 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep contextualized word representations
Mar 22, 2018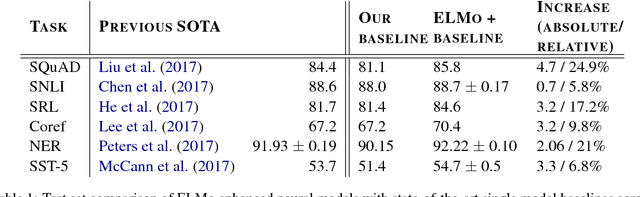
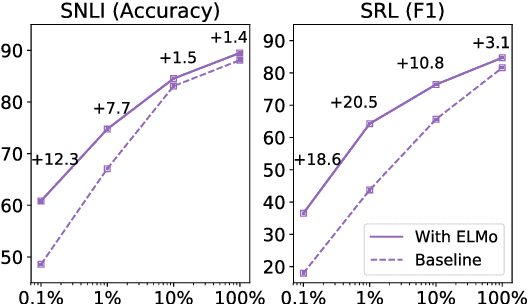
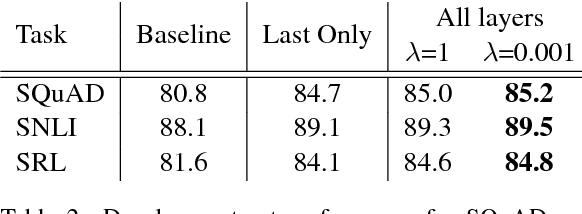
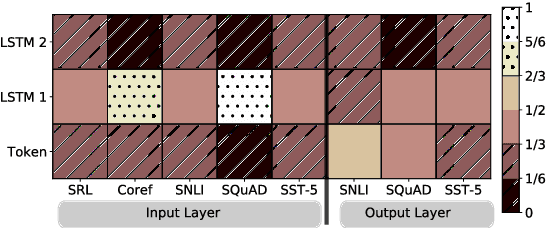
We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus. We show that these representations can be easily added to existing models and significantly improve the state of the art across six challenging NLP problems, including question answering, textual entailment and sentiment analysis. We also present an analysis showing that exposing the deep internals of the pre-trained network is crucial, allowing downstream models to mix different types of semi-supervision signals.
Simple and Effective Multi-Paragraph Reading Comprehension
Nov 07, 2017

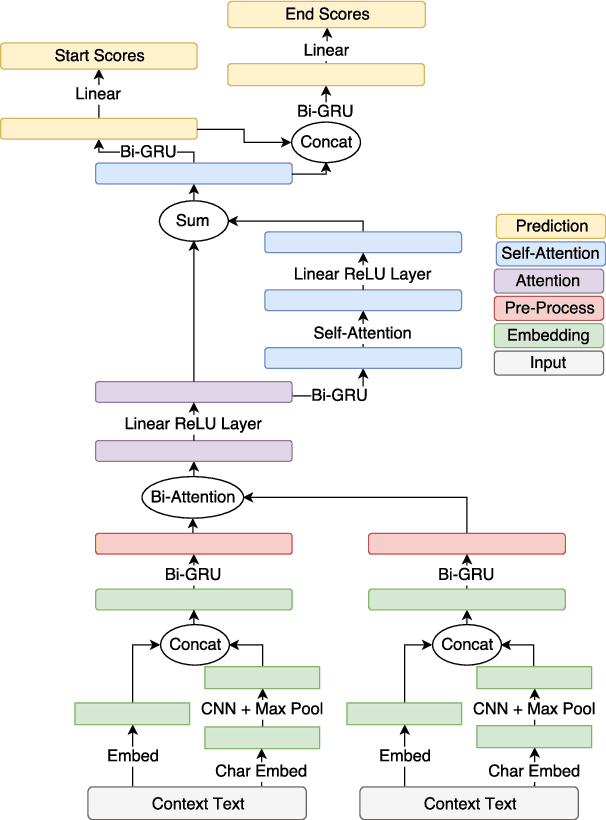
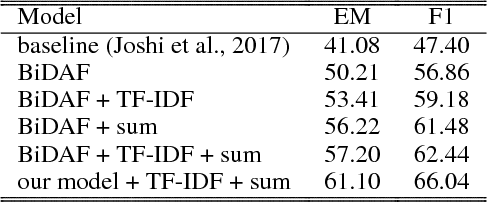
We consider the problem of adapting neural paragraph-level question answering models to the case where entire documents are given as input. Our proposed solution trains models to produce well calibrated confidence scores for their results on individual paragraphs. We sample multiple paragraphs from the documents during training, and use a shared-normalization training objective that encourages the model to produce globally correct output. We combine this method with a state-of-the-art pipeline for training models on document QA data. Experiments demonstrate strong performance on several document QA datasets. Overall, we are able to achieve a score of 71.3 F1 on the web portion of TriviaQA, a large improvement from the 56.7 F1 of the previous best system.
Crowdsourcing Multiple Choice Science Questions
Jul 19, 2017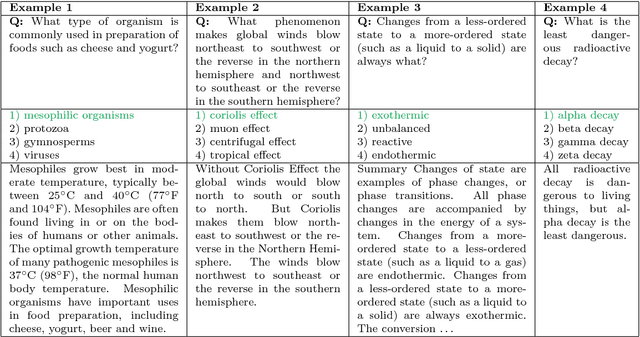
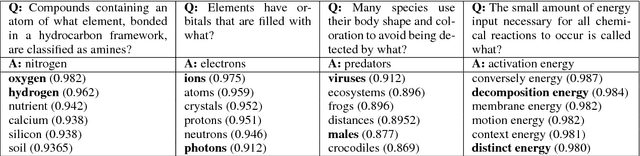
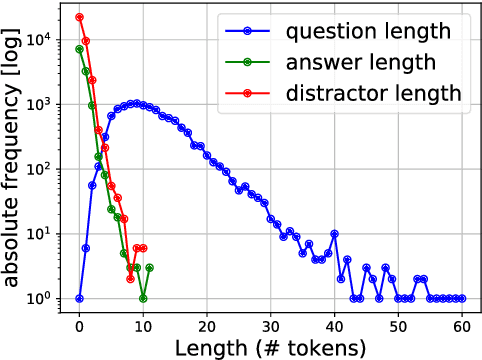
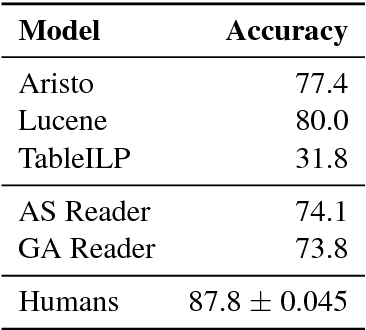
We present a novel method for obtaining high-quality, domain-targeted multiple choice questions from crowd workers. Generating these questions can be difficult without trading away originality, relevance or diversity in the answer options. Our method addresses these problems by leveraging a large corpus of domain-specific text and a small set of existing questions. It produces model suggestions for document selection and answer distractor choice which aid the human question generation process. With this method we have assembled SciQ, a dataset of 13.7K multiple choice science exam questions (Dataset available at http://allenai.org/data.html). We demonstrate that the method produces in-domain questions by providing an analysis of this new dataset and by showing that humans cannot distinguish the crowdsourced questions from original questions. When using SciQ as additional training data to existing questions, we observe accuracy improvements on real science exams.
Open-Vocabulary Semantic Parsing with both Distributional Statistics and Formal Knowledge
Nov 28, 2016
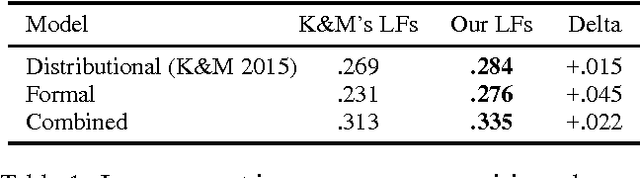
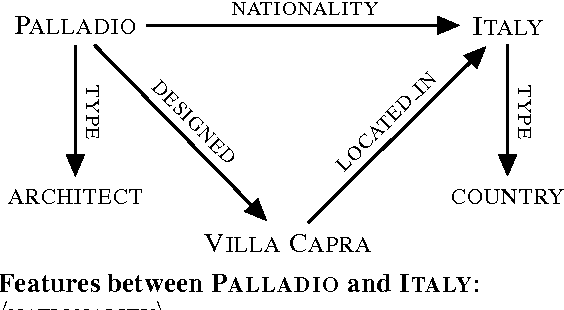

Traditional semantic parsers map language onto compositional, executable queries in a fixed schema. This mapping allows them to effectively leverage the information contained in large, formal knowledge bases (KBs, e.g., Freebase) to answer questions, but it is also fundamentally limiting---these semantic parsers can only assign meaning to language that falls within the KB's manually-produced schema. Recently proposed methods for open vocabulary semantic parsing overcome this limitation by learning execution models for arbitrary language, essentially using a text corpus as a kind of knowledge base. However, all prior approaches to open vocabulary semantic parsing replace a formal KB with textual information, making no use of the KB in their models. We show how to combine the disparate representations used by these two approaches, presenting for the first time a semantic parser that (1) produces compositional, executable representations of language, (2) can successfully leverage the information contained in both a formal KB and a large corpus, and (3) is not limited to the schema of the underlying KB. We demonstrate significantly improved performance over state-of-the-art baselines on an open-domain natural language question answering task.