 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics or spelling? Probing contextual word embeddings with orthographic noise
Aug 08, 2024



Pretrained language model (PLM) hidden states are frequently employed as contextual word embeddings (CWE): high-dimensional representations that encode semantic information given linguistic context. Across many areas of computational linguistics research, similarity between CWEs is interpreted as semantic similarity. However, it remains unclear exactly what information is encoded in PLM hidden states. We investigate this practice by probing PLM representations using minimal orthographic noise. We expect that if CWEs primarily encode semantic information, a single character swap in the input word will not drastically affect the resulting representation,given sufficient linguistic context. Surprisingly, we find that CWEs generated by popular PLMs are highly sensitive to noise in input data, and that this sensitivity is related to subword tokenization: the fewer tokens used to represent a word at input, the more sensitive its corresponding CWE. This suggests that CWEs capture information unrelated to word-level meaning and can be manipulated through trivial modifications of input data. We conclude that these PLM-derived CWEs may not be reliable semantic proxies, and that caution is warranted when interpreting representational similarity
Code-switching in text and speech reveals information-theoretic audience design
Aug 08, 2024In this work, we use language modeling to investigate the factors that influence code-switching. Code-switching occurs when a speaker alternates between one language variety (the primary language) and another (the secondary language), and is widely observed in multilingual contexts. Recent work has shown that code-switching is often correlated with areas of high information load in the primary language, but it is unclear whether high primary language load only makes the secondary language relatively easier to produce at code-switching points (speaker-driven code-switching), or whether code-switching is additionally used by speakers to signal the need for greater attention on the part of listeners (audience-driven code-switching). In this paper, we use bilingual Chinese-English online forum posts and transcripts of spontaneous Chinese-English speech to replicate prior findings that high primary language (Chinese) information load is correlated with switches to the secondary language (English). We then demonstrate that the information load of the English productions is even higher than that of meaning equivalent Chinese alternatives, and these are therefore not easier to produce, providing evidence of audience-driven influences in code-switching at the level of the communication channel, not just at the sociolinguistic level, in both writing and speech.
Does Dependency Locality Predict Non-canonical Word Order in Hindi?
May 13, 2024Previous work has shown that isolated non-canonical sentences with Object-before-Subject (OSV) order are initially harder to process than their canonical counterparts with Subject-before-Object (SOV) order. Although this difficulty diminishes with appropriate discourse context, the underlying cognitive factors responsible for alleviating processing challenges in OSV sentences remain a question. In this work, we test the hypothesis that dependency length minimization is a significant predictor of non-canonical (OSV) syntactic choices, especially when controlling for information status such as givenness and surprisal measures. We extract sentences from the Hindi-Urdu Treebank corpus (HUTB) that contain clearly-defined subjects and objects, systematically permute the preverbal constituents of those sentences, and deploy a classifier to distinguish between original corpus sentences and artificially generated alternatives. The classifier leverages various discourse-based and cognitive features, including dependency length, surprisal, and information status, to inform its predictions. Our results suggest that, although there exists a preference for minimizing dependency length in non-canonical corpus sentences amidst the generated variants, this factor does not significantly contribute in identifying corpus sentences above and beyond surprisal and givenness measures. Notably, discourse predictability emerges as the primary determinant of constituent-order preferences. These findings are further supported by human evaluations involving 44 native Hindi speakers. Overall, this work sheds light on the role of expectation adaptation in word-ordering decisions. We conclude by situating our results within the theories of discourse production and information locality.
Dual Mechanism Priming Effects in Hindi Word Order
Oct 25, 2022Word order choices during sentence production can be primed by preceding sentences. In this work, we test the DUAL MECHANISM hypothesis that priming is driven by multiple different sources. Using a Hindi corpus of text productions, we model lexical priming with an n-gram cache model and we capture more abstract syntactic priming with an adaptive neural language model. We permute the preverbal constituents of corpus sentences, and then use a logistic regression model to predict which sentences actually occurred in the corpus against artificially generated meaning-equivalent variants. Our results indicate that lexical priming and lexically-independent syntactic priming affect complementary sets of verb classes. By showing that different priming influences are separable from one another, our results support the hypothesis that multiple different cognitive mechanisms underlie priming.
Discourse Context Predictability Effects in Hindi Word Order
Oct 25, 2022We test the hypothesis that discourse predictability influences Hindi syntactic choice. While prior work has shown that a number of factors (e.g., information status, dependency length, and syntactic surprisal) influence Hindi word order preferences, the role of discourse predictability is underexplored in the literature. Inspired by prior work on syntactic priming, we investigate how the words and syntactic structures in a sentence influence the word order of the following sentences. Specifically, we extract sentences from the Hindi-Urdu Treebank corpus (HUTB), permute the preverbal constituents of those sentences, and build a classifier to predict which sentences actually occurred in the corpus against artificially generated distractors. The classifier uses a number of discourse-based features and cognitive features to make its predictions, including dependency length, surprisal, and information status. We find that information status and LSTM-based discourse predictability influence word order choices, especially for non-canonical object-fronted orders. We conclude by situating our results within the broader syntactic priming literature.
All Bark and No Bite: Rogue Dimensions in Transformer Language Models Obscure Representational Quality
Sep 09, 2021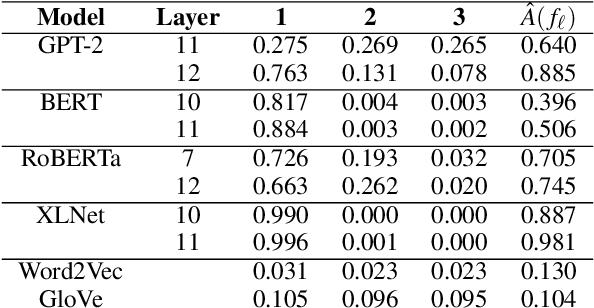
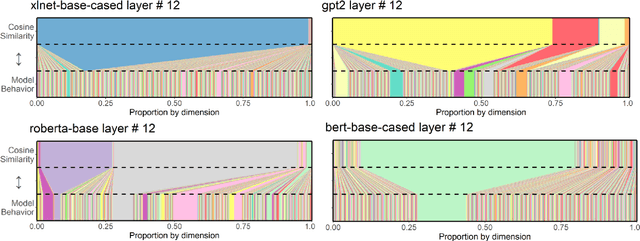
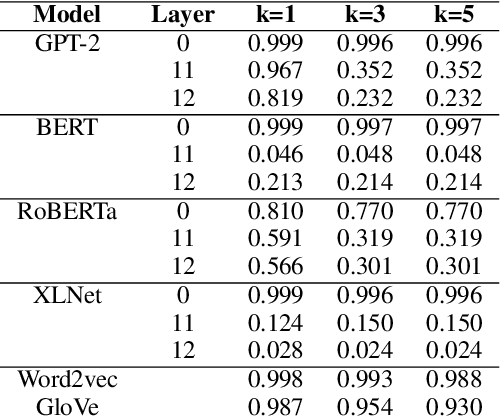
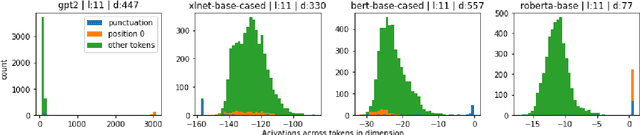
Similarity measures are a vital tool for understanding how language models represent and process language. Standard representational similarity measures such as cosine similarity and Euclidean distance have been successfully used in static word embedding models to understand how words cluster in semantic space. Recently, these measures have been applied to embeddings from contextualized models such as BERT and GPT-2. In this work, we call into question the informativity of such measures for contextualized language models. We find that a small number of rogue dimensions, often just 1-3, dominate these measures. Moreover, we find a striking mismatch between the dimensions that dominate similarity measures and those which are important to the behavior of the model. We show that simple postprocessing techniques such as standardization are able to correct for rogue dimensions and reveal underlying representational quality. We argue that accounting for rogue dimensions is essential for any similarity-based analysis of contextual language models.
Uncovering Constraint-Based Behavior in Neural Models via Targeted Fine-Tuning
Jun 02, 2021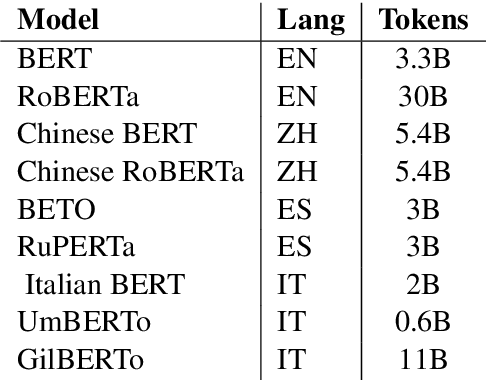
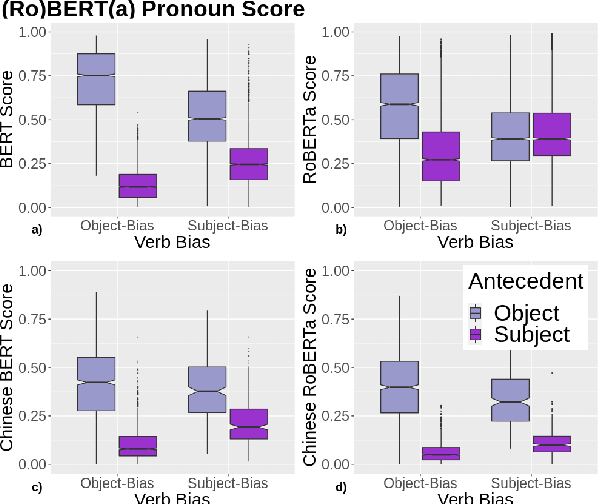
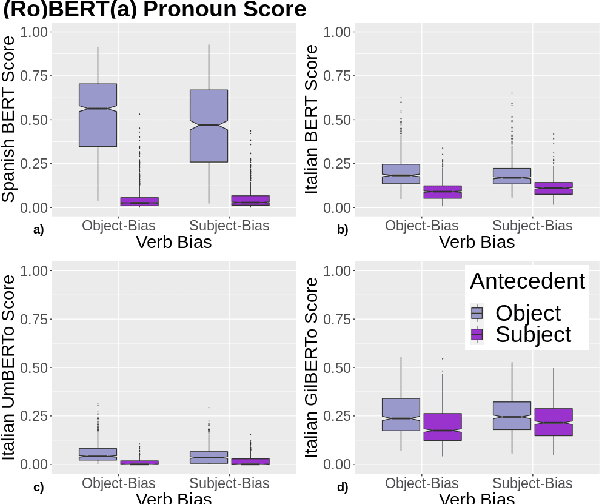
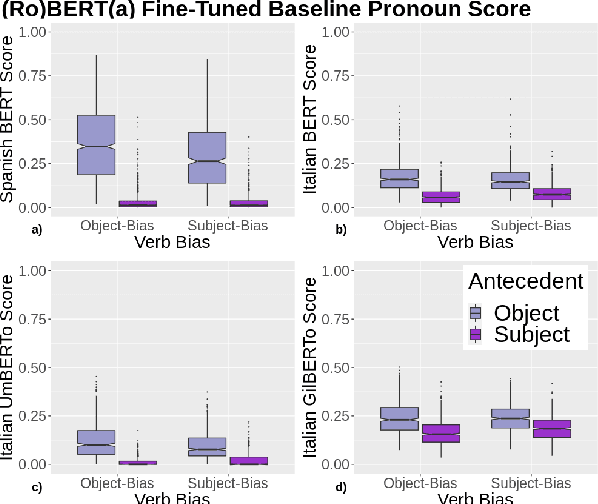
A growing body of literature has focused on detailing the linguistic knowledge embedded in large, pretrained language models. Existing work has shown that non-linguistic biases in models can drive model behavior away from linguistic generalizations. We hypothesized that competing linguistic processes within a language, rather than just non-linguistic model biases, could obscure underlying linguistic knowledge. We tested this claim by exploring a single phenomenon in four languages: English, Chinese, Spanish, and Italian. While human behavior has been found to be similar across languages, we find cross-linguistic variation in model behavior. We show that competing processes in a language act as constraints on model behavior and demonstrate that targeted fine-tuning can re-weight the learned constraints, uncovering otherwise dormant linguistic knowledge in models. Our results suggest that models need to learn both the linguistic constraints in a language and their relative ranking, with mismatches in either producing non-human-like behavior.
Discourse structure interacts with reference but not syntax in neural language models
Oct 10, 2020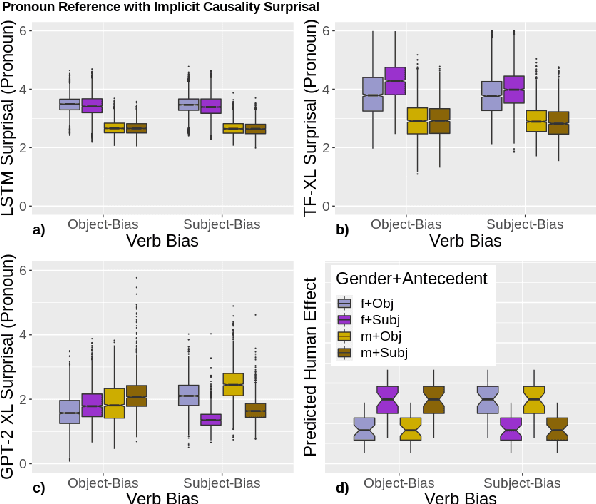
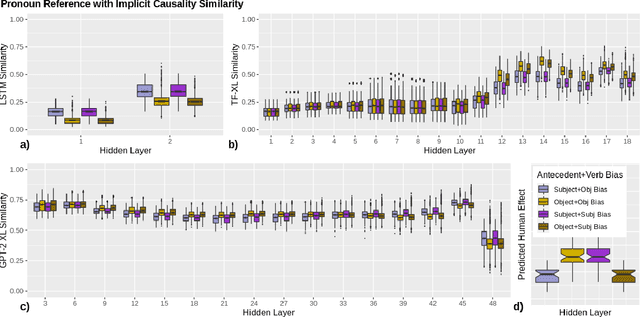
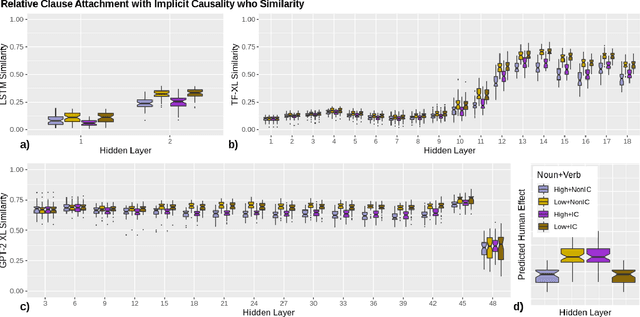
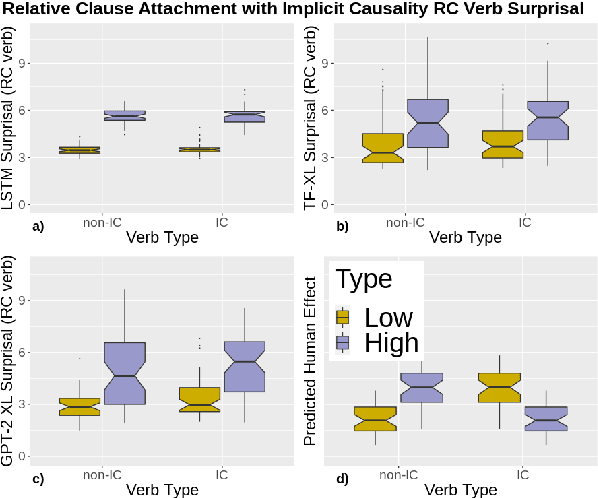
Language models (LMs) trained on large quantities of text have been claimed to acquire abstract linguistic representations. Our work tests the robustness of these abstractions by focusing on the ability of LMs to learn interactions between different linguistic representations. In particular, we utilized stimuli from psycholinguistic studies showing that humans can condition reference (i.e. coreference resolution) and syntactic processing on the same discourse structure (implicit causality). We compared both transformer and long short-term memory LMs to find that, contrary to humans, implicit causality only influences LM behavior for reference, not syntax, despite model representations that encode the necessary discourse information. Our results further suggest that LM behavior can contradict not only learned representations of discourse but also syntactic agreement, pointing to shortcomings of standard language modeling.
Recurrent Neural Network Language Models Always Learn English-Like Relative Clause Attachment
May 07, 2020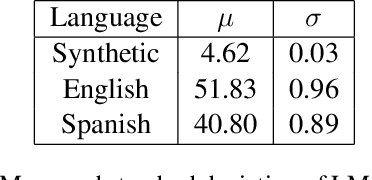
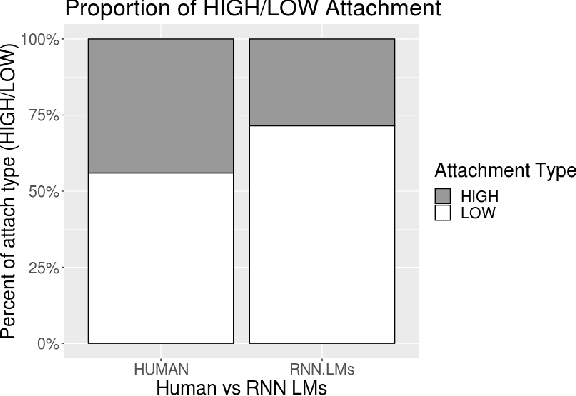
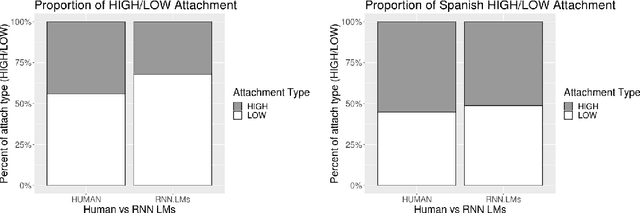
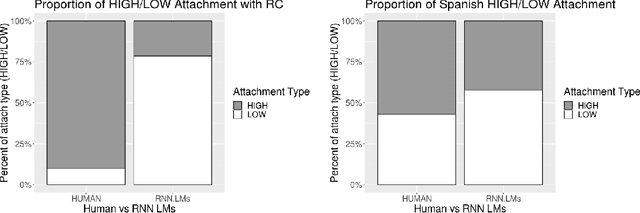
A standard approach to evaluating language models analyzes how models assign probabilities to valid versus invalid syntactic constructions (i.e. is a grammatical sentence more probable than an ungrammatical sentence). Our work uses ambiguous relative clause attachment to extend such evaluations to cases of multiple simultaneous valid interpretations, where stark grammaticality differences are absent. We compare model performance in English and Spanish to show that non-linguistic biases in RNN LMs advantageously overlap with syntactic structure in English but not Spanish. Thus, English models may appear to acquire human-like syntactic preferences, while models trained on Spanish fail to acquire comparable human-like preferences. We conclude by relating these results to broader concerns about the relationship between comprehension (i.e. typical language model use cases) and production (which generates the training data for language models), suggesting that necessary linguistic biases are not present in the training signal at all.
Using Priming to Uncover the Organization of Syntactic Representations in Neural Language Models
Sep 23, 2019


Neural language models (LMs) perform well on tasks that require sensitivity to syntactic structure. Drawing on the syntactic priming paradigm from psycholinguistics, we propose a novel technique to analyze the representations that enable such success. By establishing a gradient similarity metric between structures, this technique allows us to reconstruct the organization of the LMs' syntactic representational space. We use this technique to demonstrate that LSTM LMs' representations of different types of sentences with relative clauses are organized hierarchically in a linguistically interpretable manner, suggesting that the LMs track abstract properties of the sentence.
* 9 pages paper, 2 pages references and 3 pages supplementary materials. Code for the templates and analyses can be found here: https://github.com/grushaprasad/RNN-Priming