 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Dataset Generation for Autonomous Mobile Robots Using 3D Gaussian Splatting for Vision Training
Jun 05, 2025Annotated datasets are critical for training neural networks for object detection, yet their manual creation is time- and labour-intensive, subjective to human error, and often limited in diversity. This challenge is particularly pronounced in the domain of robotics, where diverse and dynamic scenarios further complicate the creation of representative datasets. To address this, we propose a novel method for automatically generating annotated synthetic data in Unreal Engine. Our approach leverages photorealistic 3D Gaussian splats for rapid synthetic data generation. We demonstrate that synthetic datasets can achieve performance comparable to that of real-world datasets while significantly reducing the time required to generate and annotate data. Additionally, combining real-world and synthetic data significantly increases object detection performance by leveraging the quality of real-world images with the easier scalability of synthetic data. To our knowledge, this is the first application of synthetic data for training object detection algorithms in the highly dynamic and varied environment of robot soccer. Validation experiments reveal that a detector trained on synthetic images performs on par with one trained on manually annotated real-world images when tested on robot soccer match scenarios. Our method offers a scalable and comprehensive alternative to traditional dataset creation, eliminating the labour-intensive error-prone manual annotation process. By generating datasets in a simulator where all elements are intrinsically known, we ensure accurate annotations while significantly reducing manual effort, which makes it particularly valuable for robotics applications requiring diverse and scalable training data.
DRAFT-What you always wanted to know but could not find about block-based environments
Oct 06, 2021

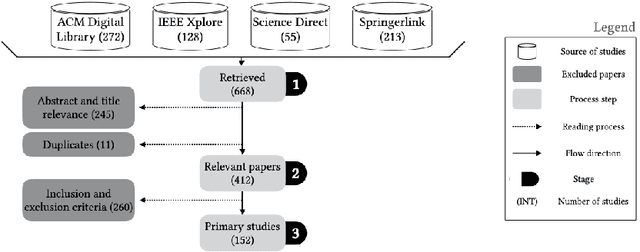
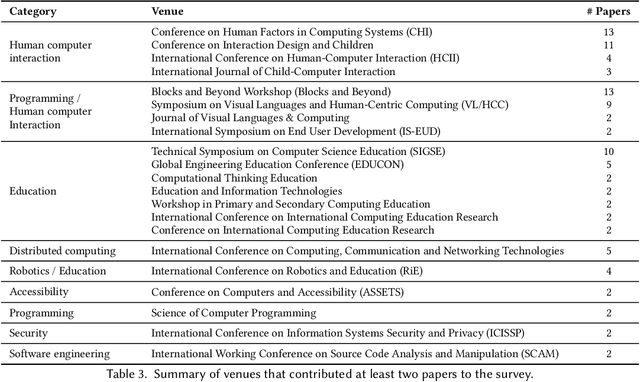
Block-based environments are visual programming environments, which are becoming more and more popular because of their ease of use. The ease of use comes thanks to their intuitive graphical representation and structural metaphors (jigsaw-like puzzles) to display valid combinations of language constructs to the users. Part of the current popularity of block-based environments is thanks to Scratch. As a result they are often associated with tools for children or young learners. However, it is unclear how these types of programming environments are developed and used in general. So we conducted a systematic literature review on block-based environments by studying 152 papers published between 2014 and 2020, and a non-systematic tool review of 32 block-based environments. In particular, we provide a helpful inventory of block-based editors for end-users on different topics and domains. Likewise, we focused on identifying the main components of block-based environments, how they are engineered, and how they are used. This survey should be equally helpful for language engineering researchers and language engineers alike.
Clone-Seeker: Effective Code Clone Search Using Annotations
Jun 06, 2021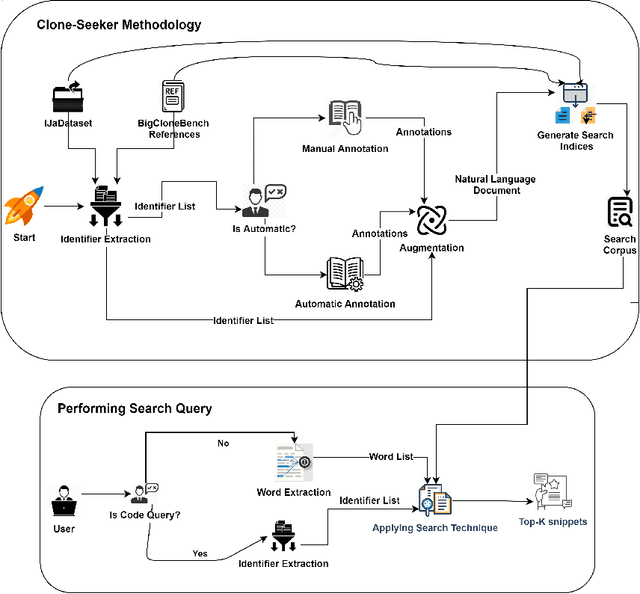
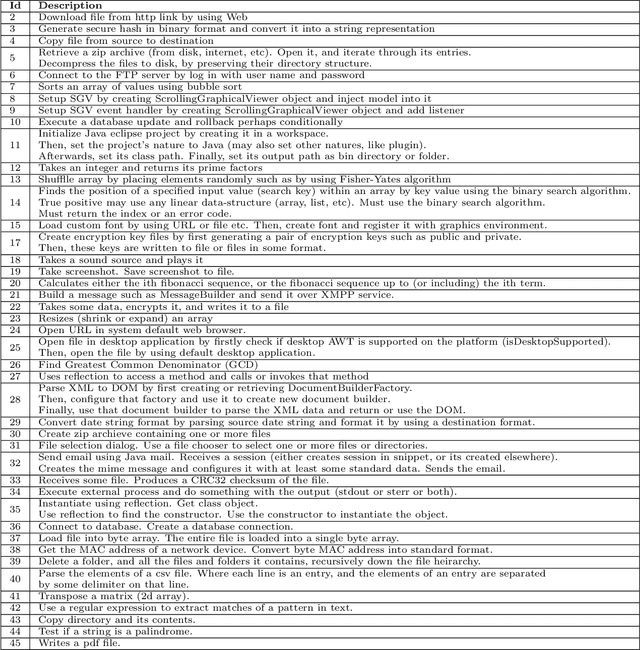

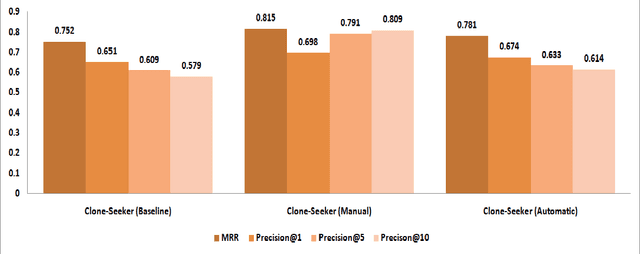
Source code search plays an important role in software development, e.g. for exploratory development or opportunistic reuse of existing code from a code base. Often, exploration of different implementations with the same functionality is needed for tasks like automated software transplantation, software diversification, and software repair. Code clones, which are syntactically or semantically similar code fragments, are perfect candidates for such tasks. Searching for code clones involves a given search query to retrieve the relevant code fragments. We propose a novel approach called Clone-Seeker that focuses on utilizing clone class features in retrieving code clones. For this purpose, we generate metadata for each code clone in the form of a natural language document. The metadata includes a pre-processed list of identifiers from the code clones augmented with a list of keywords indicating the semantics of the code clone. This keyword list can be extracted from a manually annotated general description of the clone class, or automatically generated from the source code of the entire clone class. This approach helps developers to perform code clone search based on a search query written either as source code terms, or as natural language. In our quantitative evaluation, we show that (1) Clone-Seeker has a higher recall when searching for semantic code clones (i.e., Type-4) in BigCloneBench than the state-of-the-art; and (2) Clone-Seeker can accurately search for relevant code clones by applying natural language queries.