 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOCIALITE-LLAMA: An Instruction-Tuned Model for Social Scientific Tasks
Feb 03, 2024



Social science NLP tasks, such as emotion or humor detection, are required to capture the semantics along with the implicit pragmatics from text, often with limited amounts of training data. Instruction tuning has been shown to improve the many capabilities of large language models (LLMs) such as commonsense reasoning, reading comprehension, and computer programming. However, little is known about the effectiveness of instruction tuning on the social domain where implicit pragmatic cues are often needed to be captured. We explore the use of instruction tuning for social science NLP tasks and introduce Socialite-Llama -- an open-source, instruction-tuned Llama. On a suite of 20 social science tasks, Socialite-Llama improves upon the performance of Llama as well as matches or improves upon the performance of a state-of-the-art, multi-task finetuned model on a majority of them. Further, Socialite-Llama also leads to improvement on 5 out of 6 related social tasks as compared to Llama, suggesting instruction tuning can lead to generalized social understanding. All resources including our code, model and dataset can be found through bit.ly/socialitellama.
Human Language Modeling
May 10, 2022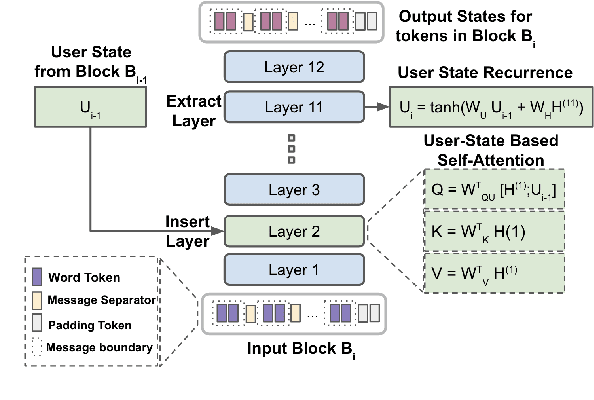
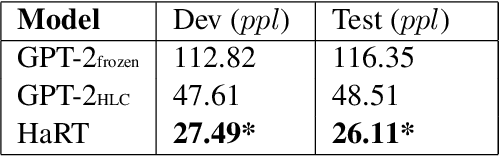
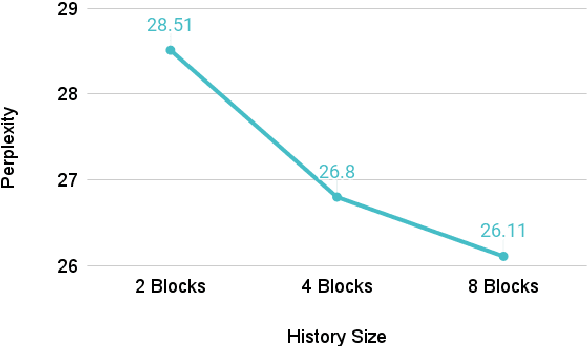
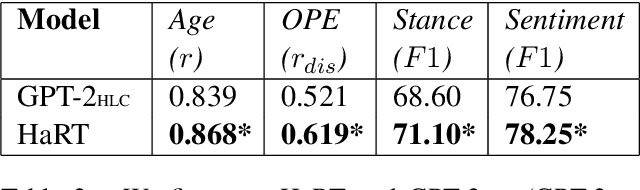
Natural language is generated by people, yet traditional language modeling views words or documents as if generated independently. Here, we propose human language modeling (HuLM), a hierarchical extension to the language modeling problem whereby a human-level exists to connect sequences of documents (e.g. social media messages) and capture the notion that human language is moderated by changing human states. We introduce, HaRT, a large-scale transformer model for the HuLM task, pre-trained on approximately 100,000 social media users, and demonstrate its effectiveness in terms of both language modeling (perplexity) for social media and fine-tuning for 4 downstream tasks spanning document- and user-levels: stance detection, sentiment classification, age estimation, and personality assessment. Results on all tasks meet or surpass the current state-of-the-art.
Understanding RoBERTa's Mood: The Role of Contextual-Embeddings as User-Representations for Depression Prediction
Dec 27, 2021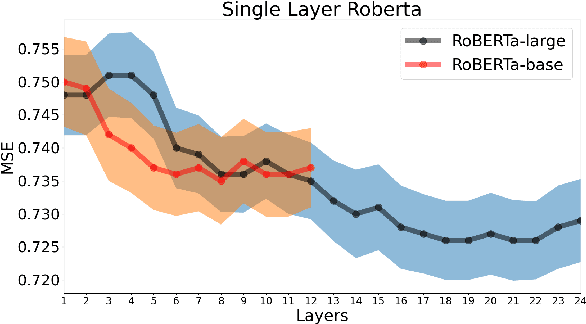
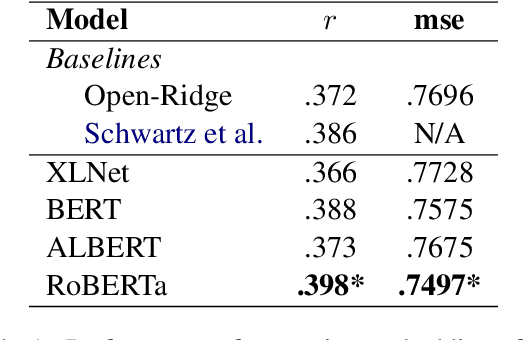
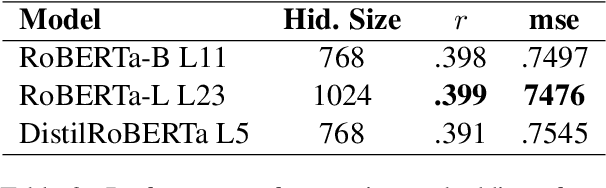
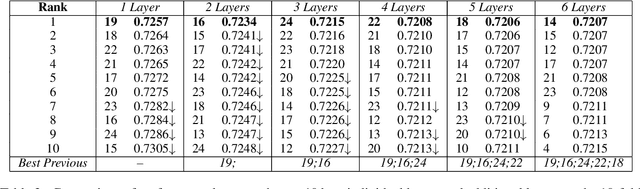
Many works in natural language processing have shown connections between a person's personal discourse and their personality, demographics, and mental health states. However, many of the machine learning models that predict such human traits have yet to fully consider the role of pre-trained language models and contextual embeddings. Using a person's degree of depression as a case study, we do an empirical analysis on which off-the-shelf language model, individual layers, and combinations of layers seem most promising when applied to human-level NLP tasks. Notably, despite the standard in past work of suggesting use of either the second-to-last or the last 4 layers, we find layer 19 (sixth-to last) is the most ideal by itself, while when using multiple layers, distributing them across the second half(i.e. Layers 12+) of the 24 layers is best.
MeLT: Message-Level Transformer with Masked Document Representations as Pre-Training for Stance Detection
Sep 16, 2021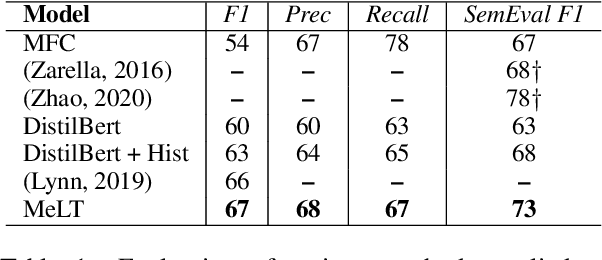
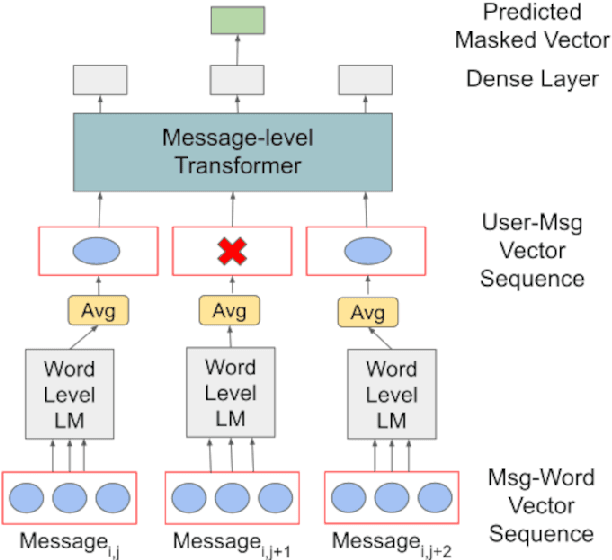
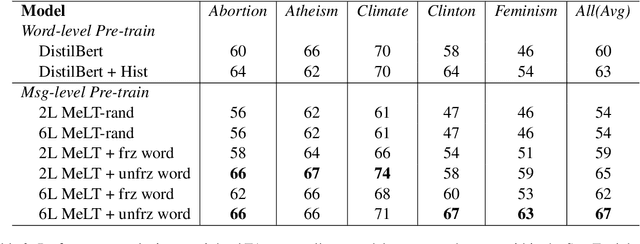
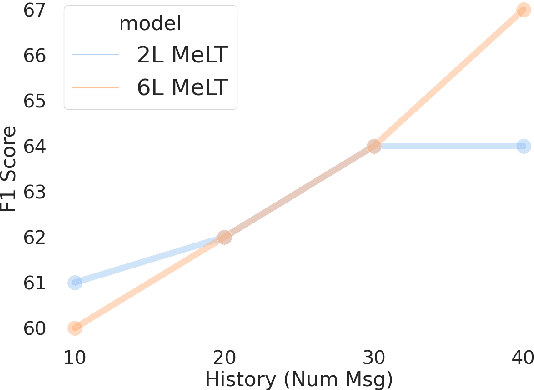
Much of natural language processing is focused on leveraging large capacity language models, typically trained over single messages with a task of predicting one or more tokens. However, modeling human language at higher-levels of context (i.e., sequences of messages) is under-explored. In stance detection and other social media tasks where the goal is to predict an attribute of a message, we have contextual data that is loosely semantically connected by authorship. Here, we introduce Message-Level Transformer (MeLT) -- a hierarchical message-encoder pre-trained over Twitter and applied to the task of stance prediction. We focus on stance prediction as a task benefiting from knowing the context of the message (i.e., the sequence of previous messages). The model is trained using a variant of masked-language modeling; where instead of predicting tokens, it seeks to generate an entire masked (aggregated) message vector via reconstruction loss. We find that applying this pre-trained masked message-level transformer to the downstream task of stance detection achieves F1 performance of 67%.
Empirical Evaluation of Pre-trained Transformers for Human-Level NLP: The Role of Sample Size and Dimensionality
May 07, 2021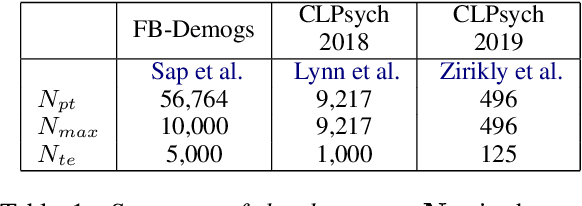
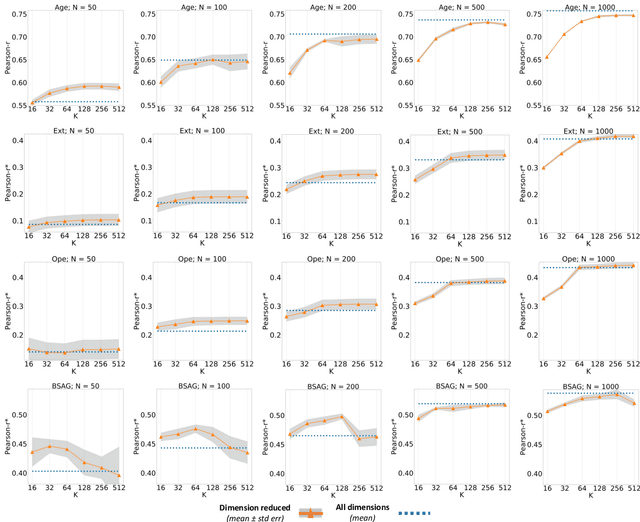
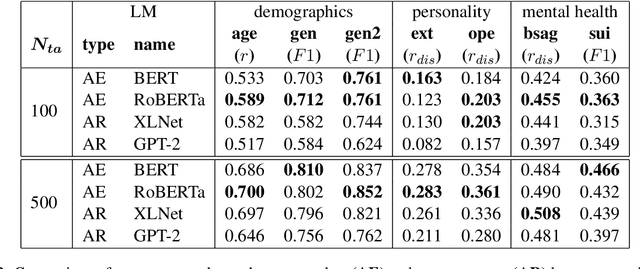
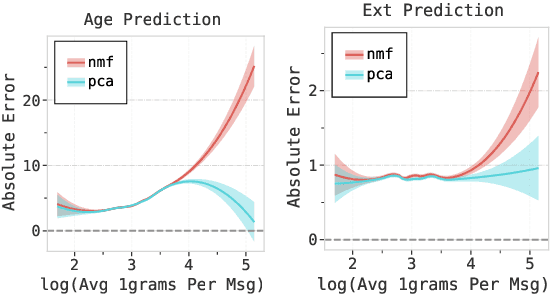
In human-level NLP tasks, such as predicting mental health, personality, or demographics, the number of observations is often smaller than the standard 768+ hidden state sizes of each layer within modern transformer-based language models, limiting the ability to effectively leverage transformers. Here, we provide a systematic study on the role of dimension reduction methods (principal components analysis, factorization techniques, or multi-layer auto-encoders) as well as the dimensionality of embedding vectors and sample sizes as a function of predictive performance. We first find that fine-tuning large models with a limited amount of data pose a significant difficulty which can be overcome with a pre-trained dimension reduction regime. RoBERTa consistently achieves top performance in human-level tasks, with PCA giving benefit over other reduction methods in better handling users that write longer texts. Finally, we observe that a majority of the tasks achieve results comparable to the best performance with just $\frac{1}{12}$ of the embedding dimensions.