 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Wise Activation Steering for Honest Language Models
Dec 08, 2025Large language models sometimes assert falsehoods despite internally representing the correct answer, failures of honesty rather than accuracy, which undermines auditability and safety. Existing approaches largely optimize factual correctness or depend on retraining and brittle single-layer edits, offering limited leverage over truthful reporting. We present a training-free activation steering method that weights steering strength across network depth using a Gaussian schedule. On the MASK benchmark, which separates honesty from knowledge, we evaluate seven models spanning the LLaMA, Qwen, and Mistral families and find that Gaussian scheduling improves honesty over no-steering and single-layer baselines in six of seven models. Equal-budget ablations on LLaMA-3.1-8B-Instruct and Qwen-2.5-7B-Instruct show the Gaussian schedule outperforms random, uniform, and box-filter depth allocations, indicating that how intervention is distributed across depth materially affects outcomes beyond total strength. The method is simple, model-agnostic, requires no finetuning, and provides a low-cost control knob for eliciting truthful reporting from models' existing capabilities.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
3D G-CNNs for Pulmonary Nodule Detection
Apr 12, 2018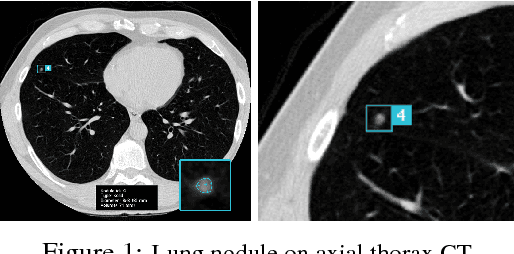
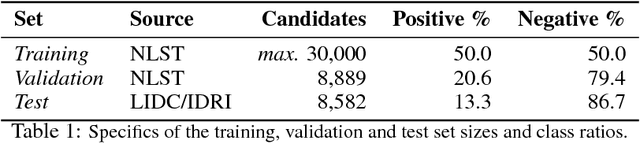
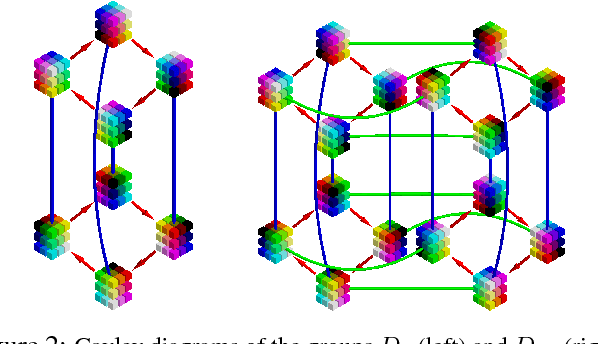
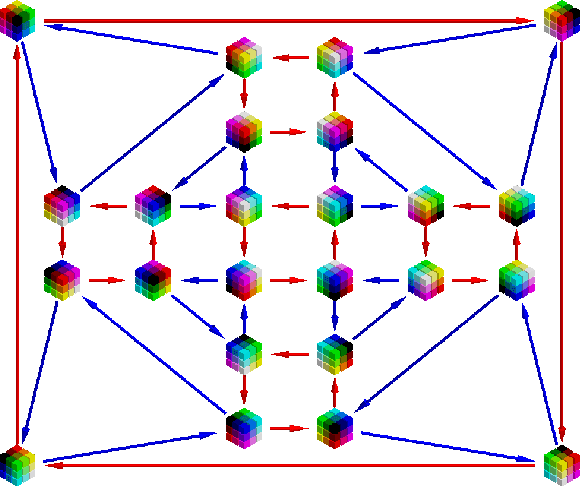
Convolutional Neural Networks (CNNs) require a large amount of annotated data to learn from, which is often difficult to obtain in the medical domain. In this paper we show that the sample complexity of CNNs can be significantly improved by using 3D roto-translation group convolutions (G-Convs) instead of the more conventional translational convolutions. These 3D G-CNNs were applied to the problem of false positive reduction for pulmonary nodule detection, and proved to be substantially more effective in terms of performance, sensitivity to malignant nodules, and speed of convergence compared to a strong and comparable baseline architecture with regular convolutions, data augmentation and a similar number of parameters. For every dataset size tested, the G-CNN achieved a FROC score close to the CNN trained on ten times more data.