 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Groundedness of Legal Question-Answering Systems
Oct 11, 2024



In high-stakes domains like legal question-answering, the accuracy and trustworthiness of generative AI systems are of paramount importance. This work presents a comprehensive benchmark of various methods to assess the groundedness of AI-generated responses, aiming to significantly enhance their reliability. Our experiments include similarity-based metrics and natural language inference models to evaluate whether responses are well-founded in the given contexts. We also explore different prompting strategies for large language models to improve the detection of ungrounded responses. We validated the effectiveness of these methods using a newly created grounding classification corpus, designed specifically for legal queries and corresponding responses from retrieval-augmented prompting, focusing on their alignment with source material. Our results indicate potential in groundedness classification of generated responses, with the best method achieving a macro-F1 score of 0.8. Additionally, we evaluated the methods in terms of their latency to determine their suitability for real-world applications, as this step typically follows the generation process. This capability is essential for processes that may trigger additional manual verification or automated response regeneration. In summary, this study demonstrates the potential of various detection methods to improve the trustworthiness of generative AI in legal settings.
Can't Remember Details in Long Documents? You Need Some R&R
Mar 08, 2024Long-context large language models (LLMs) hold promise for tasks such as question-answering (QA) over long documents, but they tend to miss important information in the middle of context documents (arXiv:2307.03172v3). Here, we introduce $\textit{R&R}$ -- a combination of two novel prompt-based methods called $\textit{reprompting}$ and $\textit{in-context retrieval}$ (ICR) -- to alleviate this effect in document-based QA. In reprompting, we repeat the prompt instructions periodically throughout the context document to remind the LLM of its original task. In ICR, rather than instructing the LLM to answer the question directly, we instruct it to retrieve the top $k$ passage numbers most relevant to the given question, which are then used as an abbreviated context in a second QA prompt. We test R&R with GPT-4 Turbo and Claude-2.1 on documents up to 80k tokens in length and observe a 16-point boost in QA accuracy on average. Our further analysis suggests that R&R improves performance on long document-based QA because it reduces the distance between relevant context and the instructions. Finally, we show that compared to short-context chunkwise methods, R&R enables the use of larger chunks that cost fewer LLM calls and output tokens, while minimizing the drop in accuracy.
Transformer Based Language Models for Similar Text Retrieval and Ranking
May 21, 2020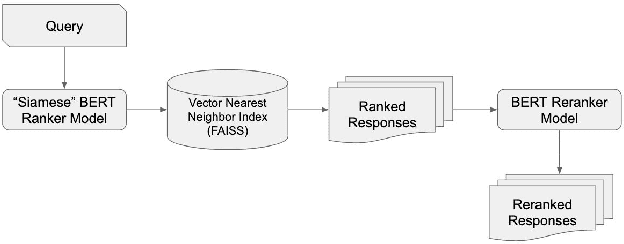
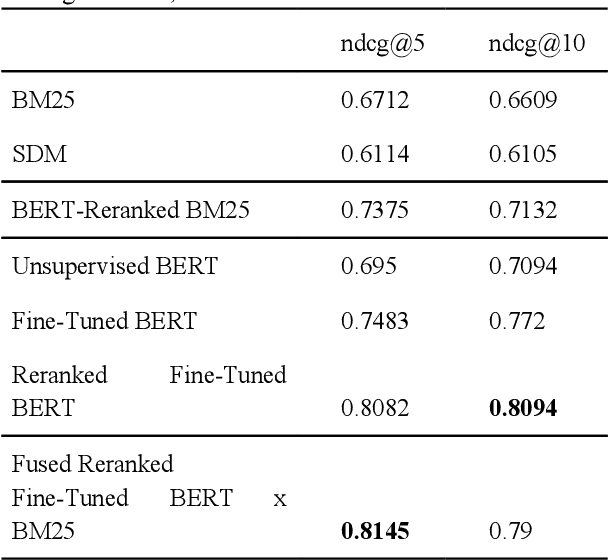
Most approaches for similar text retrieval and ranking with long natural language queries rely at some level on queries and responses having words in common with each other. Recent applications of transformer-based neural language models to text retrieval and ranking problems have been very promising, but still involve a two-step process in which result candidates are first obtained through bag-of-words-based approaches, and then reranked by a neural transformer. In this paper, we introduce novel approaches for effectively applying neural transformer models to similar text retrieval and ranking without an initial bag-of-words-based step. By eliminating the bag-of-words-based step, our approach is able to accurately retrieve and rank results even when they have no non-stopwords in common with the query. We accomplish this by using bidirectional encoder representations from transformers (BERT) to create vectorized representations of sentence-length texts, along with a vector nearest neighbor search index. We demonstrate both supervised and unsupervised means of using BERT to accomplish this task.