 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Trimmed Lasso: Sparsity and Robustness
Aug 15, 2017
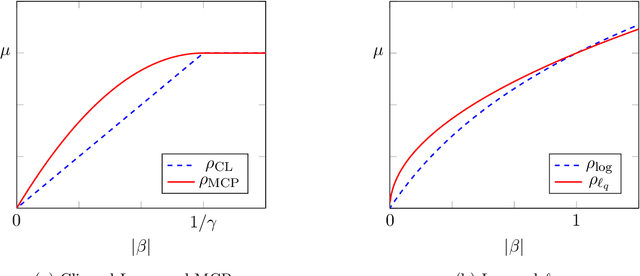

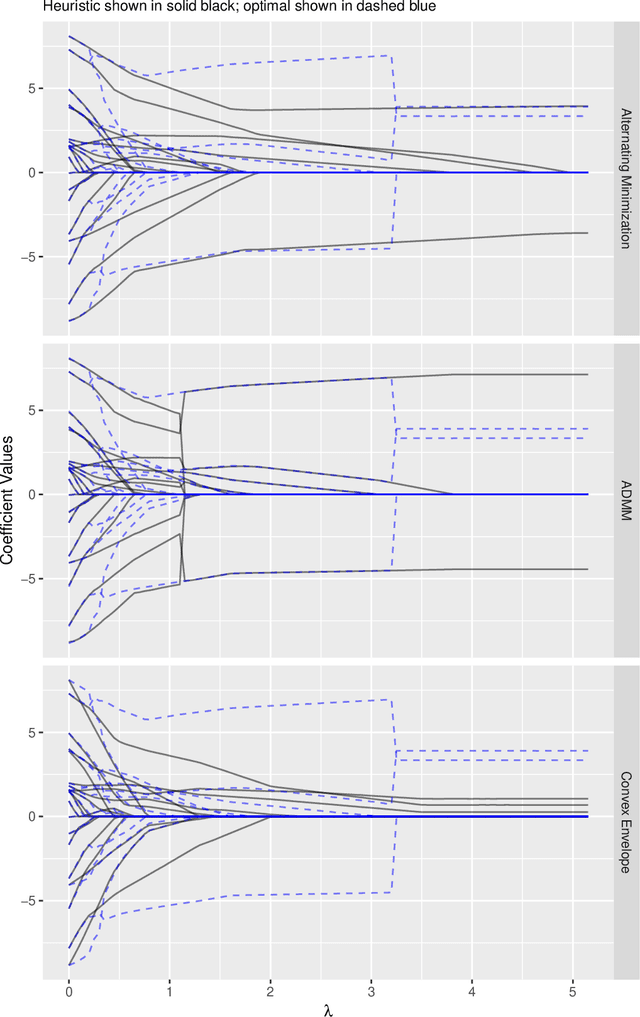
Nonconvex penalty methods for sparse modeling in linear regression have been a topic of fervent interest in recent years. Herein, we study a family of nonconvex penalty functions that we call the trimmed Lasso and that offers exact control over the desired level of sparsity of estimators. We analyze its structural properties and in doing so show the following: 1) Drawing parallels between robust statistics and robust optimization, we show that the trimmed-Lasso-regularized least squares problem can be viewed as a generalized form of total least squares under a specific model of uncertainty. In contrast, this same model of uncertainty, viewed instead through a robust optimization lens, leads to the convex SLOPE (or OWL) penalty. 2) Further, in relating the trimmed Lasso to commonly used sparsity-inducing penalty functions, we provide a succinct characterization of the connection between trimmed-Lasso- like approaches and penalty functions that are coordinate-wise separable, showing that the trimmed penalties subsume existing coordinate-wise separable penalties, with strict containment in general. 3) Finally, we describe a variety of exact and heuristic algorithms, both existing and new, for trimmed Lasso regularized estimation problems. We include a comparison between the different approaches and an accompanying implementation of the algorithms.
Characterization of the equivalence of robustification and regularization in linear and matrix regression
Feb 25, 2017


The notion of developing statistical methods in machine learning which are robust to adversarial perturbations in the underlying data has been the subject of increasing interest in recent years. A common feature of this work is that the adversarial robustification often corresponds exactly to regularization methods which appear as a loss function plus a penalty. In this paper we deepen and extend the understanding of the connection between robustification and regularization (as achieved by penalization) in regression problems. Specifically, (a) in the context of linear regression, we characterize precisely under which conditions on the model of uncertainty used and on the loss function penalties robustification and regularization are equivalent, and (b) we extend the characterization of robustification and regularization to matrix regression problems (matrix completion and Principal Component Analysis).