 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDR Video Generation via Latent Alignment with Logarithmic Encoding
Apr 13, 2026High dynamic range (HDR) imagery offers a rich and faithful representation of scene radiance, but remains challenging for generative models due to its mismatch with the bounded, perceptually compressed data on which these models are trained. A natural solution is to learn new representations for HDR, which introduces additional complexity and data requirements. In this work, we show that HDR generation can be achieved in a much simpler way by leveraging the strong visual priors already captured by pretrained generative models. We observe that a logarithmic encoding widely used in cinematic pipelines maps HDR imagery into a distribution that is naturally aligned with the latent space of these models, enabling direct adaptation via lightweight fine-tuning without retraining an encoder. To recover details that are not directly observable in the input, we further introduce a training strategy based on camera-mimicking degradations that encourages the model to infer missing high dynamic range content from its learned priors. Combining these insights, we demonstrate high-quality HDR video generation using a pretrained video model with minimal adaptation, achieving strong results across diverse scenes and challenging lighting conditions. Our results indicate that HDR, despite representing a fundamentally different image formation regime, can be handled effectively without redesigning generative models, provided that the representation is chosen to align with their learned priors.
AVControl: Efficient Framework for Training Audio-Visual Controls
Mar 25, 2026Controlling video and audio generation requires diverse modalities, from depth and pose to camera trajectories and audio transformations, yet existing approaches either train a single monolithic model for a fixed set of controls or introduce costly architectural changes for each new modality. We introduce AVControl, a lightweight, extendable framework built on LTX-2, a joint audio-visual foundation model, where each control modality is trained as a separate LoRA on a parallel canvas that provides the reference signal as additional tokens in the attention layers, requiring no architectural changes beyond the LoRA adapters themselves. We show that simply extending image-based in-context methods to video fails for structural control, and that our parallel canvas approach resolves this. On the VACE Benchmark, we outperform all evaluated baselines on depth- and pose-guided generation, inpainting, and outpainting, and show competitive results on camera control and audio-visual benchmarks. Our framework supports a diverse set of independently trained modalities: spatially-aligned controls such as depth, pose, and edges, camera trajectory with intrinsics, sparse motion control, video editing, and, to our knowledge, the first modular audio-visual controls for a joint generation model. Our method is both compute- and data-efficient: each modality requires only a small dataset and converges within a few hundred to a few thousand training steps, a fraction of the budget of monolithic alternatives. We publicly release our code and trained LoRA checkpoints.
Clear Skies Ahead: Towards Real-Time Automatic Sky Replacement in Video
Mar 06, 2019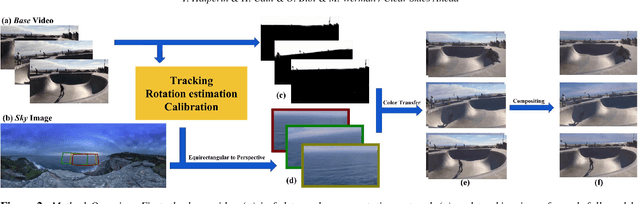
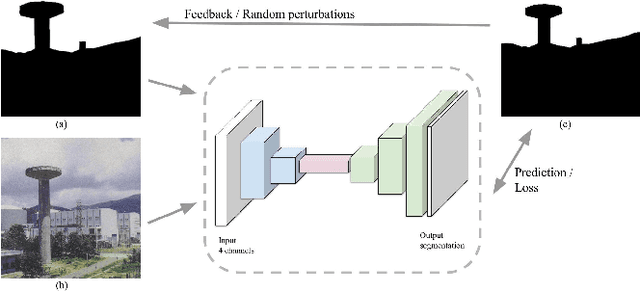


Digital videos such as those captured by a smartphone often exhibit exposure inconsistencies, a poorly exposed sky, or simply suffer from an uninteresting or plain looking sky. Professionals may edit these videos using advanced and time-consuming tools unavailable to most users, to replace the sky with a more expressive or imaginative sky. In this work, we propose an algorithm for automatic replacement of the sky region in a video with a different sky, providing nonprofessional users with a simple yet efficient tool to seamlessly replace the sky. The method is fast, achieving close to real-time performance on mobile devices and the user's involvement can remain as limited as simply selecting the replacement sky.