 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransClean: Finding False Positives in Multi-Source Entity Matching under Real-World Conditions via Transitive Consistency
Jun 04, 2025



We present TransClean, a method for detecting false positive predictions of entity matching algorithms under real-world conditions characterized by large-scale, noisy, and unlabeled multi-source datasets that undergo distributional shifts. TransClean is explicitly designed to operate with multiple data sources in an efficient, robust and fast manner while accounting for edge cases and requiring limited manual labeling. TransClean leverages the Transitive Consistency of a matching, a measure of the consistency of a pairwise matching model f_theta on the matching it produces G_f_theta, based both on its predictions on directly evaluated record pairs and its predictions on implied record pairs. TransClean iteratively modifies a matching through gradually removing false positive matches while removing as few true positive matches as possible. In each of these steps, the estimation of the Transitive Consistency is exclusively done through model evaluations and produces quantities that can be used as proxies of the amounts of true and false positives in the matching while not requiring any manual labeling, producing an estimate of the quality of the matching and indicating which record groups are likely to contain false positives. In our experiments, we compare combining TransClean with a naively trained pairwise matching model (DistilBERT) and with a state-of-the-art end-to-end matching method (CLER) and illustrate the flexibility of TransClean in being able to detect most of the false positives of either setup across a variety of datasets. Our experiments show that TransClean induces an average +24.42 F1 score improvement for entity matching in a multi-source setting when compared to traditional pair-wise matching algorithms.
A Modular Framework for Reinforcement Learning Optimal Execution
Aug 11, 2022
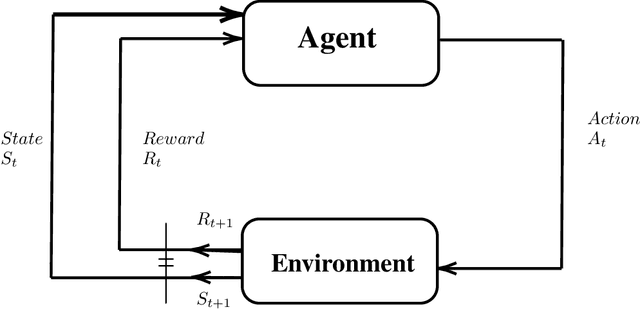
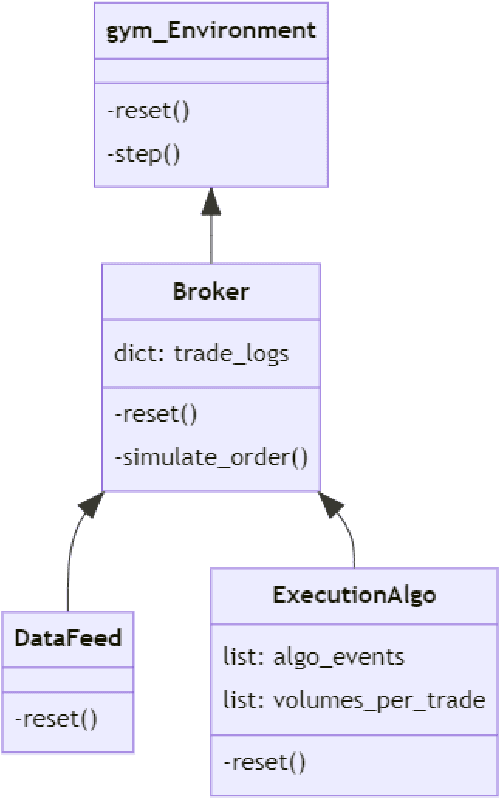
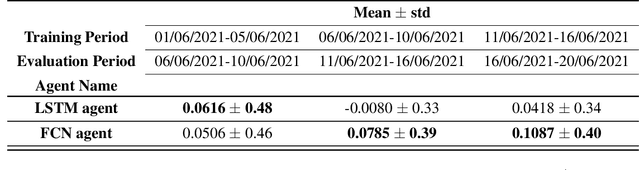
In this article, we develop a modular framework for the application of Reinforcement Learning to the problem of Optimal Trade Execution. The framework is designed with flexibility in mind, in order to ease the implementation of different simulation setups. Rather than focusing on agents and optimization methods, we focus on the environment and break down the necessary requirements to simulate an Optimal Trade Execution under a Reinforcement Learning framework such as data pre-processing, construction of observations, action processing, child order execution, simulation of benchmarks, reward calculations etc. We give examples of each component, explore the difficulties their individual implementations \& the interactions between them entail, and discuss the different phenomena that each component induces in the simulation, highlighting the divergences between the simulation and the behavior of a real market. We showcase our modular implementation through a setup that, following a Time-Weighted Average Price (TWAP) order submission schedule, allows the agent to exclusively place limit orders, simulates their execution via iterating over snapshots of the Limit Order Book (LOB), and calculates rewards as the \$ improvement over the price achieved by a TWAP benchmark algorithm following the same schedule. We also develop evaluation procedures that incorporate iterative re-training and evaluation of a given agent over intervals of a training horizon, mimicking how an agent may behave when being continuously retrained as new market data becomes available and emulating the monitoring practices that algorithm providers are bound to perform under current regulatory frameworks.