 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Aware Testing of Neural Networks Using Generative Models
Feb 26, 2021


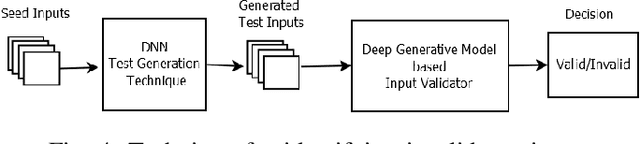
The reliability of software that has a Deep Neural Network (DNN) as a component is urgently important today given the increasing number of critical applications being deployed with DNNs. The need for reliability raises a need for rigorous testing of the safety and trustworthiness of these systems. In the last few years, there have been a number of research efforts focused on testing DNNs. However the test generation techniques proposed so far lack a check to determine whether the test inputs they are generating are valid, and thus invalid inputs are produced. To illustrate this situation, we explored three recent DNN testing techniques. Using deep generative model based input validation, we show that all the three techniques generate significant number of invalid test inputs. We further analyzed the test coverage achieved by the test inputs generated by the DNN testing techniques and showed how invalid test inputs can falsely inflate test coverage metrics. To overcome the inclusion of invalid inputs in testing, we propose a technique to incorporate the valid input space of the DNN model under test in the test generation process. Our technique uses a deep generative model-based algorithm to generate only valid inputs. Results of our empirical studies show that our technique is effective in eliminating invalid tests and boosting the number of valid test inputs generated.
Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers
May 23, 2018
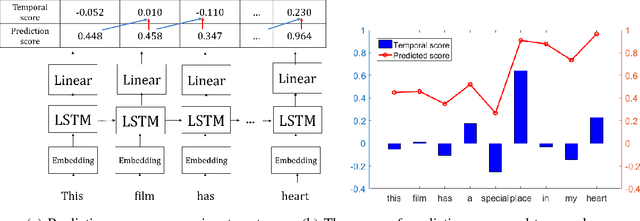
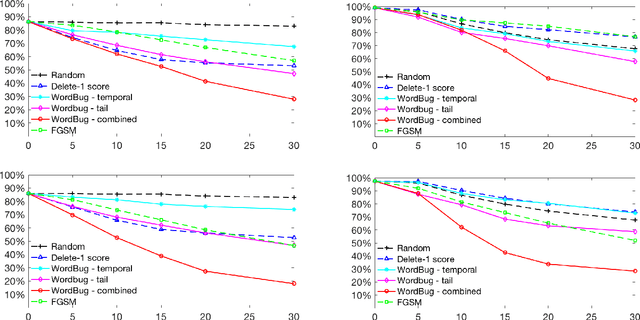
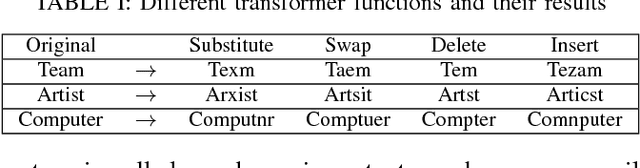
Although various techniques have been proposed to generate adversarial samples for white-box attacks on text, little attention has been paid to black-box attacks, which are more realistic scenarios. In this paper, we present a novel algorithm, DeepWordBug, to effectively generate small text perturbations in a black-box setting that forces a deep-learning classifier to misclassify a text input. We employ novel scoring strategies to identify the critical tokens that, if modified, cause the classifier to make an incorrect prediction. Simple character-level transformations are applied to the highest-ranked tokens in order to minimize the edit distance of the perturbation, yet change the original classification. We evaluated DeepWordBug on eight real-world text datasets, including text classification, sentiment analysis, and spam detection. We compare the result of DeepWordBug with two baselines: Random (Black-box) and Gradient (White-box). Our experimental results indicate that DeepWordBug reduces the prediction accuracy of current state-of-the-art deep-learning models, including a decrease of 68\% on average for a Word-LSTM model and 48\% on average for a Char-CNN model.