 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Graph Neural Networks for Graph Summarization
Feb 13, 2023



As large-scale graphs become more widespread today, it exposes computational challenges to extract, process, and interpret large graph data. It is therefore natural to search for ways to summarize the original graph while maintaining its key characteristics. In this survey, we outline the most current progress of deep learning on graphs for graph summarization explicitly concentrating on Graph Neural Networks (GNNs) methods. We structure the paper into four categories, including graph recurrent networks, graph convolutional networks, graph autoencoders, and graph attention networks. We also discuss a new booming line of research which is elaborating on using graph reinforcement learning for evaluating and improving the quality of graph summaries. Finally, we conclude this survey and discuss a number of open research challenges that would motivate further study in this area.
Towards Knowledge-based Mining of Mental Disorder Patterns from Textual Data
Jul 07, 2022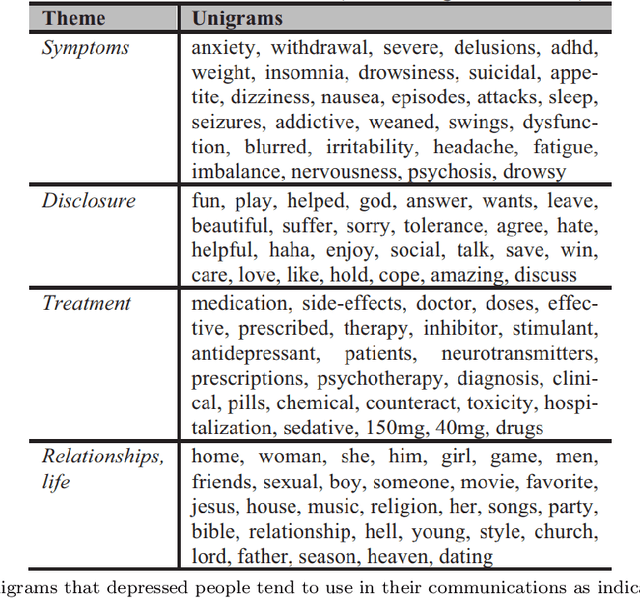



Mental health disorders may cause severe consequences on all the countries' economies and health. For example, the impacts of the COVID-19 pandemic, such as isolation and travel ban, can make us feel depressed. Identifying early signs of mental health disorders is vital. For example, depression may increase an individual's risk of suicide. The state-of-the-art research in identifying mental disorder patterns from textual data, uses hand-labelled training sets, especially when a domain expert's knowledge is required to analyse various symptoms. This task could be time-consuming and expensive. To address this challenge, in this paper, we study and analyse the various clinical and non-clinical approaches to identifying mental health disorders. We leverage the domain knowledge and expertise in cognitive science to build a domain-specific Knowledge Base (KB) for the mental health disorder concepts and patterns. We present a weaker form of supervision by facilitating the generating of training data from a domain-specific Knowledge Base (KB). We adopt a typical scenario for analysing social media to identify major depressive disorder symptoms from the textual content generated by social users. We use this scenario to evaluate how our knowledge-based approach significantly improves the quality of results.