 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensePOLAR: Word sense aware interpretability for pre-trained contextual word embeddings
Jan 11, 2023Adding interpretability to word embeddings represents an area of active research in text representation. Recent work has explored thepotential of embedding words via so-called polar dimensions (e.g. good vs. bad, correct vs. wrong). Examples of such recent approaches include SemAxis, POLAR, FrameAxis, and BiImp. Although these approaches provide interpretable dimensions for words, they have not been designed to deal with polysemy, i.e. they can not easily distinguish between different senses of words. To address this limitation, we present SensePOLAR, an extension of the original POLAR framework that enables word-sense aware interpretability for pre-trained contextual word embeddings. The resulting interpretable word embeddings achieve a level of performance that is comparable to original contextual word embeddings across a variety of natural language processing tasks including the GLUE and SQuAD benchmarks. Our work removes a fundamental limitation of existing approaches by offering users sense aware interpretations for contextual word embeddings.
Properties of Group Fairness Metrics for Rankings
Dec 29, 2022In recent years, several metrics have been developed for evaluating group fairness of rankings. Given that these metrics were developed with different application contexts and ranking algorithms in mind, it is not straightforward which metric to choose for a given scenario. In this paper, we perform a comprehensive comparative analysis of existing group fairness metrics developed in the context of fair ranking. By virtue of their diverse application contexts, we argue that such a comparative analysis is not straightforward. Hence, we take an axiomatic approach whereby we design a set of thirteen properties for group fairness metrics that consider different ranking settings. A metric can then be selected depending on whether it satisfies all or a subset of these properties. We apply these properties on eleven existing group fairness metrics, and through both empirical and theoretical results we demonstrate that most of these metrics only satisfy a small subset of the proposed properties. These findings highlight limitations of existing metrics, and provide insights into how to evaluate and interpret different fairness metrics in practical deployment. The proposed properties can also assist practitioners in selecting appropriate metrics for evaluating fairness in a specific application.
Adversarial Inter-Group Link Injection Degrades the Fairness of Graph Neural Networks
Sep 13, 2022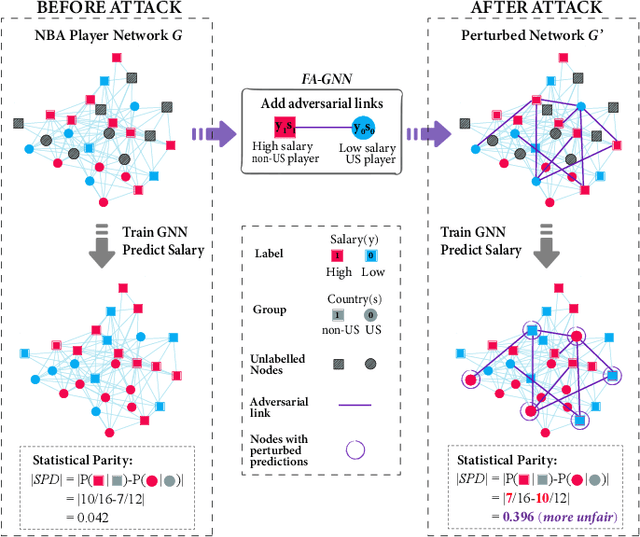
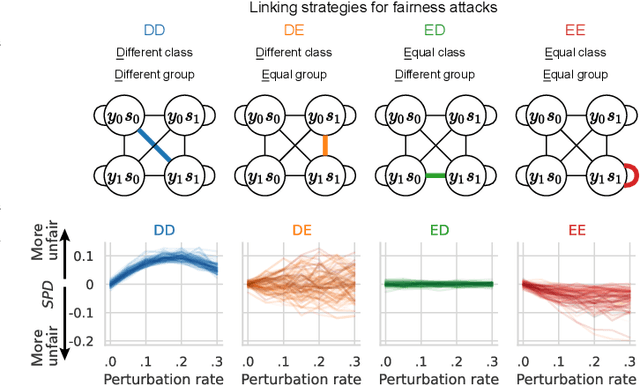
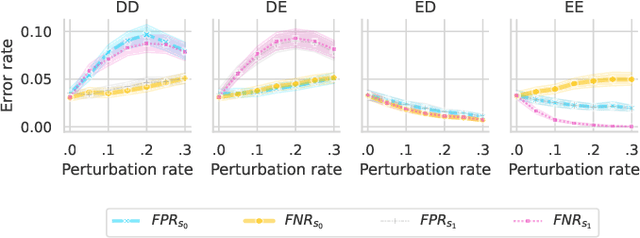
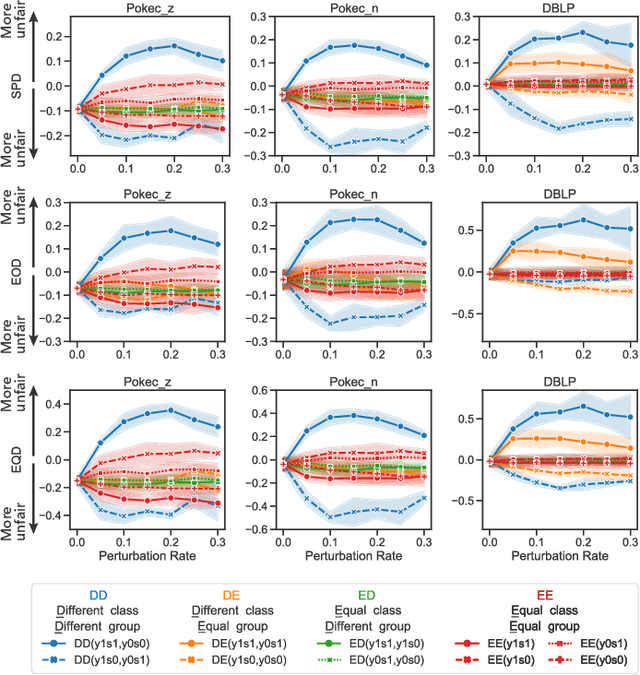
We present evidence for the existence and effectiveness of adversarial attacks on graph neural networks (GNNs) that aim to degrade fairness. These attacks can disadvantage a particular subgroup of nodes in GNN-based node classification, where nodes of the underlying network have sensitive attributes, such as race or gender. We conduct qualitative and experimental analyses explaining how adversarial link injection impairs the fairness of GNN predictions. For example, an attacker can compromise the fairness of GNN-based node classification by injecting adversarial links between nodes belonging to opposite subgroups and opposite class labels. Our experiments on empirical datasets demonstrate that adversarial fairness attacks can significantly degrade the fairness of GNN predictions (attacks are effective) with a low perturbation rate (attacks are efficient) and without a significant drop in accuracy (attacks are deceptive). This work demonstrates the vulnerability of GNN models to adversarial fairness attacks. We hope our findings raise awareness about this issue in our community and lay a foundation for the future development of GNN models that are more robust to such attacks.
Minorities in networks and algorithms
Jun 14, 2022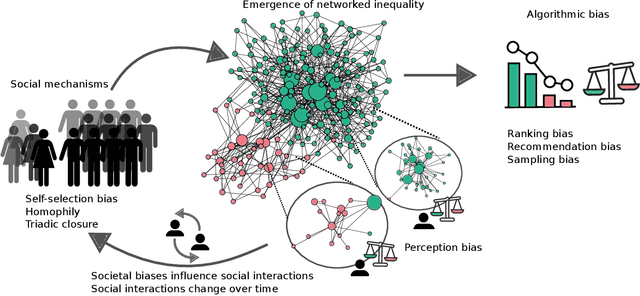
In this chapter, we provide an overview of recent advances in data-driven and theory-informed complex models of social networks and their potential in understanding societal inequalities and marginalization. We focus on inequalities arising from networks and network-based algorithms and how they affect minorities. In particular, we examine how homophily and mixing biases shape large and small social networks, influence perception of minorities, and affect collaboration patterns. We also discuss dynamical processes on and of networks and the formation of norms and health inequalities. Additionally, we argue that network modeling is paramount for unveiling the effect of ranking and social recommendation algorithms on the visibility of minorities. Finally, we highlight the key challenges and future opportunities in this emerging research topic.
Structack: Structure-based Adversarial Attacks on Graph Neural Networks
Jul 28, 2021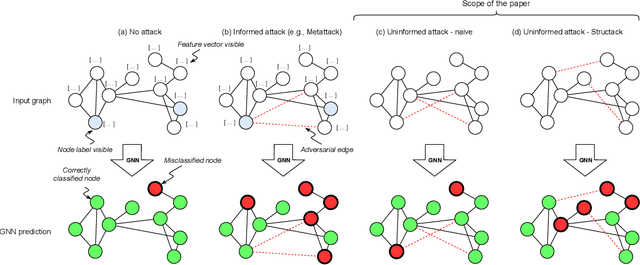
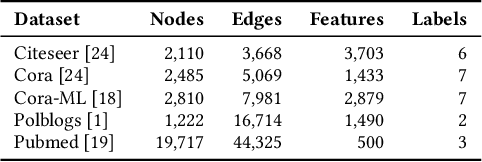
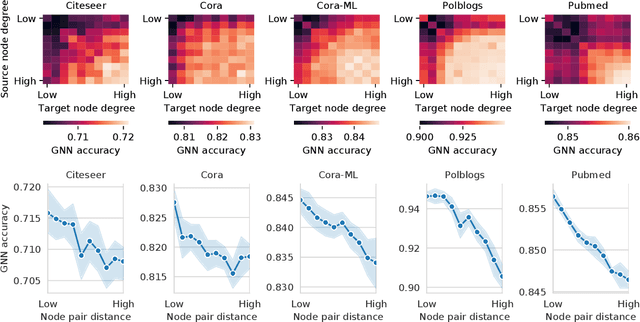

Recent work has shown that graph neural networks (GNNs) are vulnerable to adversarial attacks on graph data. Common attack approaches are typically informed, i.e. they have access to information about node attributes such as labels and feature vectors. In this work, we study adversarial attacks that are uninformed, where an attacker only has access to the graph structure, but no information about node attributes. Here the attacker aims to exploit structural knowledge and assumptions, which GNN models make about graph data. In particular, literature has shown that structural node centrality and similarity have a strong influence on learning with GNNs. Therefore, we study the impact of centrality and similarity on adversarial attacks on GNNs. We demonstrate that attackers can exploit this information to decrease the performance of GNNs by focusing on injecting links between nodes of low similarity and, surprisingly, low centrality. We show that structure-based uninformed attacks can approach the performance of informed attacks, while being computationally more efficient. With our paper, we present a new attack strategy on GNNs that we refer to as Structack. Structack can successfully manipulate the performance of GNNs with very limited information while operating under tight computational constraints. Our work contributes towards building more robust machine learning approaches on graphs.
Redescription Model Mining
Jul 09, 2021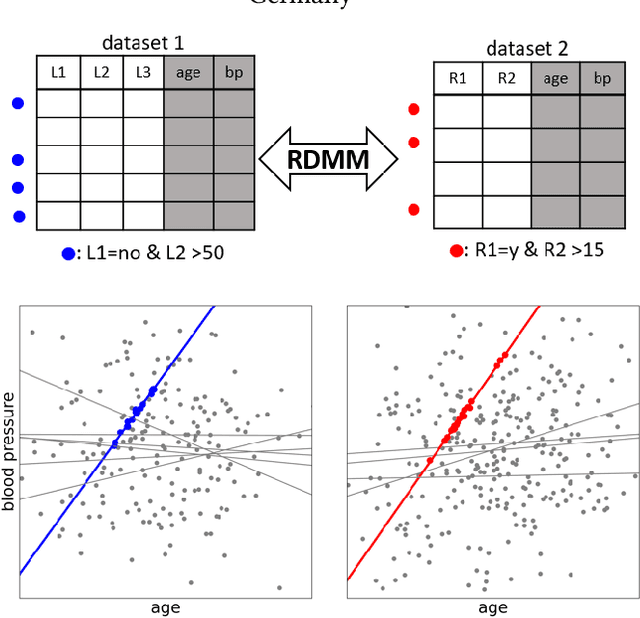
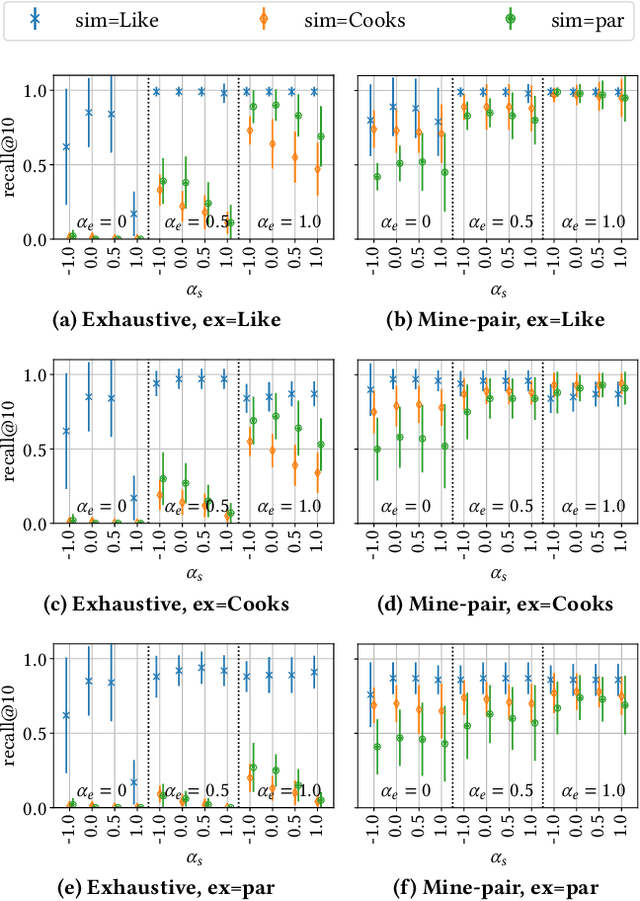
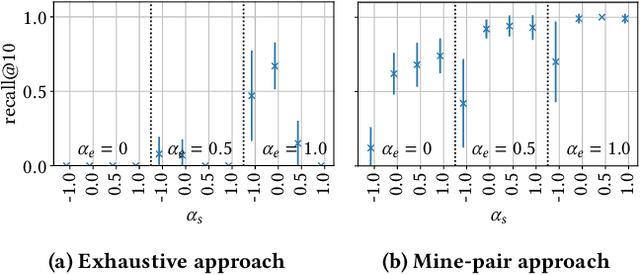
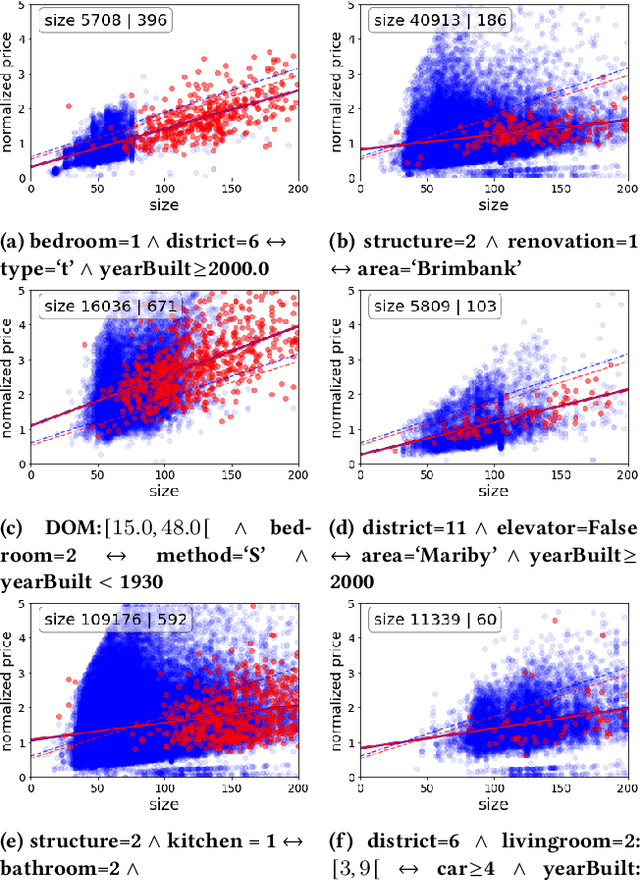
This paper introduces Redescription Model Mining, a novel approach to identify interpretable patterns across two datasets that share only a subset of attributes and have no common instances. In particular, Redescription Model Mining aims to find pairs of describable data subsets -- one for each dataset -- that induce similar exceptional models with respect to a prespecified model class. To achieve this, we combine two previously separate research areas: Exceptional Model Mining and Redescription Mining. For this new problem setting, we develop interestingness measures to select promising patterns, propose efficient algorithms, and demonstrate their potential on synthetic and real-world data. Uncovered patterns can hint at common underlying phenomena that manifest themselves across datasets, enabling the discovery of possible associations between (combinations of) attributes that do not appear in the same dataset.
A Comparative Evaluation of Quantification Methods
Mar 04, 2021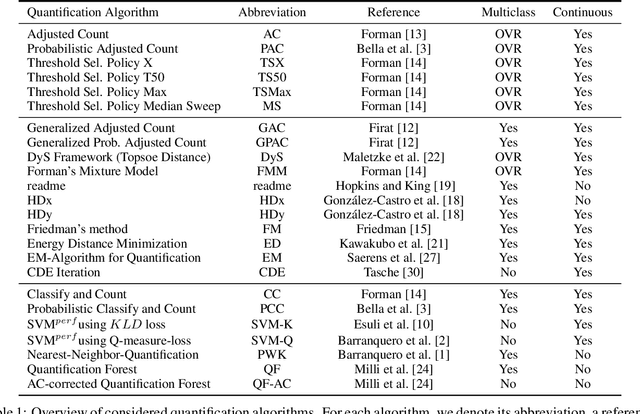
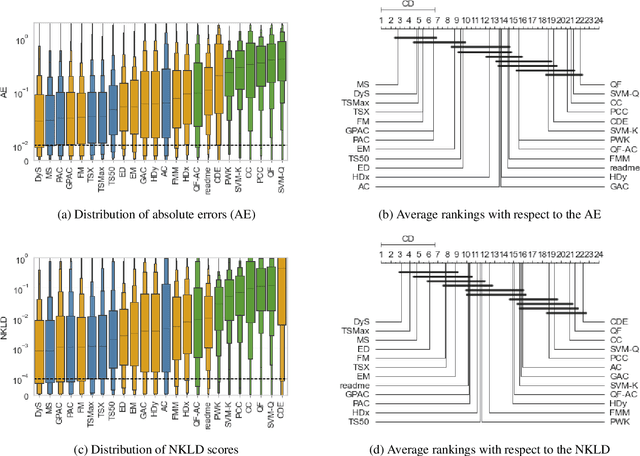
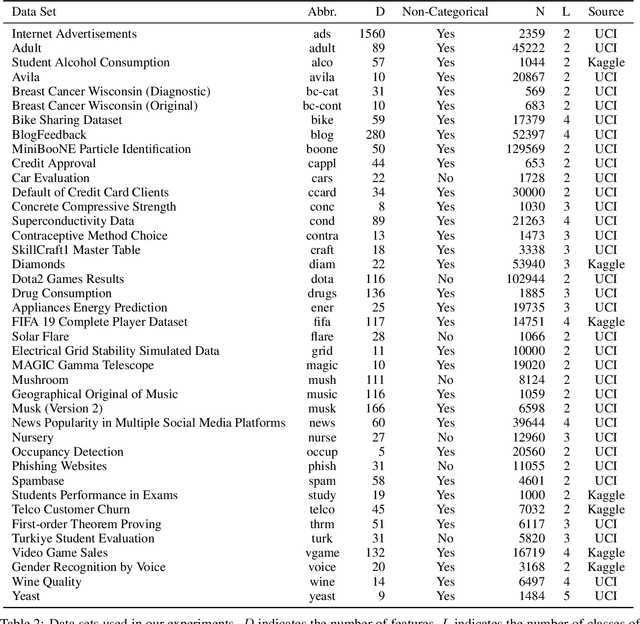
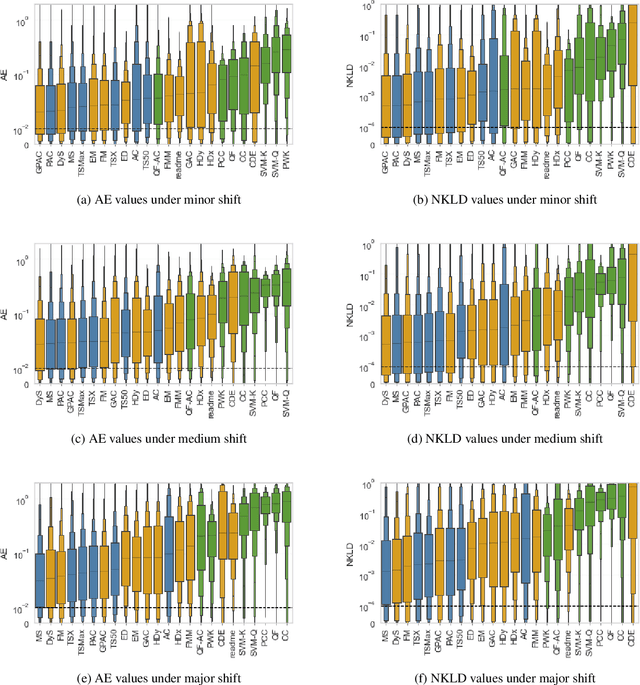
Quantification represents the problem of predicting class distributions in a given target set. It also represents a growing research field in supervised machine learning, for which a large variety of different algorithms has been proposed in recent years. However, a comprehensive empirical comparison of quantification methods that supports algorithm selection is not available yet. In this work, we close this research gap by conducting a thorough empirical performance comparison of 24 different quantification methods. To consider a broad range of different scenarios for binary as well as multiclass quantification settings, we carried out almost 3 million experimental runs on 40 data sets. We observe that no single algorithm generally outperforms all competitors, but identify a group of methods including the Median Sweep and the DyS framework that perform significantly better in binary settings. For the multiclass setting, we observe that a different, broad group of algorithms yields good performance, including the Generalized Probabilistic Adjusted Count, the readme method, the energy distance minimization method, the EM algorithm for quantification, and Friedman's method. More generally, we find that the performance on multiclass quantification is inferior to the results obtained in the binary setting. Our results can guide practitioners who intend to apply quantification algorithms and help researchers to identify opportunities for future research.
The FairCeptron: A Framework for Measuring Human Perceptions of Algorithmic Fairness
Feb 08, 2021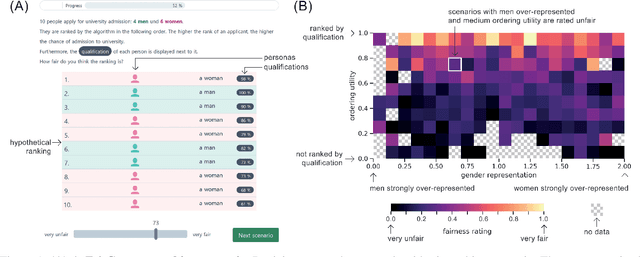
Measures of algorithmic fairness often do not account for human perceptions of fairness that can substantially vary between different sociodemographics and stakeholders. The FairCeptron framework is an approach for studying perceptions of fairness in algorithmic decision making such as in ranking or classification. It supports (i) studying human perceptions of fairness and (ii) comparing these human perceptions with measures of algorithmic fairness. The framework includes fairness scenario generation, fairness perception elicitation and fairness perception analysis. We demonstrate the FairCeptron framework by applying it to a hypothetical university admission context where we collect human perceptions of fairness in the presence of minorities. An implementation of the FairCeptron framework is openly available, and it can easily be adapted to study perceptions of algorithmic fairness in other application contexts. We hope our work paves the way towards elevating the role of studies of human fairness perceptions in the process of designing algorithmic decision making systems.
Quota-based debiasing can decrease representation of already underrepresented groups
Jun 13, 2020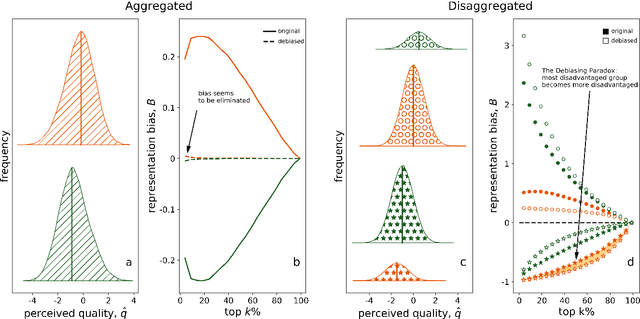
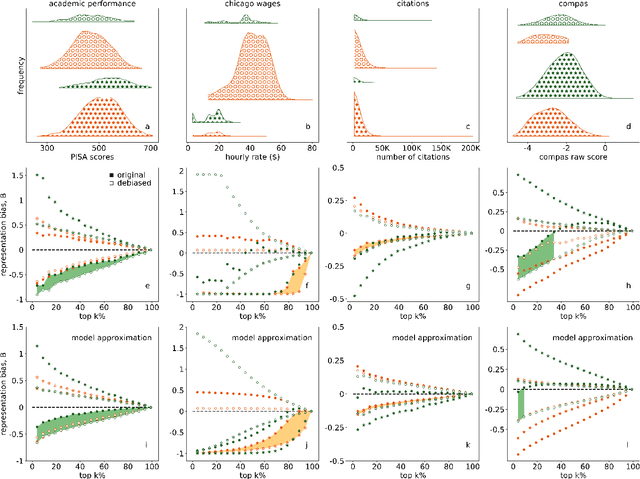
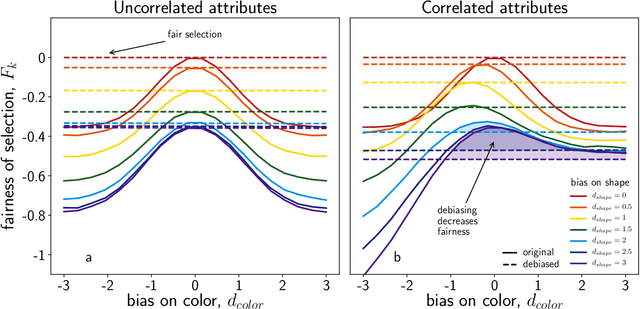
Many important decisions in societies such as school admissions, hiring, or elections are based on the selection of top-ranking individuals from a larger pool of candidates. This process is often subject to biases, which typically manifest as an under-representation of certain groups among the selected or accepted individuals. The most common approach to this issue is debiasing, for example via the introduction of quotas that ensure proportional representation of groups with respect to a certain, often binary attribute. Cases include quotas for women on corporate boards or ethnic quotas in elections. This, however, has the potential to induce changes in representation with respect to other attributes. For the case of two correlated binary attributes we show that quota-based debiasing based on a single attribute can worsen the representation of already underrepresented groups and decrease overall fairness of selection. We use several data sets from a broad range of domains from recidivism risk assessments to scientific citations to assess this effect in real-world settings. Our results demonstrate the importance of including all relevant attributes in debiasing procedures and that more efforts need to be put into eliminating the root causes of inequalities as purely numerical solutions such as quota-based debiasing might lead to unintended consequences.
The Effects of Randomness on the Stability of Node Embeddings
May 20, 2020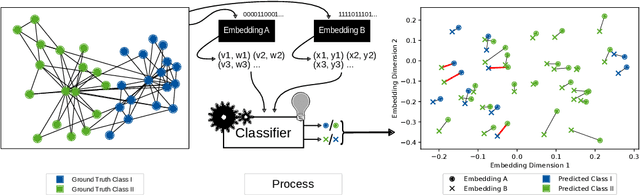
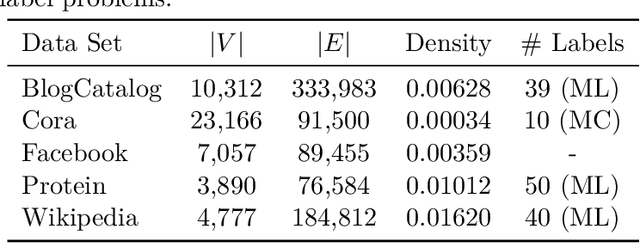
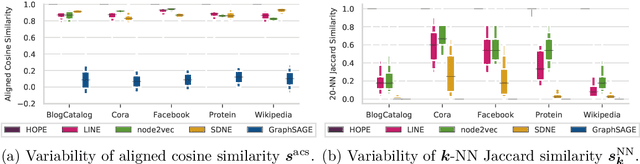
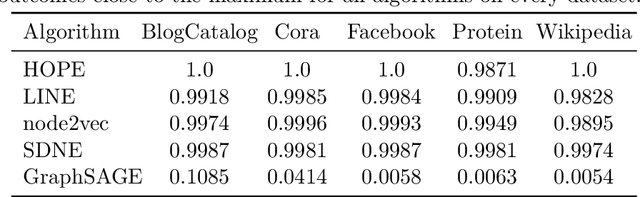
We systematically evaluate the (in-)stability of state-of-the-art node embedding algorithms due to randomness, i.e., the random variation of their outcomes given identical algorithms and graphs. We apply five node embeddings algorithms---HOPE, LINE, node2vec, SDNE, and GraphSAGE---to synthetic and empirical graphs and assess their stability under randomness with respect to (i) the geometry of embedding spaces as well as (ii) their performance in downstream tasks. We find significant instabilities in the geometry of embedding spaces independent of the centrality of a node. In the evaluation of downstream tasks, we find that the accuracy of node classification seems to be unaffected by random seeding while the actual classification of nodes can vary significantly. This suggests that instability effects need to be taken into account when working with node embeddings. Our work is relevant for researchers and engineers interested in the effectiveness, reliability, and reproducibility of node embedding approaches.