 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoogle Crowdsourced Speech Corpora and Related Open-Source Resources for Low-Resource Languages and Dialects: An Overview
Oct 14, 2020This paper presents an overview of a program designed to address the growing need for developing freely available speech resources for under-represented languages. At present we have released 38 datasets for building text-to-speech and automatic speech recognition applications for languages and dialects of South and Southeast Asia, Africa, Europe and South America. The paper describes the methodology used for developing such corpora and presents some of our findings that could benefit under-represented language communities.
Towards Induction of Structured Phoneme Inventories
Oct 12, 2020This extended abstract surveying the work on phonological typology was prepared for "SIGTYP 2020: The Second Workshop on Computational Research in Linguistic Typology" to be held at EMNLP 2020.
Linguistic Typology Features from Text: Inferring the Sparse Features of World Atlas of Language Structures
May 04, 2020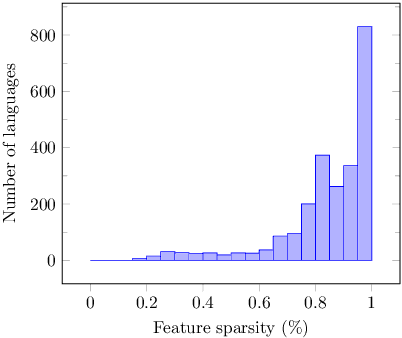
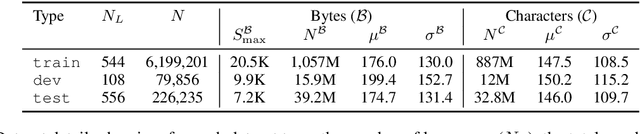
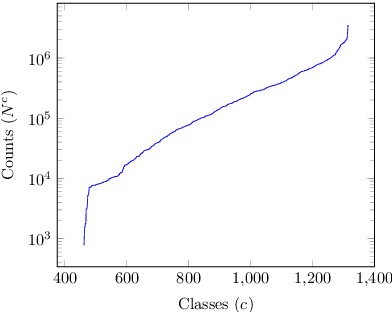
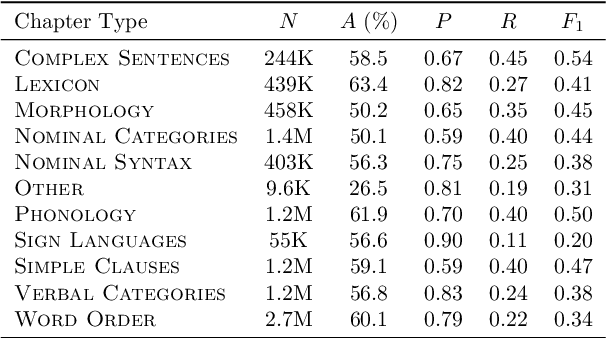
The use of linguistic typological resources in natural language processing has been steadily gaining more popularity. It has been observed that the use of typological information, often combined with distributed language representations, leads to significantly more powerful models. While linguistic typology representations from various resources have mostly been used for conditioning the models, there has been relatively little attention on predicting features from these resources from the input data. In this paper we investigate whether the various linguistic features from World Atlas of Language Structures (WALS) can be reliably inferred from multi-lingual text. Such a predictor can be used to infer structural features for a language never observed in training data. We frame this task as a multi-label classification involving predicting the set of non-mutually exclusive and extremely sparse multi-valued labels (WALS features). We construct a recurrent neural network predictor based on byte embeddings and convolutional layers and test its performance on 556 languages, providing analysis for various linguistic types, macro-areas, language families and individual features. We show that some features from various linguistic types can be predicted reliably.
Sampling from Stochastic Finite Automata with Applications to CTC Decoding
May 21, 2019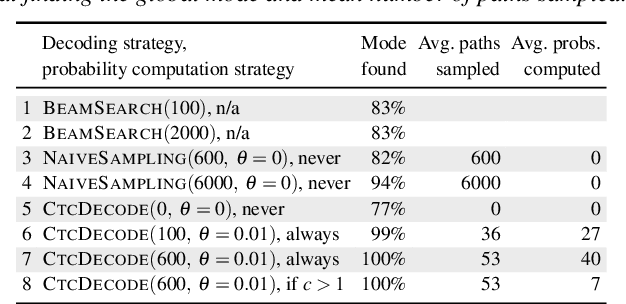
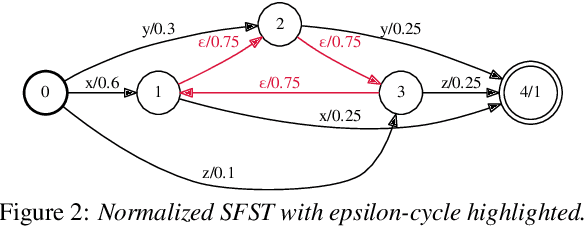
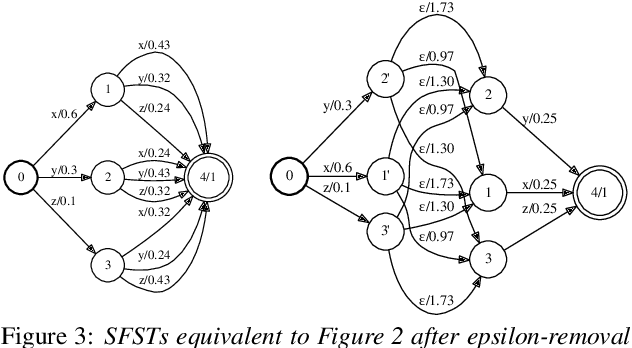
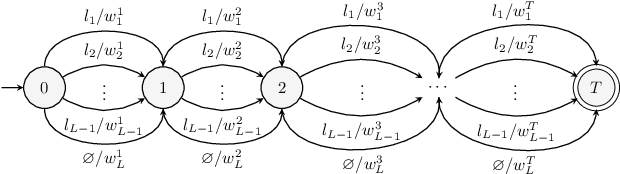
Stochastic finite automata arise naturally in many language and speech processing tasks. They include stochastic acceptors, which represent certain probability distributions over random strings. We consider the problem of efficient sampling: drawing random string variates from the probability distribution represented by stochastic automata and transformations of those. We show that path-sampling is effective and can be efficient if the epsilon-graph of a finite automaton is acyclic. We provide an algorithm that ensures this by conflating epsilon-cycles within strongly connected components. Sampling is also effective in the presence of non-injective transformations of strings. We illustrate this in the context of decoding for Connectionist Temporal Classification (CTC), where the predictive probabilities yield auxiliary sequences which are transformed into shorter labeling strings. We can sample efficiently from the transformed labeling distribution and use this in two different strategies for finding the most probable CTC labeling.