 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransClean: Finding False Positives in Multi-Source Entity Matching under Real-World Conditions via Transitive Consistency
Jun 04, 2025



We present TransClean, a method for detecting false positive predictions of entity matching algorithms under real-world conditions characterized by large-scale, noisy, and unlabeled multi-source datasets that undergo distributional shifts. TransClean is explicitly designed to operate with multiple data sources in an efficient, robust and fast manner while accounting for edge cases and requiring limited manual labeling. TransClean leverages the Transitive Consistency of a matching, a measure of the consistency of a pairwise matching model f_theta on the matching it produces G_f_theta, based both on its predictions on directly evaluated record pairs and its predictions on implied record pairs. TransClean iteratively modifies a matching through gradually removing false positive matches while removing as few true positive matches as possible. In each of these steps, the estimation of the Transitive Consistency is exclusively done through model evaluations and produces quantities that can be used as proxies of the amounts of true and false positives in the matching while not requiring any manual labeling, producing an estimate of the quality of the matching and indicating which record groups are likely to contain false positives. In our experiments, we compare combining TransClean with a naively trained pairwise matching model (DistilBERT) and with a state-of-the-art end-to-end matching method (CLER) and illustrate the flexibility of TransClean in being able to detect most of the false positives of either setup across a variety of datasets. Our experiments show that TransClean induces an average +24.42 F1 score improvement for entity matching in a multi-source setting when compared to traditional pair-wise matching algorithms.
GraLMatch: Matching Groups of Entities with Graphs and Language Models
Jun 21, 2024



In this paper, we present an end-to-end multi-source Entity Matching problem, which we call entity group matching, where the goal is to assign to the same group, records originating from multiple data sources but representing the same real-world entity. We focus on the effects of transitively matched records, i.e. the records connected by paths in the graph G = (V,E) whose nodes and edges represent the records and whether they are a match or not. We present a real-world instance of this problem, where the challenge is to match records of companies and financial securities originating from different data providers. We also introduce two new multi-source benchmark datasets that present similar matching challenges as real-world records. A distinctive characteristic of these records is that they are regularly updated following real-world events, but updates are not applied uniformly across data sources. This phenomenon makes the matching of certain groups of records only possible through the use of transitive information. In our experiments, we illustrate how considering transitively matched records is challenging since a limited amount of false positive pairwise match predictions can throw off the group assignment of large quantities of records. Thus, we propose GraLMatch, a method that can partially detect and remove false positive pairwise predictions through graph-based properties. Finally, we showcase how fine-tuning a Transformer-based model (DistilBERT) on a reduced number of labeled samples yields a better final entity group matching than training on more samples and/or incorporating fine-tuning optimizations, illustrating how precision becomes the deciding factor in the entity group matching of large volumes of records.
INODE: Building an End-to-End Data Exploration System in Practice
Apr 09, 2021
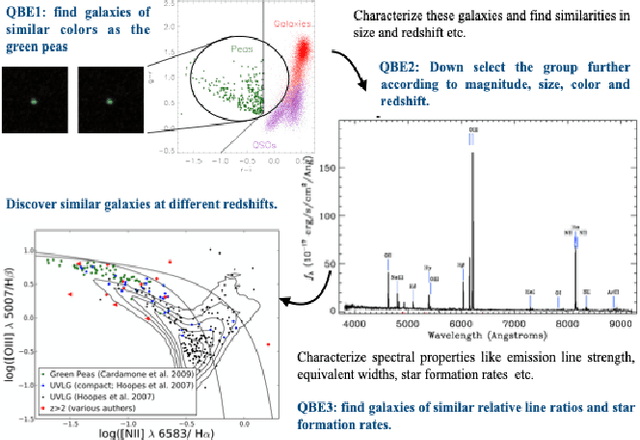
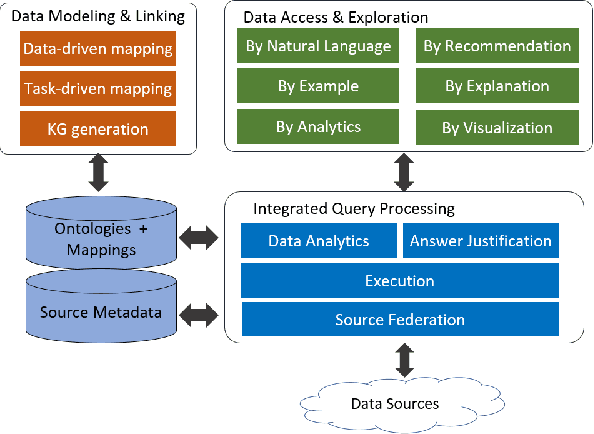

A full-fledged data exploration system must combine different access modalities with a powerful concept of guiding the user in the exploration process, by being reactive and anticipative both for data discovery and for data linking. Such systems are a real opportunity for our community to cater to users with different domain and data science expertise. We introduce INODE -- an end-to-end data exploration system -- that leverages, on the one hand, Machine Learning and, on the other hand, semantics for the purpose of Data Management (DM). Our vision is to develop a classic unified, comprehensive platform that provides extensive access to open datasets, and we demonstrate it in three significant use cases in the fields of Cancer Biomarker Reearch, Research and Innovation Policy Making, and Astrophysics. INODE offers sustainable services in (a) data modeling and linking, (b) integrated query processing using natural language, (c) guidance, and (d) data exploration through visualization, thus facilitating the user in discovering new insights. We demonstrate that our system is uniquely accessible to a wide range of users from larger scientific communities to the public. Finally, we briefly illustrate how this work paves the way for new research opportunities in DM.