 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVControl: Efficient Framework for Training Audio-Visual Controls
Mar 25, 2026Controlling video and audio generation requires diverse modalities, from depth and pose to camera trajectories and audio transformations, yet existing approaches either train a single monolithic model for a fixed set of controls or introduce costly architectural changes for each new modality. We introduce AVControl, a lightweight, extendable framework built on LTX-2, a joint audio-visual foundation model, where each control modality is trained as a separate LoRA on a parallel canvas that provides the reference signal as additional tokens in the attention layers, requiring no architectural changes beyond the LoRA adapters themselves. We show that simply extending image-based in-context methods to video fails for structural control, and that our parallel canvas approach resolves this. On the VACE Benchmark, we outperform all evaluated baselines on depth- and pose-guided generation, inpainting, and outpainting, and show competitive results on camera control and audio-visual benchmarks. Our framework supports a diverse set of independently trained modalities: spatially-aligned controls such as depth, pose, and edges, camera trajectory with intrinsics, sparse motion control, video editing, and, to our knowledge, the first modular audio-visual controls for a joint generation model. Our method is both compute- and data-efficient: each modality requires only a small dataset and converges within a few hundred to a few thousand training steps, a fraction of the budget of monolithic alternatives. We publicly release our code and trained LoRA checkpoints.
Gaussian Mixture Generative Adversarial Networks for Diverse Datasets, and the Unsupervised Clustering of Images
Aug 30, 2018

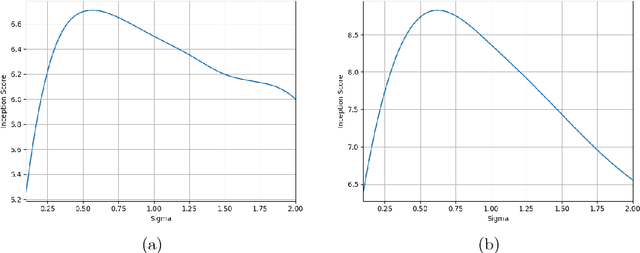
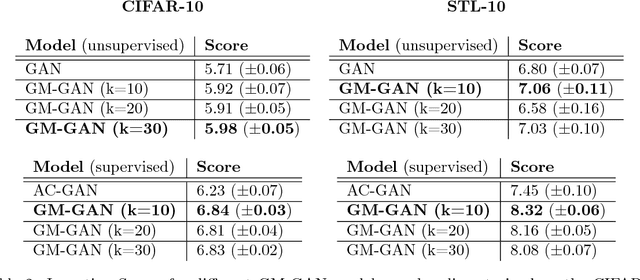
Generative Adversarial Networks (GANs) have been shown to produce realistically looking synthetic images with remarkable success, yet their performance seems less impressive when the training set is highly diverse. In order to provide a better fit to the target data distribution when the dataset includes many different classes, we propose a variant of the basic GAN model, called Gaussian Mixture GAN (GM-GAN), where the probability distribution over the latent space is a mixture of Gaussians. We also propose a supervised variant which is capable of conditional sample synthesis. In order to evaluate the model's performance, we propose a new scoring method which separately takes into account two (typically conflicting) measures - diversity vs. quality of the generated data. Through a series of empirical experiments, using both synthetic and real-world datasets, we quantitatively show that GM-GANs outperform baselines, both when evaluated using the commonly used Inception Score, and when evaluated using our own alternative scoring method. In addition, we qualitatively demonstrate how the \textit{unsupervised} variant of GM-GAN tends to map latent vectors sampled from different Gaussians in the latent space to samples of different classes in the data space. We show how this phenomenon can be exploited for the task of unsupervised clustering, and provide quantitative evaluation showing the superiority of our method for the unsupervised clustering of image datasets. Finally, we demonstrate a feature which further sets our model apart from other GAN models: the option to control the quality-diversity trade-off by altering, post-training, the probability distribution of the latent space. This allows one to sample higher quality and lower diversity samples, or vice versa, according to one's needs.