 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDONUT: A Decoder-Only Model for Trajectory Prediction
Jun 07, 2025



Predicting the motion of other agents in a scene is highly relevant for autonomous driving, as it allows a self-driving car to anticipate. Inspired by the success of decoder-only models for language modeling, we propose DONUT, a Decoder-Only Network for Unrolling Trajectories. Different from existing encoder-decoder forecasting models, we encode historical trajectories and predict future trajectories with a single autoregressive model. This allows the model to make iterative predictions in a consistent manner, and ensures that the model is always provided with up-to-date information, enhancing the performance. Furthermore, inspired by multi-token prediction for language modeling, we introduce an 'overprediction' strategy that gives the network the auxiliary task of predicting trajectories at longer temporal horizons. This allows the model to better anticipate the future, and further improves the performance. With experiments, we demonstrate that our decoder-only approach outperforms the encoder-decoder baseline, and achieves new state-of-the-art results on the Argoverse 2 single-agent motion forecasting benchmark.
Reposing Humans by Warping 3D Features
Jun 08, 2020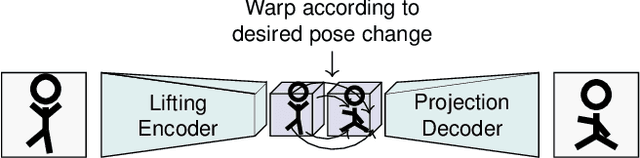
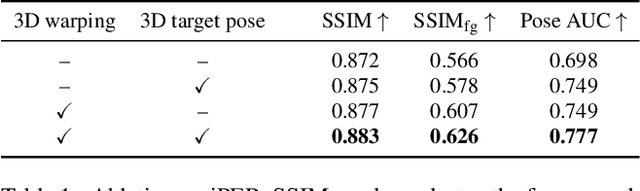
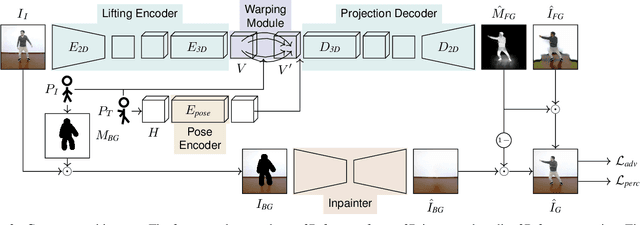
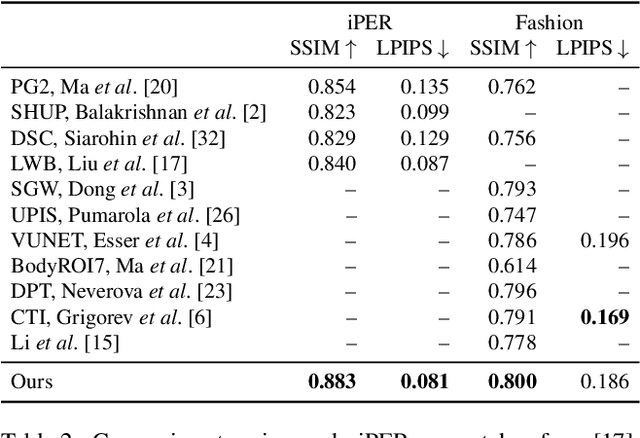
We address the problem of reposing an image of a human into any desired novel pose. This conditional image-generation task requires reasoning about the 3D structure of the human, including self-occluded body parts. Most prior works are either based on 2D representations or require fitting and manipulating an explicit 3D body mesh. Based on the recent success in deep learning-based volumetric representations, we propose to implicitly learn a dense feature volume from human images, which lends itself to simple and intuitive manipulation through explicit geometric warping. Once the latent feature volume is warped according to the desired pose change, the volume is mapped back to RGB space by a convolutional decoder. Our state-of-the-art results on the DeepFashion and the iPER benchmarks indicate that dense volumetric human representations are worth investigating in more detail.