 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Extraction for Machine Learning-based Intrusion Detection in IoT Networks
Aug 28, 2021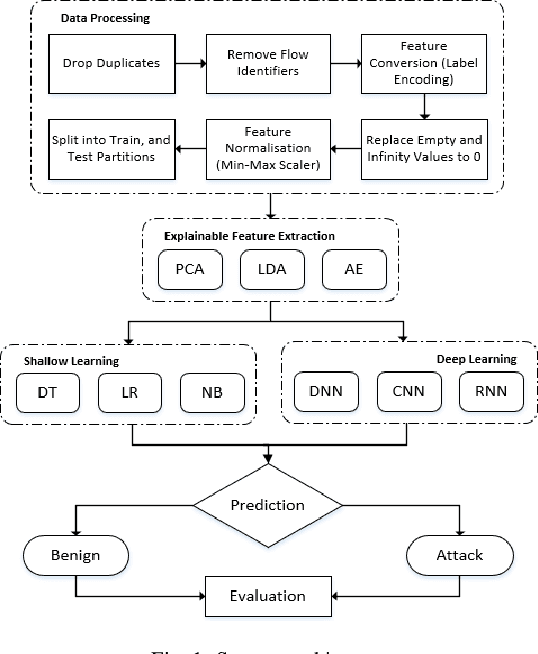
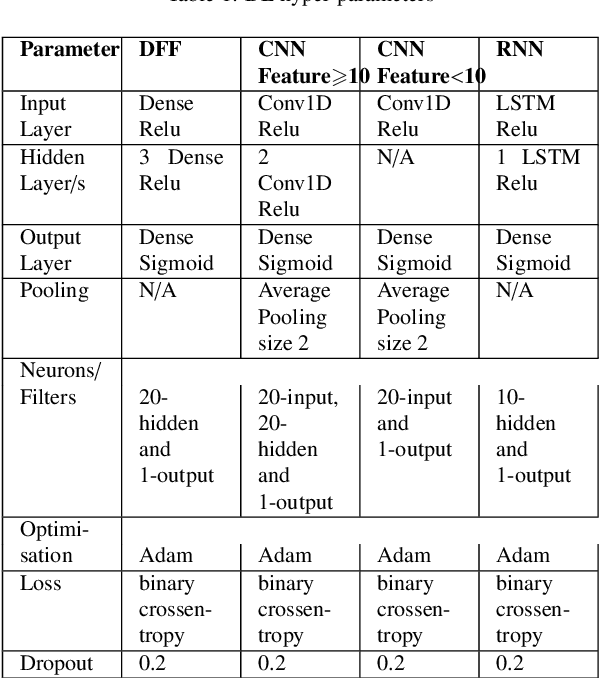
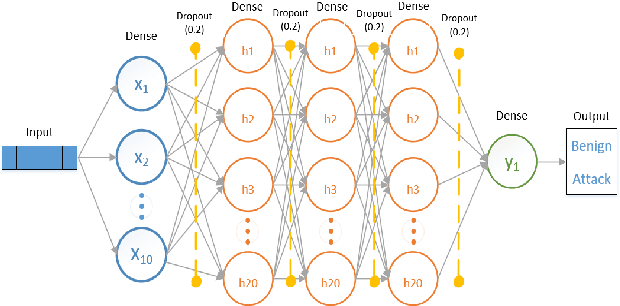
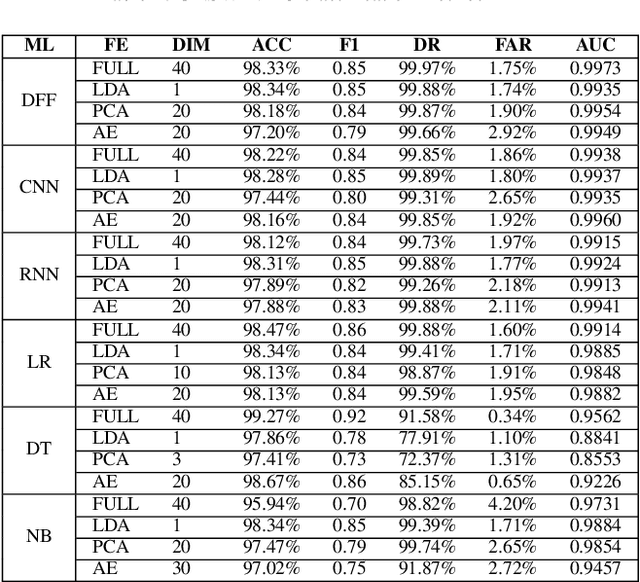
The tremendous numbers of network security breaches that have occurred in IoT networks have demonstrated the unreliability of current Network Intrusion Detection Systems (NIDSs). Consequently, network interruptions and loss of sensitive data have occurred which led to an active research area for improving NIDS technologies. During an analysis of related works, it was observed that most researchers aimed to obtain better classification results by using a set of untried combinations of Feature Reduction (FR) and Machine Learning (ML) techniques on NIDS datasets. However, these datasets are different in feature sets, attack types, and network design. Therefore, this paper aims to discover whether these techniques can be generalised across various datasets. Six ML models are utilised: a Deep Feed Forward, Convolutional Neural Network, Recurrent Neural Network, Decision Tree, Logistic Regression, and Naive Bayes. The detection accuracy of three Feature Extraction (FE) algorithms; Principal Component Analysis (PCA), Auto-encoder (AE), and Linear Discriminant Analysis (LDA) is evaluated using three benchmark datasets; UNSW-NB15, ToN-IoT and CSE-CIC-IDS2018. Although PCA and AE algorithms have been widely used, determining their optimal number of extracted dimensions has been overlooked. The results obtained indicate that there is no clear FE method or ML model that can achieve the best scores for all datasets. The optimal number of extracted dimensions has been identified for each dataset and LDA decreases the performance of the ML models on two datasets. The variance is used to analyse the extracted dimensions of LDA and PCA. Finally, this paper concludes that the choice of datasets significantly alters the performance of the applied techniques and we argue for the need for a universal (benchmark) feature set to facilitate further advancement and progress in this field of research.
Benchmarking the Benchmark -- Analysis of Synthetic NIDS Datasets
Apr 19, 2021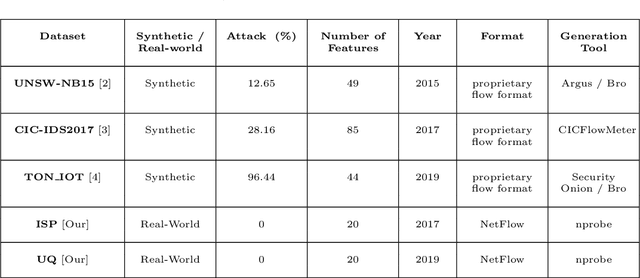
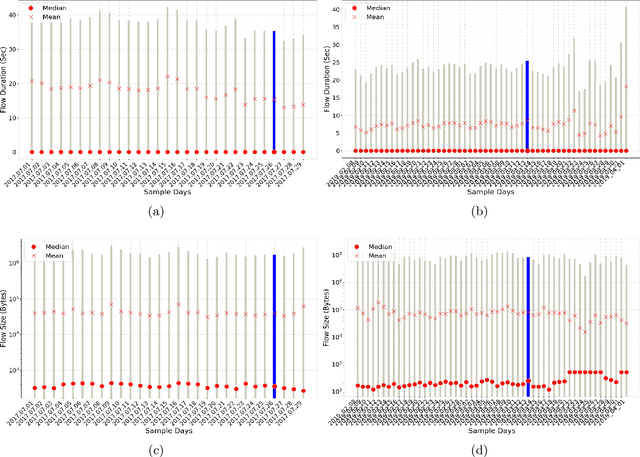
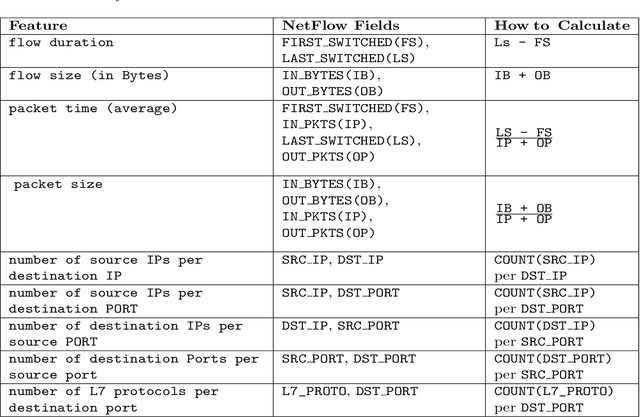
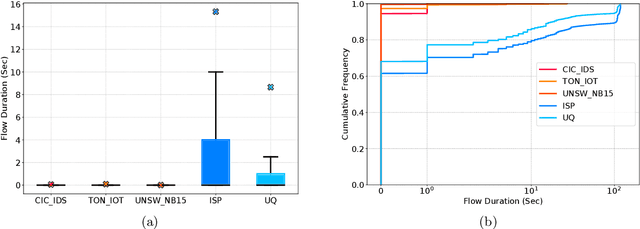
Network Intrusion Detection Systems (NIDSs) are an increasingly important tool for the prevention and mitigation of cyber attacks. A number of labelled synthetic datasets generated have been generated and made publicly available by researchers, and they have become the benchmarks via which new ML-based NIDS classifiers are being evaluated. Recently published results show excellent classification performance with these datasets, increasingly approaching 100 percent performance across key evaluation metrics such as accuracy, F1 score, etc. Unfortunately, we have not yet seen these excellent academic research results translated into practical NIDS systems with such near-perfect performance. This motivated our research presented in this paper, where we analyse the statistical properties of the benign traffic in three of the more recent and relevant NIDS datasets, (CIC, UNSW, ...). As a comparison, we consider two datasets obtained from real-world production networks, one from a university network and one from a medium size Internet Service Provider (ISP). Our results show that the two real-world datasets are quite similar among themselves in regards to most of the considered statistical features. Equally, the three synthetic datasets are also relatively similar within their group. However, and most importantly, our results show a distinct difference of most of the considered statistical features between the three synthetic datasets and the two real-world datasets. Since ML relies on the basic assumption of training and test datasets being sampled from the same distribution, this raises the question of how well the performance results of ML-classifiers trained on the considered synthetic datasets can translate and generalise to real-world networks. We believe this is an interesting and relevant question which provides motivation for further research in this space.
An Explainable Machine Learning-based Network Intrusion Detection System for Enabling Generalisability in Securing IoT Networks
Apr 15, 2021



Machine Learning (ML)-based network intrusion detection systems bring many benefits for enhancing the security posture of an organisation. Many systems have been designed and developed in the research community, often achieving a perfect detection rate when evaluated using certain datasets. However, the high number of academic research has not translated into practical deployments. There are a number of causes behind the lack of production usage. This paper tightens the gap by evaluating the generalisability of a common feature set to different network environments and attack types. Therefore, two feature sets (NetFlow and CICFlowMeter) have been evaluated across three datasets, i.e. CSE-CIC-IDS2018, BoT-IoT, and ToN-IoT. The results showed that the NetFlow feature set enhances the two ML models' detection accuracy in detecting intrusions across different datasets. In addition, due to the complexity of the learning models, the SHAP, an explainable AI methodology, has been adopted to explain and interpret the classification decisions of two ML models. The Shapley values of the features have been analysed across multiple datasets to determine the influence contributed by each feature towards the final ML prediction.
E-GraphSAGE: A Graph Neural Network based Intrusion Detection System
Apr 01, 2021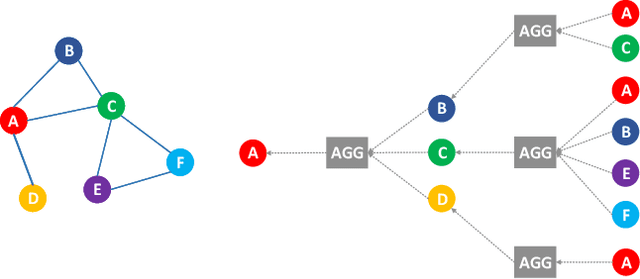
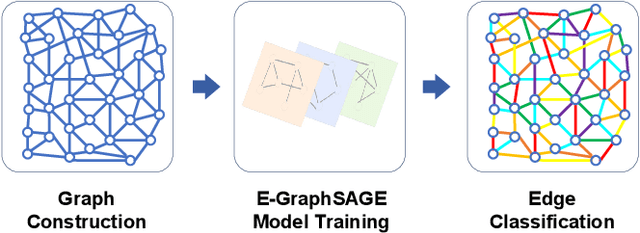
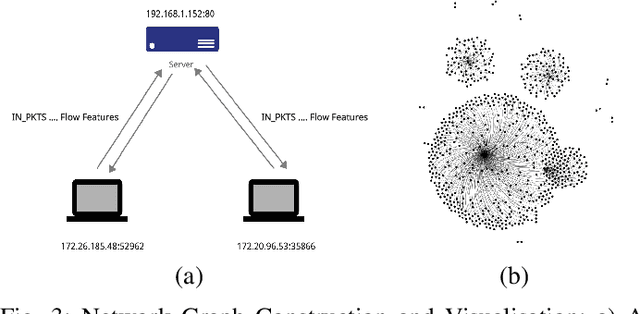
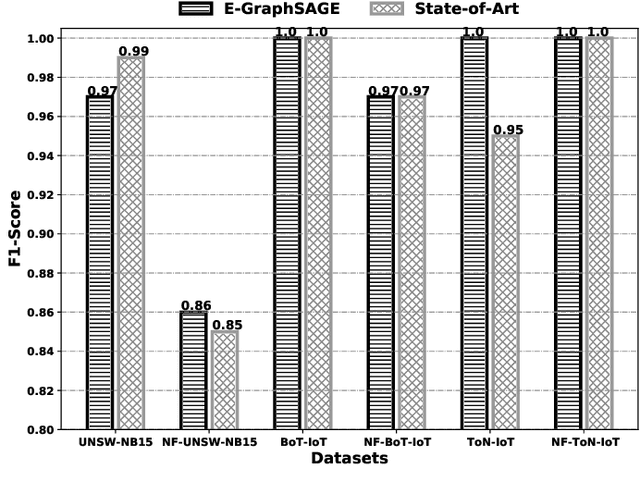
This paper presents a new network intrusion detection system (NIDS) based on Graph Neural Networks (GNNs). GNNs are a relatively new sub-field of deep neural networks, which have the unique ability to leverage the inherent structure of graph-based data. Training and evaluation data for NIDSs are typically represented as flow records, which can naturally be represented in a graph format. This establishes the potential and motivation for exploring GNNs for the purpose of network intrusion detection, which is the focus of this paper. E-GraphSAGE, our proposed new approach is based on the established GraphSAGE model, but provides the necessary modifications in order to support edge features for edge classification, and hence the classification of network flows into benign and attack classes. An extensive experimental evaluation based on six recent NIDS benchmark datasets shows the excellent performance of our E-GraphSAGE based NIDS in comparison with the state-of-the-art.
Exploring Edge TPU for Network Intrusion Detection in IoT
Mar 30, 2021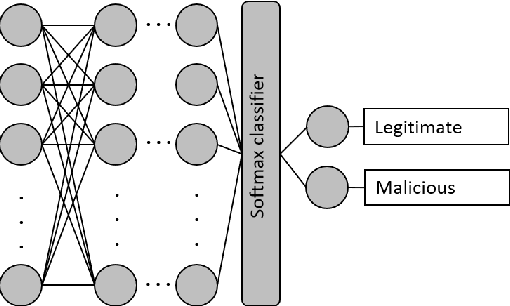
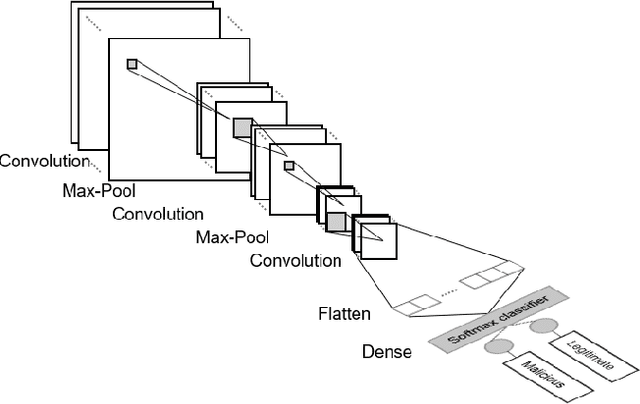

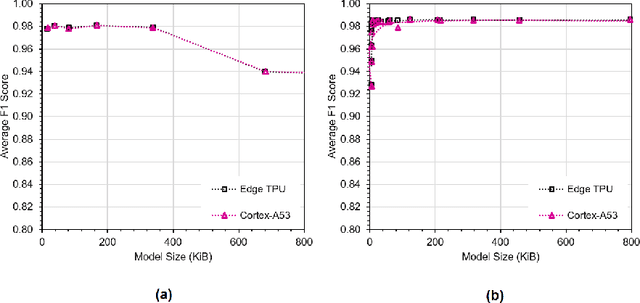
This paper explores Google's Edge TPU for implementing a practical network intrusion detection system (NIDS) at the edge of IoT, based on a deep learning approach. While there are a significant number of related works that explore machine learning based NIDS for the IoT edge, they generally do not consider the issue of the required computational and energy resources. The focus of this paper is the exploration of deep learning-based NIDS at the edge of IoT, and in particular the computational and energy efficiency. In particular, the paper studies Google's Edge TPU as a hardware platform, and considers the following three key metrics: computation (inference) time, energy efficiency and the traffic classification performance. Various scaled model sizes of two major deep neural network architectures are used to investigate these three metrics. The performance of the Edge TPU-based implementation is compared with that of an energy efficient embedded CPU (ARM Cortex A53). Our experimental evaluation shows some unexpected results, such as the fact that the CPU significantly outperforms the Edge TPU for small model sizes.
Deep Learning-based Cattle Activity Classification Using Joint Time-frequency Data Representation
Nov 06, 2020

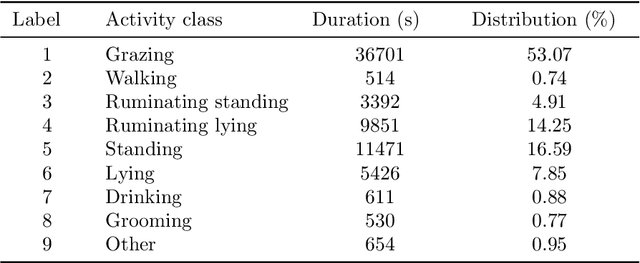
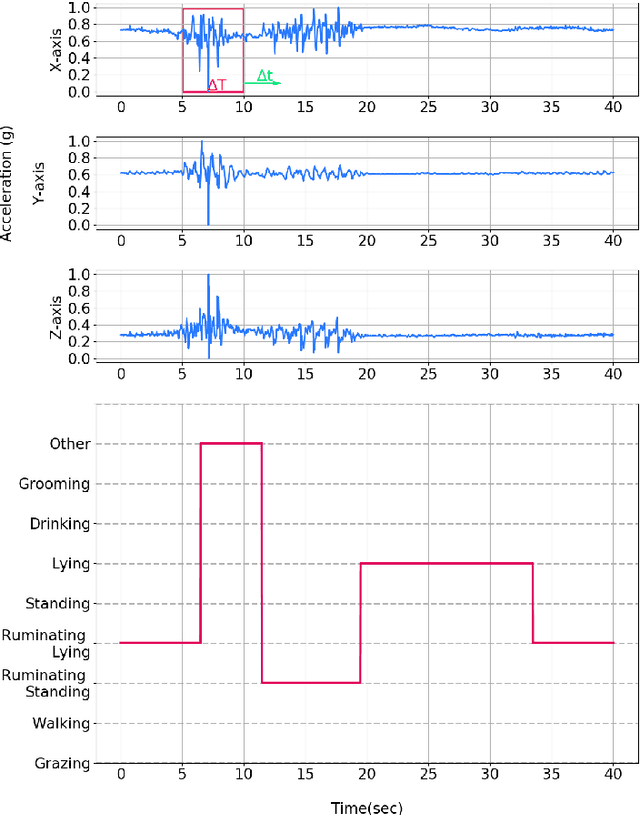
Automated cattle activity classification allows herders to continuously monitor the health and well-being of livestock, resulting in increased quality and quantity of beef and dairy products. In this paper, a sequential deep neural network is used to develop a behavioural model and to classify cattle behaviour and activities. The key focus of this paper is the exploration of a joint time-frequency domain representation of the sensor data, which is provided as the input to the neural network classifier. Our exploration is based on a real-world data set with over 3 million samples, collected from sensors with a tri-axial accelerometer, magnetometer and gyroscope, attached to collar tags of 10 dairy cows and collected over a one month period. The key results of this paper is that the joint time-frequency data representation, even when used in conjunction with a relatively basic neural network classifier, can outperform the best cattle activity classifiers reported in the literature. With a more systematic exploration of neural network classifier architectures and hyper-parameters, there is potential for even further improvements. Finally, we demonstrate that the time-frequency domain data representation allows us to efficiently trade-off a large reduction of model size and computational complexity for a very minor reduction in classification accuracy. This shows the potential for our classification approach to run on resource-constrained embedded and IoT devices.