 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Universal to Individualized Actionability: Revisiting Personalization in Algorithmic Recourse
Apr 09, 2026Algorithmic recourse aims to provide actionable recommendations that enable individuals to change unfavorable model outcomes, and prior work has extensively studied properties such as efficiency, robustness, and fairness. However, the role of personalization in recourse remains largely implicit and underexplored. While existing approaches incorporate elements of personalization through user interactions, they typically lack an explicit definition of personalization and do not systematically analyze its downstream effects on other recourse desiderata. In this paper, we formalize personalization as individual actionability, characterized along two dimensions: hard constraints that specify which features are individually actionable, and soft, individualized constraints that capture preferences over action values and costs. We operationalize these dimensions within the causal algorithmic recourse framework, adopting a pre-hoc user-prompting approach in which individuals express preferences via rankings or scores prior to the generation of any recourse recommendation. Through extensive empirical evaluation, we investigate how personalization interacts with key recourse desiderata, including validity, cost, and plausibility. Our results highlight important trade-offs: individual actionability constraints, particularly hard ones, can substantially degrade the plausibility and validity of recourse recommendations across amortized and non-amortized approaches. Notably, we also find that incorporating individual actionability can reveal disparities in the cost and plausibility of recourse actions across socio-demographic groups. These findings underscore the need for principled definitions, careful operationalization, and rigorous evaluation of personalization in algorithmic recourse.
Laypeople's Attitudes Towards Fair, Affirmative, and Discriminatory Decision-Making Algorithms
May 12, 2025Affirmative algorithms have emerged as a potential answer to algorithmic discrimination, seeking to redress past harms and rectify the source of historical injustices. We present the results of two experiments ($N$$=$$1193$) capturing laypeople's perceptions of affirmative algorithms -- those which explicitly prioritize the historically marginalized -- in hiring and criminal justice. We contrast these opinions about affirmative algorithms with folk attitudes towards algorithms that prioritize the privileged (i.e., discriminatory) and systems that make decisions independently of demographic groups (i.e., fair). We find that people -- regardless of their political leaning and identity -- view fair algorithms favorably and denounce discriminatory systems. In contrast, we identify disagreements concerning affirmative algorithms: liberals and racial minorities rate affirmative systems as positively as their fair counterparts, whereas conservatives and those from the dominant racial group evaluate affirmative algorithms as negatively as discriminatory systems. We identify a source of these divisions: people have varying beliefs about who (if anyone) is marginalized, shaping their views of affirmative algorithms. We discuss the possibility of bridging these disagreements to bring people together towards affirmative algorithms.
What Makes for a Good Saliency Map? Comparing Strategies for Evaluating Saliency Maps in Explainable AI (XAI)
Apr 23, 2025Saliency maps are a popular approach for explaining classifications of (convolutional) neural networks. However, it remains an open question as to how best to evaluate salience maps, with three families of evaluation methods commonly being used: subjective user measures, objective user measures, and mathematical metrics. We examine three of the most popular saliency map approaches (viz., LIME, Grad-CAM, and Guided Backpropagation) in a between subject study (N=166) across these families of evaluation methods. We test 1) for subjective measures, if the maps differ with respect to user trust and satisfaction; 2) for objective measures, if the maps increase users' abilities and thus understanding of a model; 3) for mathematical metrics, which map achieves the best ratings across metrics; and 4) whether the mathematical metrics can be associated with objective user measures. To our knowledge, our study is the first to compare several salience maps across all these evaluation methods$-$with the finding that they do not agree in their assessment (i.e., there was no difference concerning trust and satisfaction, Grad-CAM improved users' abilities best, and Guided Backpropagation had the most favorable mathematical metrics). Additionally, we show that some mathematical metrics were associated with user understanding, although this relationship was often counterintuitive. We discuss these findings in light of general debates concerning the complementary use of user studies and mathematical metrics in the evaluation of explainable AI (XAI) approaches.
Software Doping Analysis for Human Oversight
Aug 11, 2023



This article introduces a framework that is meant to assist in mitigating societal risks that software can pose. Concretely, this encompasses facets of software doping as well as unfairness and discrimination in high-risk decision-making systems. The term software doping refers to software that contains surreptitiously added functionality that is against the interest of the user. A prominent example of software doping are the tampered emission cleaning systems that were found in millions of cars around the world when the diesel emissions scandal surfaced. The first part of this article combines the formal foundations of software doping analysis with established probabilistic falsification techniques to arrive at a black-box analysis technique for identifying undesired effects of software. We apply this technique to emission cleaning systems in diesel cars but also to high-risk systems that evaluate humans in a possibly unfair or discriminating way. We demonstrate how our approach can assist humans-in-the-loop to make better informed and more responsible decisions. This is to promote effective human oversight, which will be a central requirement enforced by the European Union's upcoming AI Act. We complement our technical contribution with a juridically, philosophically, and psychologically informed perspective on the potential problems caused by such systems.
A New Perspective on Evaluation Methods for Explainable Artificial Intelligence
Jul 26, 2023

Within the field of Requirements Engineering (RE), the increasing significance of Explainable Artificial Intelligence (XAI) in aligning AI-supported systems with user needs, societal expectations, and regulatory standards has garnered recognition. In general, explainability has emerged as an important non-functional requirement that impacts system quality. However, the supposed trade-off between explainability and performance challenges the presumed positive influence of explainability. If meeting the requirement of explainability entails a reduction in system performance, then careful consideration must be given to which of these quality aspects takes precedence and how to compromise between them. In this paper, we critically examine the alleged trade-off. We argue that it is best approached in a nuanced way that incorporates resource availability, domain characteristics, and considerations of risk. By providing a foundation for future research and best practices, this work aims to advance the field of RE for AI.
What Do We Want From Explainable Artificial Intelligence ? -- A Stakeholder Perspective on XAI and a Conceptual Model Guiding Interdisciplinary XAI Research
Feb 15, 2021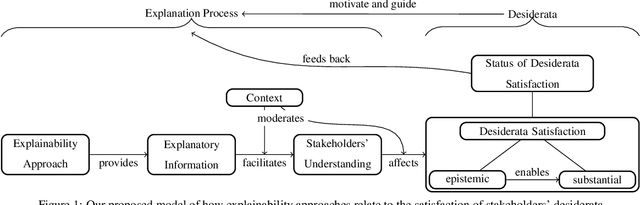
Previous research in Explainable Artificial Intelligence (XAI) suggests that a main aim of explainability approaches is to satisfy specific interests, goals, expectations, needs, and demands regarding artificial systems (we call these stakeholders' desiderata) in a variety of contexts. However, the literature on XAI is vast, spreads out across multiple largely disconnected disciplines, and it often remains unclear how explainability approaches are supposed to achieve the goal of satisfying stakeholders' desiderata. This paper discusses the main classes of stakeholders calling for explainability of artificial systems and reviews their desiderata. We provide a model that explicitly spells out the main concepts and relations necessary to consider and investigate when evaluating, adjusting, choosing, and developing explainability approaches that aim to satisfy stakeholders' desiderata. This model can serve researchers from the variety of different disciplines involved in XAI as a common ground. It emphasizes where there is interdisciplinary potential in the evaluation and the development of explainability approaches.