 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioAgent Bench: An AI Agent Evaluation Suite for Bioinformatics
Jan 29, 2026This paper introduces BioAgent Bench, a benchmark dataset and an evaluation suite designed for measuring the performance and robustness of AI agents in common bioinformatics tasks. The benchmark contains curated end-to-end tasks (e.g., RNA-seq, variant calling, metagenomics) with prompts that specify concrete output artifacts to support automated assessment, including stress testing under controlled perturbations. We evaluate frontier closed-source and open-weight models across multiple agent harnesses, and use an LLM-based grader to score pipeline progress and outcome validity. We find that frontier agents can complete multi-step bioinformatics pipelines without elaborate custom scaffolding, often producing the requested final artifacts reliably. However, robustness tests reveal failure modes under controlled perturbations (corrupted inputs, decoy files, and prompt bloat), indicating that correct high-level pipeline construction does not guarantee reliable step-level reasoning. Finally, because bioinformatics workflows may involve sensitive patient data, proprietary references, or unpublished IP, closed-source models can be unsuitable under strict privacy constraints; in such settings, open-weight models may be preferable despite lower completion rates. We release the dataset and evaluation suite publicly.
Sequence Repetition Enhances Token Embeddings and Improves Sequence Labeling with Decoder-only Language Models
Jan 24, 2026Modern language models (LMs) are trained in an autoregressive manner, conditioned only on the prefix. In contrast, sequence labeling (SL) tasks assign labels to each individual input token, naturally benefiting from bidirectional context. This discrepancy has historically led SL to rely on inherently bidirectional encoder-only models. However, the rapid development of decoder-only models has raised the question of whether they can be adapted to SL. While causal mask removal has emerged as a viable technique for adapting decoder-only models to leverage the full context for SL, it requires considerable changes to the base model functionality. In this work, we explore sequence repetition (SR) as a less invasive alternative for enabling bidirectionality in decoder-only models. Through fine-tuning experiments, we show that SR inherently makes decoders bidirectional, improving the quality of token-level embeddings and surpassing encoders and unmasked decoders. Contrary to earlier claims, we find that increasing the number of repetitions does not degrade SL performance. Finally, we demonstrate that embeddings from intermediate layers are highly effective for SR, comparable to those from final layers, while being significantly more efficient to compute. Our findings underscore that SR alleviates the structural limitations of decoders, enabling more efficient and adaptable LMs and broadening their applicability to other token-level tasks.
Characterizing Linguistic Shifts in Croatian News via Diachronic Word Embeddings
Jun 16, 2025



Measuring how semantics of words change over time improves our understanding of how cultures and perspectives change. Diachronic word embeddings help us quantify this shift, although previous studies leveraged substantial temporally annotated corpora. In this work, we use a corpus of 9.5 million Croatian news articles spanning the past 25 years and quantify semantic change using skip-gram word embeddings trained on five-year periods. Our analysis finds that word embeddings capture linguistic shifts of terms pertaining to major topics in this timespan (COVID-19, Croatia joining the European Union, technological advancements). We also find evidence that embeddings from post-2020 encode increased positivity in sentiment analysis tasks, contrasting studies reporting a decline in mental health over the same period.
Strong Heuristics for Named Entity Linking
Jul 06, 2022
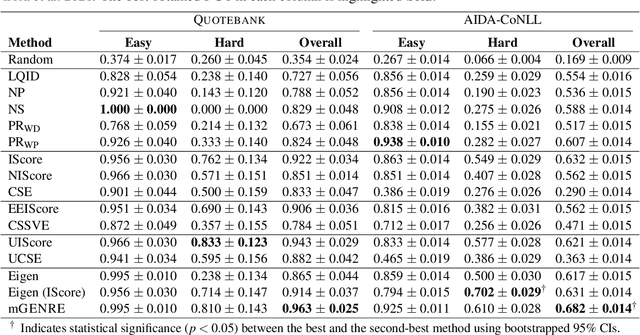
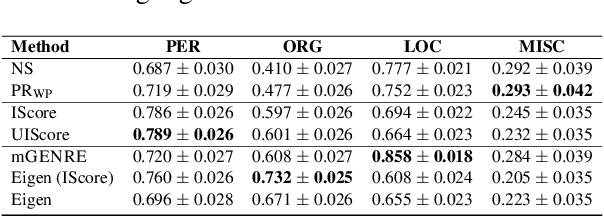

Named entity linking (NEL) in news is a challenging endeavour due to the frequency of unseen and emerging entities, which necessitates the use of unsupervised or zero-shot methods. However, such methods tend to come with caveats, such as no integration of suitable knowledge bases (like Wikidata) for emerging entities, a lack of scalability, and poor interpretability. Here, we consider person disambiguation in Quotebank, a massive corpus of speaker-attributed quotations from the news, and investigate the suitability of intuitive, lightweight, and scalable heuristics for NEL in web-scale corpora. Our best performing heuristic disambiguates 94% and 63% of the mentions on Quotebank and the AIDA-CoNLL benchmark, respectively. Additionally, the proposed heuristics compare favourably to the state-of-the-art unsupervised and zero-shot methods, Eigenthemes and mGENRE, respectively, thereby serving as strong baselines for unsupervised and zero-shot entity linking.