 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBengali Handwritten Grapheme Classification: Deep Learning Approach
Nov 16, 2021
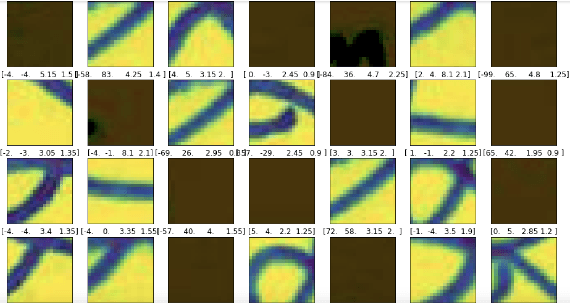
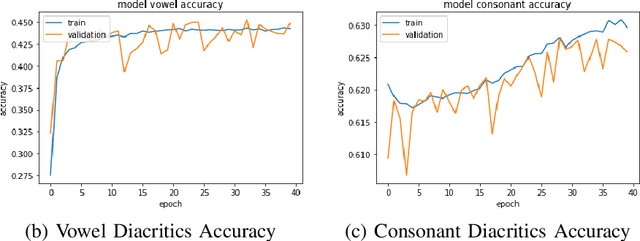
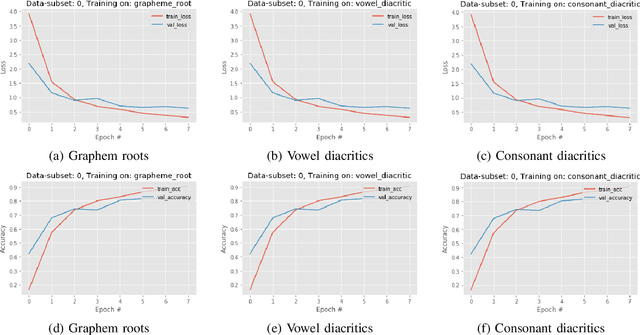
Despite being one of the most spoken languages in the world ($6^{th}$ based on population), research regarding Bengali handwritten grapheme (smallest functional unit of a writing system) classification has not been explored widely compared to other prominent languages. Moreover, the large number of combinations of graphemes in the Bengali language makes this classification task very challenging. With an effort to contribute to this research problem, we participate in a Kaggle competition \cite{kaggle_link} where the challenge is to separately classify three constituent elements of a Bengali grapheme in the image: grapheme root, vowel diacritics, and consonant diacritics. We explore the performances of some existing neural network models such as Multi-Layer Perceptron (MLP) and state of the art ResNet50. To further improve the performance we propose our own convolution neural network (CNN) model for Bengali grapheme classification with validation root accuracy 95.32\%, vowel accuracy 98.61\%, and consonant accuracy 98.76\%. We also explore Region Proposal Network (RPN) using VGGNet with a limited setting that can be a potential future direction to improve the performance.
Communication-Efficient Sampling for Distributed Training of Graph Convolutional Networks
Jan 19, 2021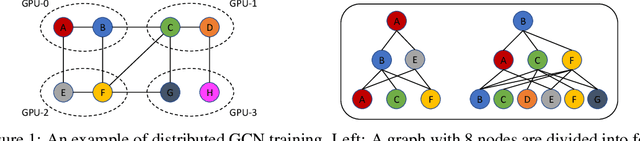
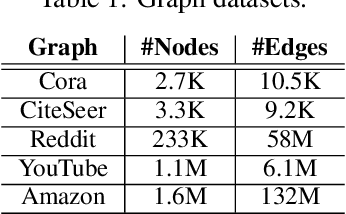
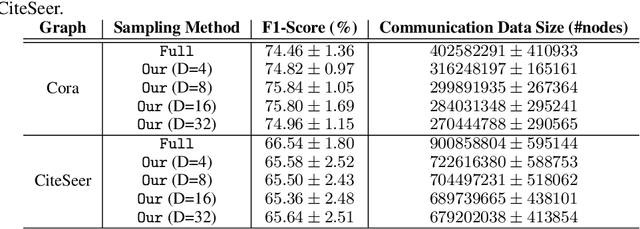
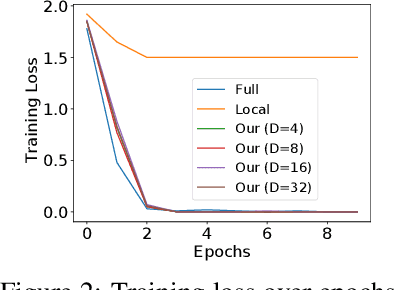
Training Graph Convolutional Networks (GCNs) is expensive as it needs to aggregate data recursively from neighboring nodes. To reduce the computation overhead, previous works have proposed various neighbor sampling methods that estimate the aggregation result based on a small number of sampled neighbors. Although these methods have successfully accelerated the training, they mainly focus on the single-machine setting. As real-world graphs are large, training GCNs in distributed systems is desirable. However, we found that the existing neighbor sampling methods do not work well in a distributed setting. Specifically, a naive implementation may incur a huge amount of communication of feature vectors among different machines. To address this problem, we propose a communication-efficient neighbor sampling method in this work. Our main idea is to assign higher sampling probabilities to the local nodes so that remote nodes are accessed less frequently. We present an algorithm that determines the local sampling probabilities and makes sure our skewed neighbor sampling does not affect much the convergence of the training. Our experiments with node classification benchmarks show that our method significantly reduces the communication overhead for distributed GCN training with little accuracy loss.