 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Possibilistic Fuzzy Local Information C-Means and Possibilistic K-Nearest Neighbors for Synthetic Aperture Sonar Image Segmentation
Apr 01, 2019Synthetic aperture sonar (SAS) imagery can generate high resolution images of the seafloor. Thus, segmentation algorithms can be used to partition the images into different seafloor environments. In this paper, we compare two possibilistic segmentation approaches. Possibilistic approaches allow for the ability to detect novel or outlier environments as well as well known classes. The Possibilistic Fuzzy Local Information C-Means (PFLICM) algorithm has been previously applied to segment SAS imagery. Additionally, the Possibilistic K-Nearest Neighbors (PKNN) algorithm has been used in other domains such as landmine detection and hyperspectral imagery. In this paper, we compare the segmentation performance of a semi-supervised approach using PFLICM and a supervised method using Possibilistic K-NN. We include final segmentation results on multiple SAS images and a quantitative assessment of each algorithm.
Synaptic partner prediction from point annotations in insect brains
Jul 16, 2018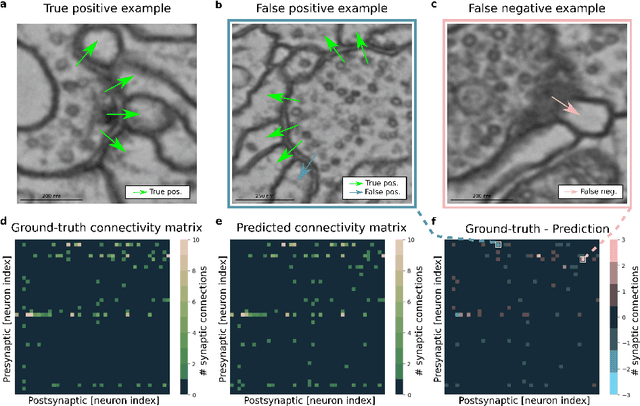
High-throughput electron microscopy allows recording of lar- ge stacks of neural tissue with sufficient resolution to extract the wiring diagram of the underlying neural network. Current efforts to automate this process focus mainly on the segmentation of neurons. However, in order to recover a wiring diagram, synaptic partners need to be identi- fied as well. This is especially challenging in insect brains like Drosophila melanogaster, where one presynaptic site is associated with multiple post- synaptic elements. Here we propose a 3D U-Net architecture to directly identify pairs of voxels that are pre- and postsynaptic to each other. To that end, we formulate the problem of synaptic partner identification as a classification problem on long-range edges between voxels to encode both the presence of a synaptic pair and its direction. This formulation allows us to directly learn from synaptic point annotations instead of more ex- pensive voxel-based synaptic cleft or vesicle annotations. We evaluate our method on the MICCAI 2016 CREMI challenge and improve over the current state of the art, producing 3% fewer errors than the next best method.
Deep Learning in the Automotive Industry: Applications and Tools
Apr 30, 2017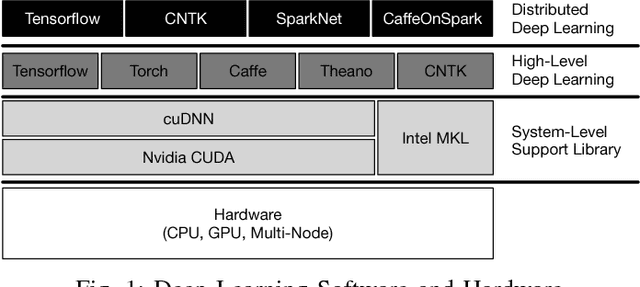
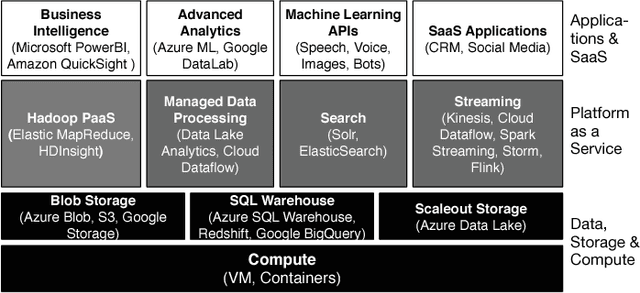
Deep Learning refers to a set of machine learning techniques that utilize neural networks with many hidden layers for tasks, such as image classification, speech recognition, language understanding. Deep learning has been proven to be very effective in these domains and is pervasively used by many Internet services. In this paper, we describe different automotive uses cases for deep learning in particular in the domain of computer vision. We surveys the current state-of-the-art in libraries, tools and infrastructures (e.\,g.\ GPUs and clouds) for implementing, training and deploying deep neural networks. We particularly focus on convolutional neural networks and computer vision use cases, such as the visual inspection process in manufacturing plants and the analysis of social media data. To train neural networks, curated and labeled datasets are essential. In particular, both the availability and scope of such datasets is typically very limited. A main contribution of this paper is the creation of an automotive dataset, that allows us to learn and automatically recognize different vehicle properties. We describe an end-to-end deep learning application utilizing a mobile app for data collection and process support, and an Amazon-based cloud backend for storage and training. For training we evaluate the use of cloud and on-premises infrastructures (including multiple GPUs) in conjunction with different neural network architectures and frameworks. We assess both the training times as well as the accuracy of the classifier. Finally, we demonstrate the effectiveness of the trained classifier in a real world setting during manufacturing process.
A wake-sleep algorithm for recurrent, spiking neural networks
Mar 18, 2017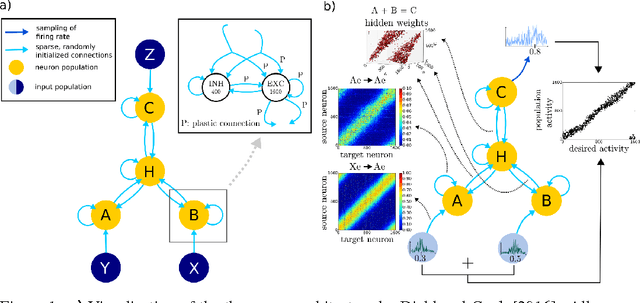
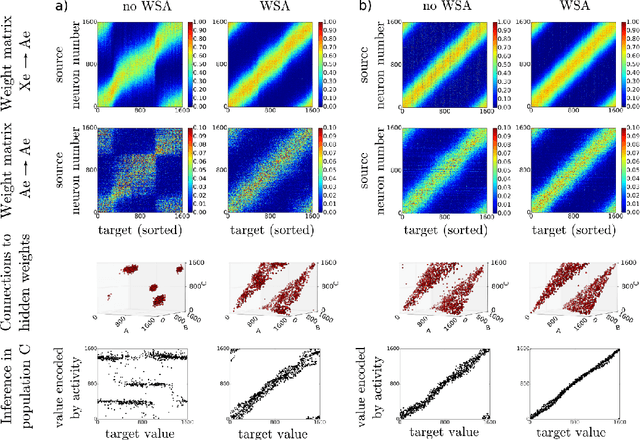
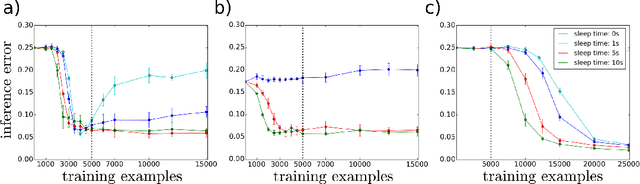
We investigate a recently proposed model for cortical computation which performs relational inference. It consists of several interconnected, structurally equivalent populations of leaky integrate-and-fire (LIF) neurons, which are trained in a self-organized fashion with spike-timing dependent plasticity (STDP). Despite its robust learning dynamics, the model is susceptible to a problem typical for recurrent networks which use a correlation based (Hebbian) learning rule: if trained with high learning rates, the recurrent connections can cause strong feedback loops in the network dynamics, which lead to the emergence of attractor states. This causes a strong reduction in the number of representable patterns and a decay in the inference ability of the network. As a solution, we introduce a conceptually very simple "wake-sleep" algorithm: during the wake phase, training is executed normally, while during the sleep phase, the network "dreams" samples from its generative model, which are induced by random input. This process allows us to activate the attractor states in the network, which can then be unlearned effectively by an anti-Hebbian mechanism. The algorithm allows us to increase learning rates up to a factor of ten while avoiding clustering, which allows the network to learn several times faster. Also for low learning rates, where clustering is not an issue, it improves convergence speed and reduces the final inference error.
Learning and Inferring Relations in Cortical Networks
Aug 29, 2016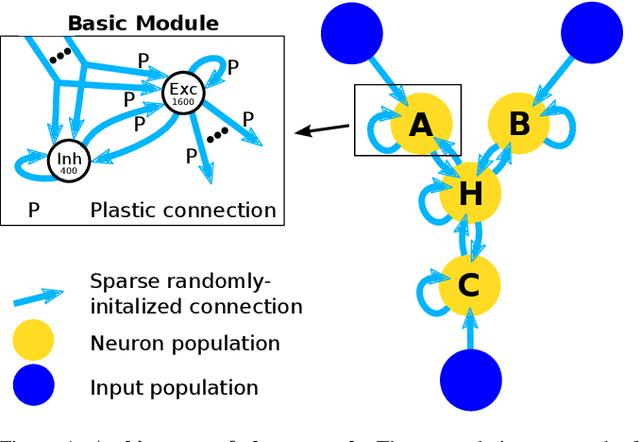

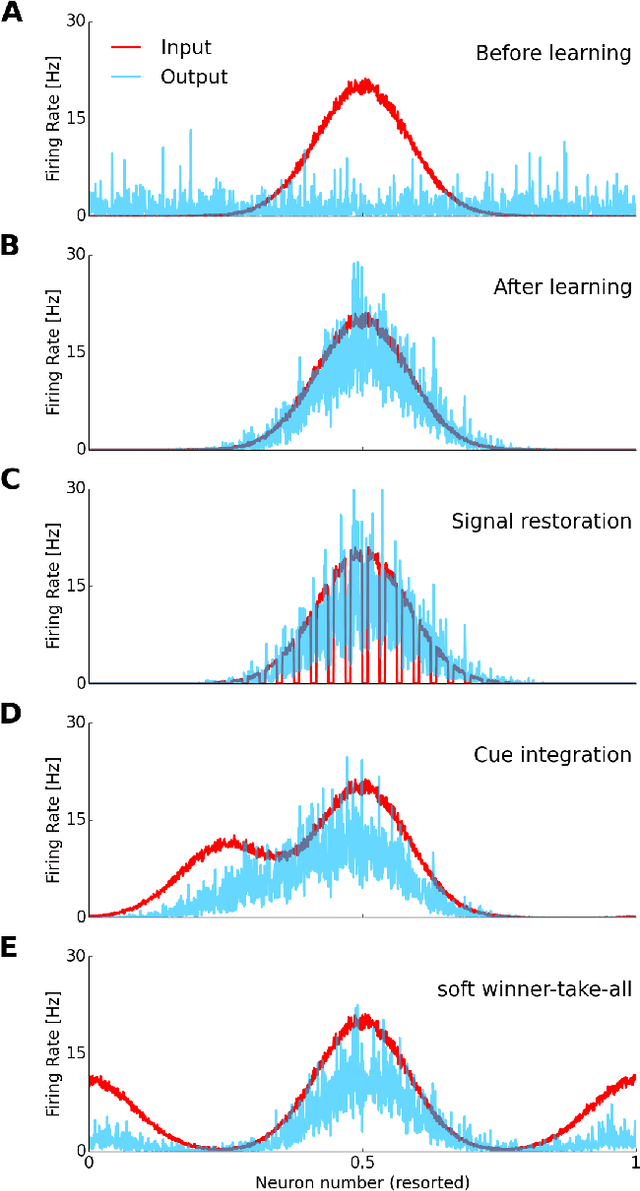

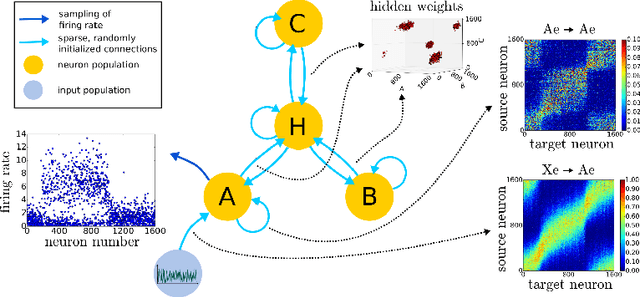
A pressing scientific challenge is to understand how brains work. Of particular interest is the neocortex,the part of the brain that is especially large in humans, capable of handling a wide variety of tasks including visual, auditory, language, motor, and abstract processing. These functionalities are processed in different self-organized regions of the neocortical sheet, and yet the anatomical structure carrying out the processing is relatively uniform across the sheet. We are at a loss to explain, simulate, or understand such a multi-functional homogeneous sheet-like computational structure - we do not have computational models which work in this way. Here we present an important step towards developing such models: we show how uniform modules of excitatory and inhibitory neurons can be connected bidirectionally in a network that, when exposed to input in the form of population codes, learns the input encodings as well as the relationships between the inputs. STDP learning rules lead the modules to self-organize into a relational network, which is able to infer missing inputs,restore noisy signals, decide between conflicting inputs, and combine cues to improve estimates. These networks show that it is possible for a homogeneous network of spiking units to self-organize so as to provide meaningful processing of its inputs. If such networks can be scaled up, they could provide an initial computational model relevant to the large scale anatomy of the neocortex.
Adaptive coherence estimator (ACE) for explosive hazard detection using wideband electromagnetic induction (WEMI)
May 05, 2016The adaptive coherence estimator (ACE) estimates the squared cosine of the angle between a known target vector and a sample vector in a whitened coordinate space. The space is whitened according to an estimation of the background statistics, which directly effects the performance of the statistic as a target detector. In this paper, the ACE detection statistic is used to detect buried explosive hazards with data from a Wideband Electromagnetic Induction (WEMI) sensor. Target signatures are based on a dictionary defined using a Discrete Spectrum of Relaxation Frequencies (DSRF) model. Results are summarized as a receiver operator curve (ROC) and compared to other leading methods.
Buried object detection using handheld WEMI with task-driven extended functions of multiple instances
Mar 19, 2016Many effective supervised discriminative dictionary learning methods have been developed in the literature. However, when training these algorithms, precise ground-truth of the training data is required to provide very accurate point-wise labels. Yet, in many applications, accurate labels are not always feasible. This is especially true in the case of buried object detection in which the size of the objects are not consistent. In this paper, a new multiple instance dictionary learning algorithm for detecting buried objects using a handheld WEMI sensor is detailed. The new algorithm, Task Driven Extended Functions of Multiple Instances, can overcome data that does not have very precise point-wise labels and still learn a highly discriminative dictionary. Results are presented and discussed on measured WEMI data.
TED: A Tolerant Edit Distance for Segmentation Evaluation
Feb 01, 2016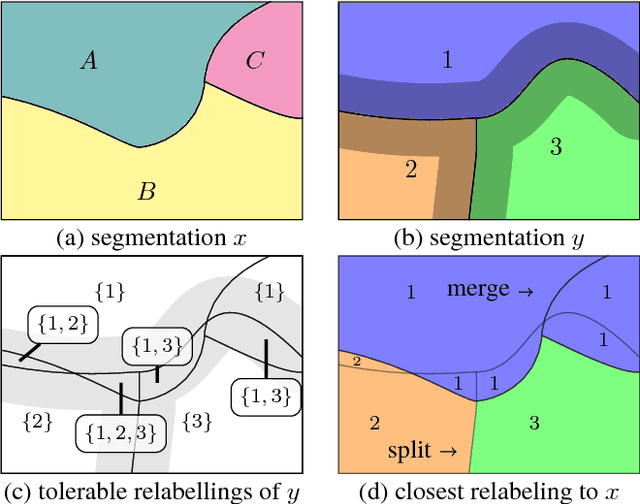


In this paper, we present a novel error measure to compare a segmentation against ground truth. This measure, which we call Tolerant Edit Distance (TED), is motivated by two observations: (1) Some errors, like small boundary shifts, are tolerable in practice. Which errors are tolerable is application dependent and should be a parameter of the measure. (2) Non-tolerable errors have to be corrected manually. The time needed to do so should be reflected by the error measure. Using integer linear programming, the TED finds the minimal weighted sum of split and merge errors exceeding a given tolerance criterion, and thus provides a time-to-fix estimate. In contrast to commonly used measures like Rand index or variation of information, the TED (1) does not count small, but tolerable, differences, (2) provides intuitive numbers, (3) gives a time-to-fix estimate, and (4) can localize and classify the type of errors. By supporting both isotropic and anisotropic volumes and having a flexible tolerance criterion, the TED can be adapted to different requirements. On example segmentations for 3D neuron segmentation, we demonstrate that the TED is capable of counting topological errors, while ignoring small boundary shifts.
Multi-Hypothesis CRF-Segmentation of Neural Tissue in Anisotropic EM Volumes
Sep 18, 2011
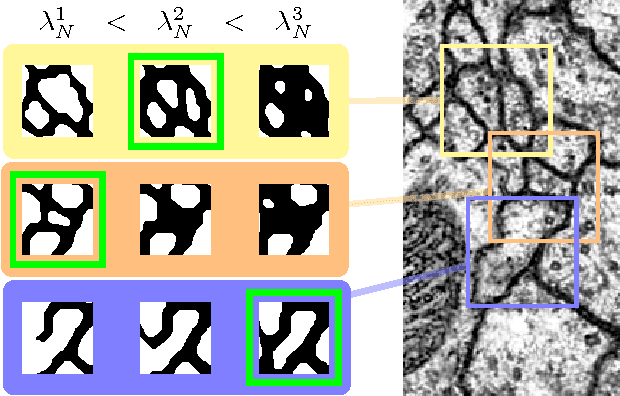
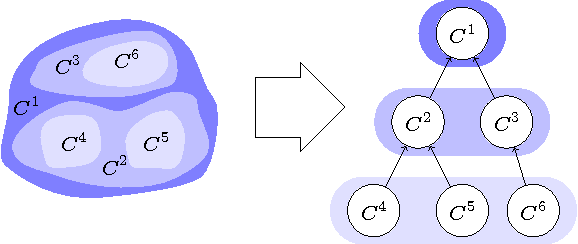

We present an approach for the joint segmentation and grouping of similar components in anisotropic 3D image data and use it to segment neural tissue in serial sections electron microscopy (EM) images. We first construct a nested set of neuron segmentation hypotheses for each slice. A conditional random field (CRF) then allows us to evaluate both the compatibility of a specific segmentation and a specific inter-slice assignment of neuron candidates with the underlying observations. The model is solved optimally for an entire image stack simultaneously using integer linear programming (ILP), which yields the maximum a posteriori solution in amortized linear time in the number of slices. We evaluate the performance of our approach on an annotated sample of the Drosophila larva neuropil and show that the consideration of different segmentation hypotheses in each slice leads to a significant improvement in the segmentation and assignment accuracy.