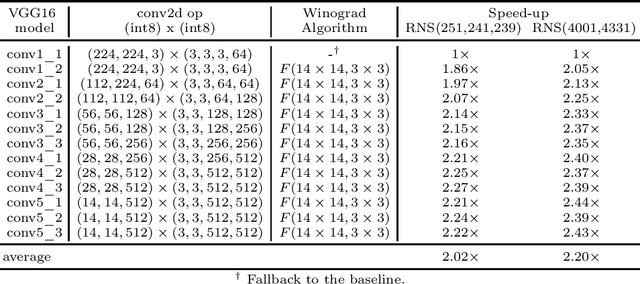
Prior research has shown that Winograd algorithm can reduce the computational complexity of convolutional neural networks (CNN) with weights and activations represented in floating point. However it is difficult to apply the scheme to the inference of low-precision quantized (e.g. INT8) networks. Our work extends the Winograd algorithm to Residue Number System (RNS). The minimal complexity convolution is computed precisely over large transformation tile (e.g. 10 x 10 to 16 x 16) of filters and activation patches using the Winograd transformation and low cost (e.g. 8-bit) arithmetic without degrading the prediction accuracy of the networks during inference. The arithmetic complexity reduction is up to 7.03x while the performance improvement is up to 2.30x to 4.69x for 3 x 3 and 5 x 5 filters respectively.
TinyLSTMs: Efficient Neural Speech Enhancement for Hearing Aids
May 20, 2020
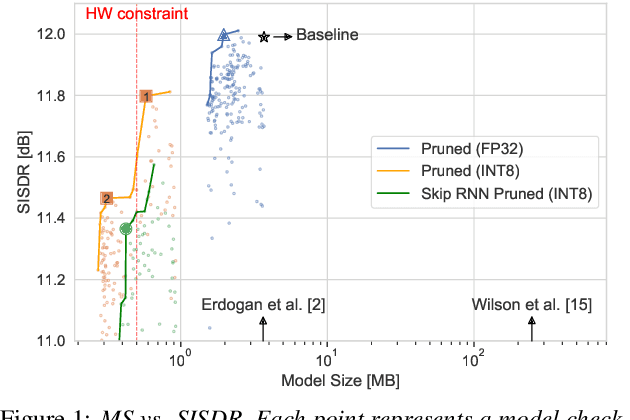
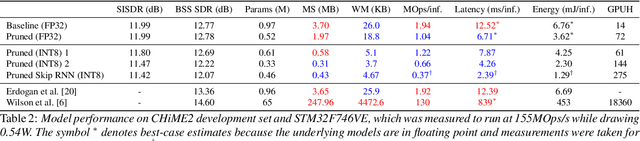
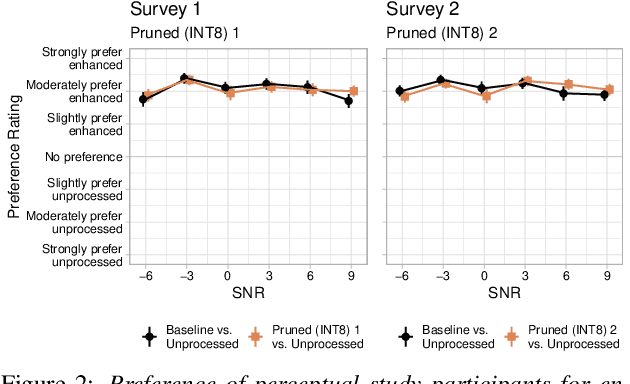
Modern speech enhancement algorithms achieve remarkable noise suppression by means of large recurrent neural networks (RNNs). However, large RNNs limit practical deployment in hearing aid hardware (HW) form-factors, which are battery powered and run on resource-constrained microcontroller units (MCUs) with limited memory capacity and compute capability. In this work, we use model compression techniques to bridge this gap. We define the constraints imposed on the RNN by the HW and describe a method to satisfy them. Although model compression techniques are an active area of research, we are the first to demonstrate their efficacy for RNN speech enhancement, using pruning and integer quantization of weights/activations. We also demonstrate state update skipping, which reduces the computational load. Finally, we conduct a perceptual evaluation of the compressed models to verify audio quality on human raters. Results show a reduction in model size and operations of 11.9$\times$ and 2.9$\times$, respectively, over the baseline for compressed models, without a statistical difference in listening preference and only exhibiting a loss of 0.55dB SDR. Our model achieves a computational latency of 2.39ms, well within the 10ms target and 351$\times$ better than previous work.
Systolic Tensor Array: An Efficient Structured-Sparse GEMM Accelerator for Mobile CNN Inference
May 16, 2020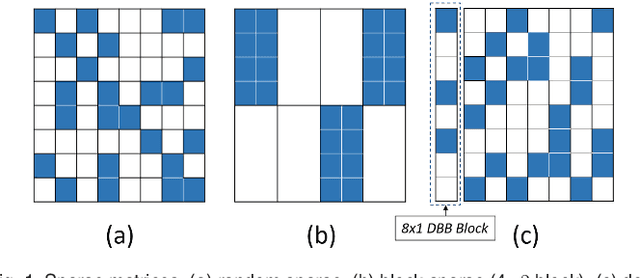
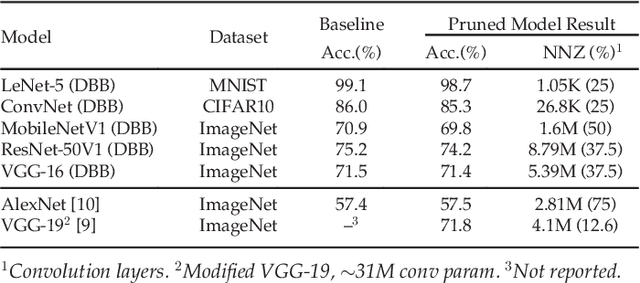
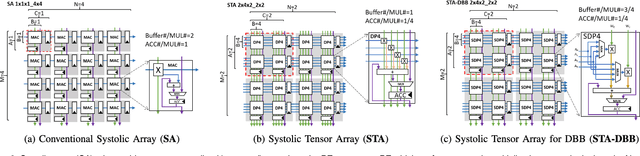

Convolutional neural network (CNN) inference on mobile devices demands efficient hardware acceleration of low-precision (INT8) general matrix multiplication (GEMM). The systolic array (SA) is a pipelined 2D array of processing elements (PEs), with very efficient local data movement, well suited to accelerating GEMM, and widely deployed in industry. In this work, we describe two significant improvements to the traditional SA architecture, to specifically optimize for CNN inference. Firstly, we generalize the traditional scalar PE, into a Tensor-PE, which gives rise to a family of new Systolic Tensor Array (STA) microarchitectures. The STA family increases intra-PE operand reuse and datapath efficiency, resulting in circuit area and power dissipation reduction of as much as 2.08x and 1.36x respectively, compared to the conventional SA at iso-throughput with INT8 operands. Secondly, we extend this design to support a novel block-sparse data format called density-bound block (DBB). This variant (STA-DBB) achieves a 3.14x and 1.97x improvement over the SA baseline at iso-throughput in area and power respectively, when processing specially-trained DBB-sparse models, while remaining fully backwards compatible with dense models.
Searching for Winograd-aware Quantized Networks
Feb 25, 2020
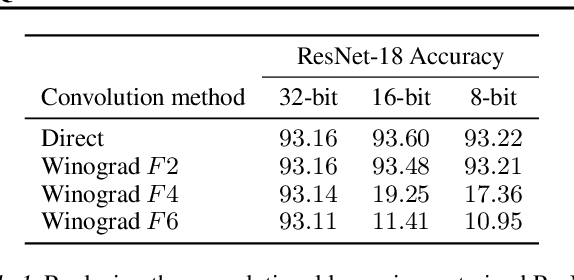
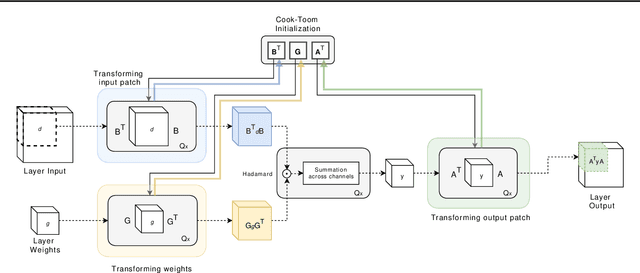
Lightweight architectural designs of Convolutional Neural Networks (CNNs) together with quantization have paved the way for the deployment of demanding computer vision applications on mobile devices. Parallel to this, alternative formulations to the convolution operation such as FFT, Strassen and Winograd, have been adapted for use in CNNs offering further speedups. Winograd convolutions are the fastest known algorithm for spatially small convolutions, but exploiting their full potential comes with the burden of numerical error, rendering them unusable in quantized contexts. In this work we propose a Winograd-aware formulation of convolution layers which exposes the numerical inaccuracies introduced by the Winograd transformations to the learning of the model parameters, enabling the design of competitive quantized models without impacting model size. We also address the source of the numerical error and propose a relaxation on the form of the transformation matrices, resulting in up to 10% higher classification accuracy on CIFAR-10. Finally, we propose wiNAS, a neural architecture search (NAS) framework that jointly optimizes a given macro-architecture for accuracy and latency leveraging Winograd-aware layers. A Winograd-aware ResNet-18 optimized with wiNAS for CIFAR-10 results in 2.66x speedup compared to im2row, one of the most widely used optimized convolution implementations, with no loss in accuracy.
Compressing Language Models using Doped Kronecker Products
Jan 31, 2020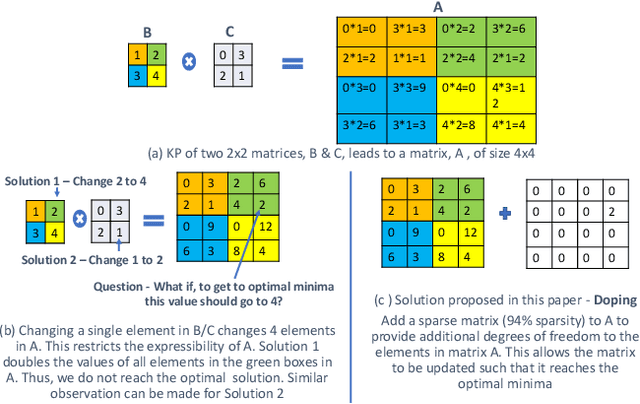
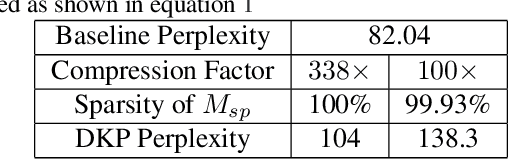
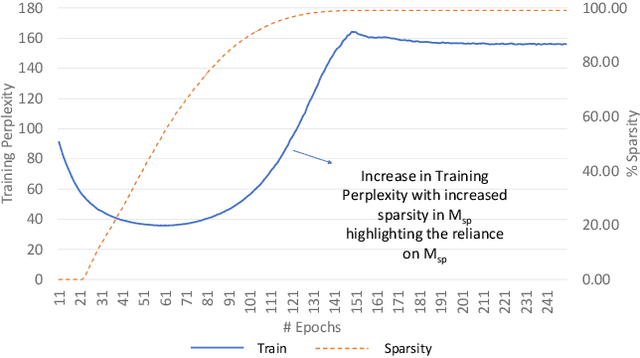
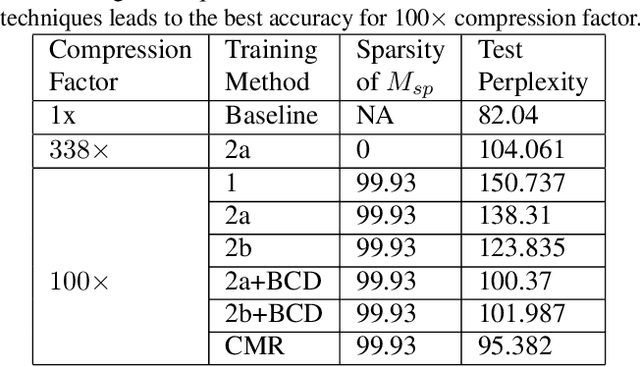
Kronecker Products (KP) have been used to compress IoT RNN Applications by 15-38x compression factors, achieving better results than traditional compression methods. However when KP is applied to large Natural Language Processing tasks, it leads to significant accuracy loss (approx 26%). This paper proposes a way to recover accuracy otherwise lost when applying KP to large NLP tasks, by allowing additional degrees of freedom in the KP matrix. More formally, we propose doping, a process of adding an extremely sparse overlay matrix on top of the pre-defined KP structure. We call this compression method doped kronecker product compression. To train these models, we present a new solution to the phenomenon of co-matrix adaption (CMA), which uses a new regularization scheme called co matrix dropout regularization (CMR). We present experimental results that demonstrate compression of a large language model with LSTM layers of size 25 MB by 25x with 1.4% loss in perplexity score. At 25x compression, an equivalent pruned network leads to 7.9% loss in perplexity score, while HMD and LMF lead to 15% and 27% loss in perplexity score respectively.
* Link to Workshop - https://mlsys.org/Conferences/2020/Schedule?showEvent=1297
Noisy Machines: Understanding Noisy Neural Networks and Enhancing Robustness to Analog Hardware Errors Using Distillation
Jan 14, 2020
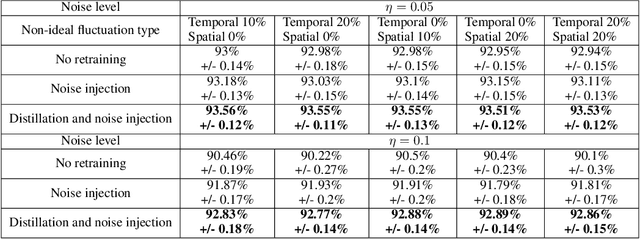
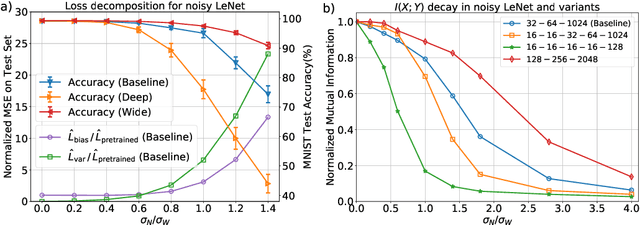
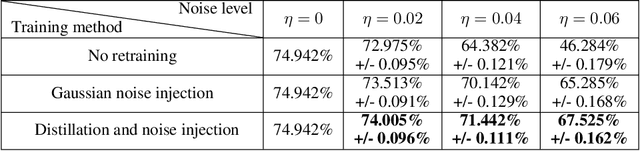
The success of deep learning has brought forth a wave of interest in computer hardware design to better meet the high demands of neural network inference. In particular, analog computing hardware has been heavily motivated specifically for accelerating neural networks, based on either electronic, optical or photonic devices, which may well achieve lower power consumption than conventional digital electronics. However, these proposed analog accelerators suffer from the intrinsic noise generated by their physical components, which makes it challenging to achieve high accuracy on deep neural networks. Hence, for successful deployment on analog accelerators, it is essential to be able to train deep neural networks to be robust to random continuous noise in the network weights, which is a somewhat new challenge in machine learning. In this paper, we advance the understanding of noisy neural networks. We outline how a noisy neural network has reduced learning capacity as a result of loss of mutual information between its input and output. To combat this, we propose using knowledge distillation combined with noise injection during training to achieve more noise robust networks, which is demonstrated experimentally across different networks and datasets, including ImageNet. Our method achieves models with as much as two times greater noise tolerance compared with the previous best attempts, which is a significant step towards making analog hardware practical for deep learning.
ISP4ML: Understanding the Role of Image Signal Processing in Efficient Deep Learning Vision Systems
Nov 25, 2019

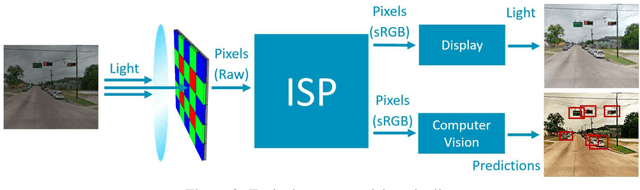
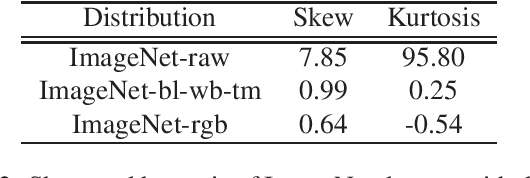
Convolutional neural networks (CNNs) are now predominant components in a variety of computer vision (CV) systems. These systems typically include an image signal processor (ISP), even though the ISP is traditionally designed to produce images that look appealing to humans. In CV systems, it is not clear what the role of the ISP is, or if it is even required at all for accurate prediction. In this work, we investigate the efficacy of the ISP in CNN classification tasks, and outline the system-level trade-offs between prediction accuracy and computational cost. To do so, we build software models of a configurable ISP and an imaging sensor in order to train CNNs on ImageNet with a range of different ISP settings and functionality. Results on ImageNet show that an ISP improves accuracy by 4.6%-12.2% on MobileNet architectures of different widths. Results using ResNets demonstrate that these trends also generalize to deeper networks. An ablation study of the various processing stages in a typical ISP reveals that the tone mapper is the most significant stage when operating on high dynamic range (HDR) images, by providing 5.8% average accuracy improvement alone. Overall, the ISP benefits system efficiency because the memory and computational costs of the ISP is minimal compared to the cost of using a larger CNN to achieve the same accuracy.
Ternary MobileNets via Per-Layer Hybrid Filter Banks
Nov 04, 2019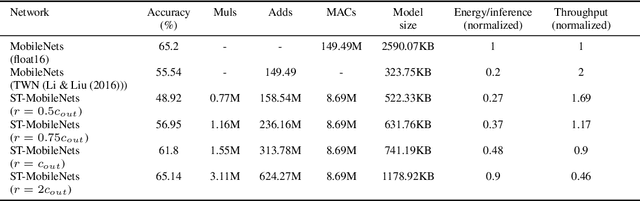
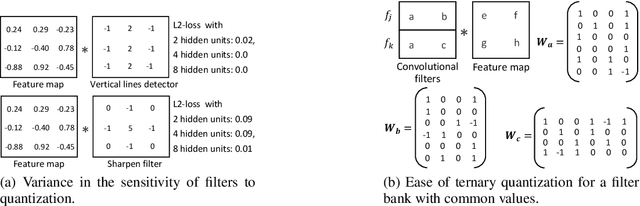
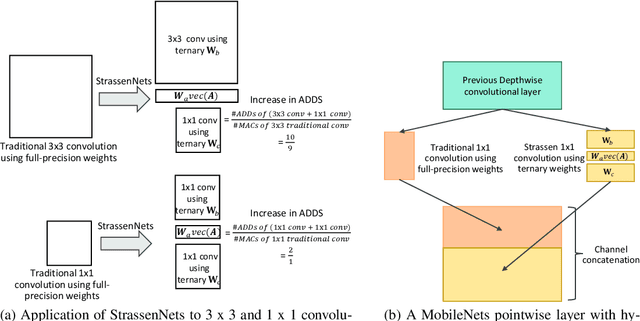
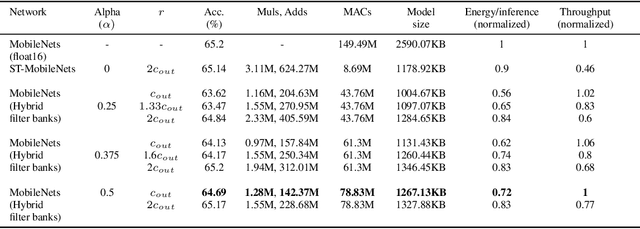
MobileNets family of computer vision neural networks have fueled tremendous progress in the design and organization of resource-efficient architectures in recent years. New applications with stringent real-time requirements on highly constrained devices require further compression of MobileNets-like already compute-efficient networks. Model quantization is a widely used technique to compress and accelerate neural network inference and prior works have quantized MobileNets to 4-6 bits albeit with a modest to significant drop in accuracy. While quantization to sub-byte values (i.e. precision less than or equal to 8 bits) has been valuable, even further quantization of MobileNets to binary or ternary values is necessary to realize significant energy savings and possibly runtime speedups on specialized hardware, such as ASICs and FPGAs. Under the key observation that convolutional filters at each layer of a deep neural network may respond differently to ternary quantization, we propose a novel quantization method that generates per-layer hybrid filter banks consisting of full-precision and ternary weight filters for MobileNets. The layer-wise hybrid filter banks essentially combine the strengths of full-precision and ternary weight filters to derive a compact, energy-efficient architecture for MobileNets. Using this proposed quantization method, we quantized a substantial portion of weight filters of MobileNets to ternary values resulting in 27.98% savings in energy, and a 51.07% reduction in the model size, while achieving comparable accuracy and no degradation in throughput on specialized hardware in comparison to the baseline full-precision MobileNets.