 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Worse and Better Opinions. Unsupervised and Agnostic Aggregation of Online Reviews
Apr 18, 2017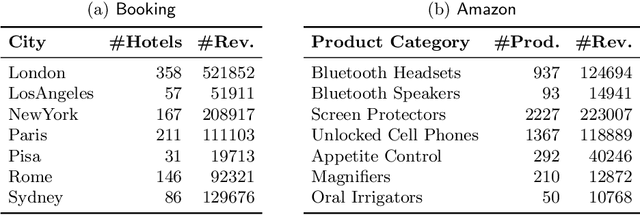
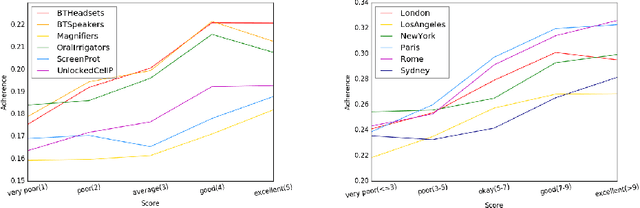

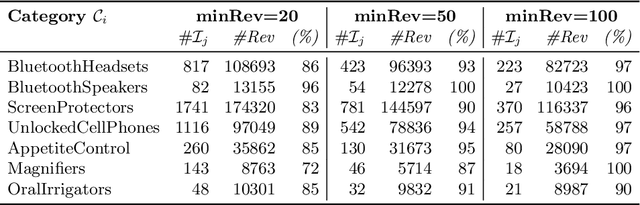
In this paper, we propose a novel approach for aggregating online reviews, according to the opinions they express. Our methodology is unsupervised - due to the fact that it does not rely on pre-labeled reviews - and it is agnostic - since it does not make any assumption about the domain or the language of the review content. We measure the adherence of a review content to the domain terminology extracted from a review set. First, we demonstrate the informativeness of the adherence metric with respect to the score associated with a review. Then, we exploit the metric values to group reviews, according to the opinions they express. Our experimental campaign has been carried out on two large datasets collected from Booking and Amazon, respectively.
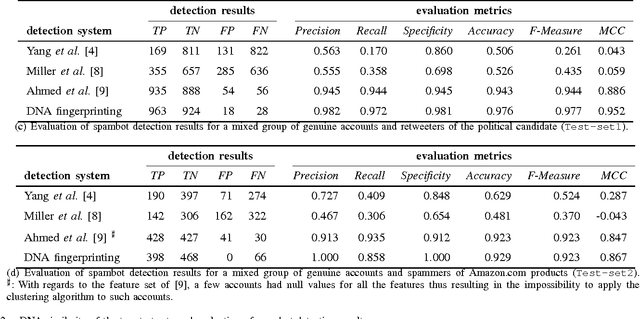
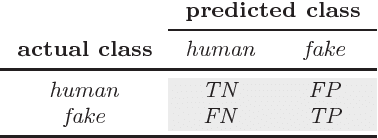
Social Fingerprinting: detection of spambot groups through DNA-inspired behavioral modeling
Mar 13, 2017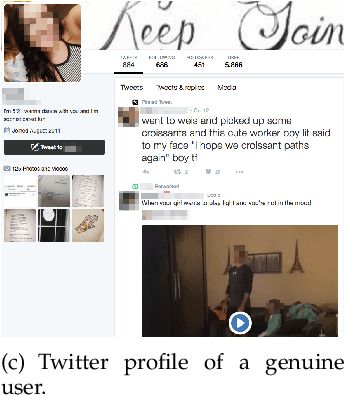

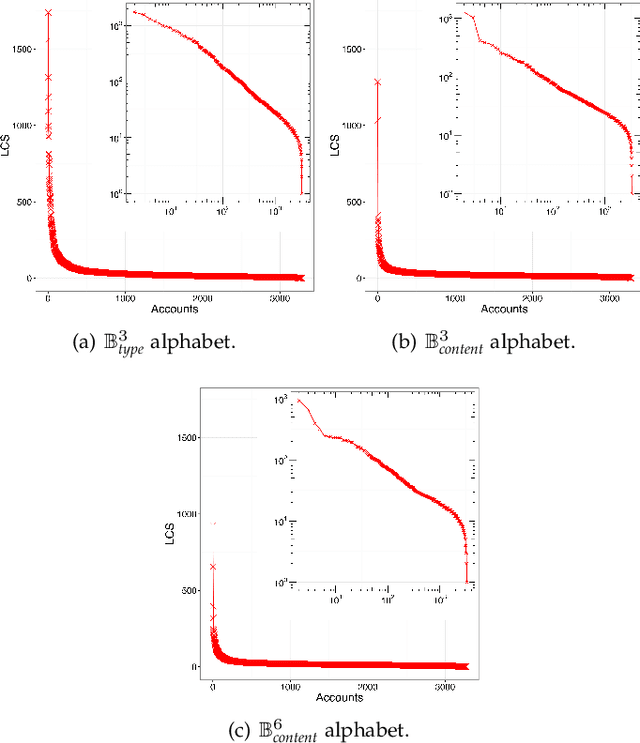
Spambot detection in online social networks is a long-lasting challenge involving the study and design of detection techniques capable of efficiently identifying ever-evolving spammers. Recently, a new wave of social spambots has emerged, with advanced human-like characteristics that allow them to go undetected even by current state-of-the-art algorithms. In this paper, we show that efficient spambots detection can be achieved via an in-depth analysis of their collective behaviors exploiting the digital DNA technique for modeling the behaviors of social network users. Inspired by its biological counterpart, in the digital DNA representation the behavioral lifetime of a digital account is encoded in a sequence of characters. Then, we define a similarity measure for such digital DNA sequences. We build upon digital DNA and the similarity between groups of users to characterize both genuine accounts and spambots. Leveraging such characterization, we design the Social Fingerprinting technique, which is able to discriminate among spambots and genuine accounts in both a supervised and an unsupervised fashion. We finally evaluate the effectiveness of Social Fingerprinting and we compare it with three state-of-the-art detection algorithms. Among the peculiarities of our approach is the possibility to apply off-the-shelf DNA analysis techniques to study online users behaviors and to efficiently rely on a limited number of lightweight account characteristics.
Semi-supervised knowledge extraction for detection of drugs and their effects
Sep 21, 2016
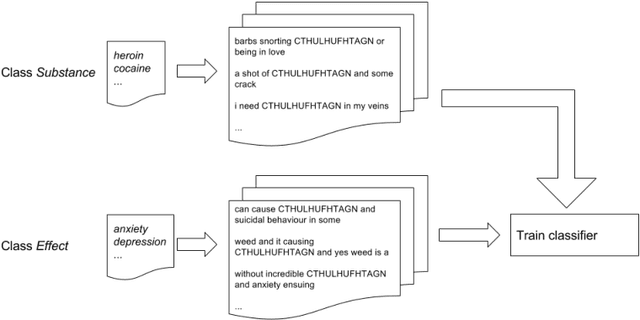
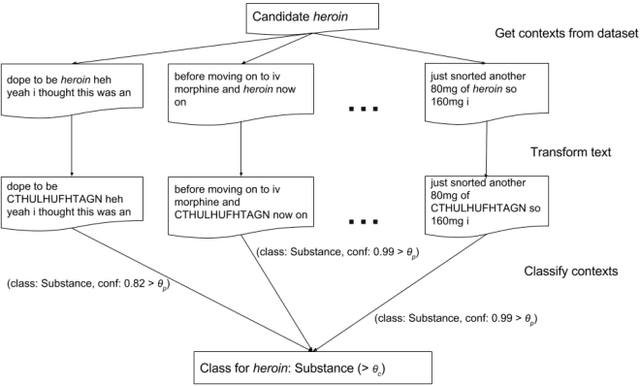
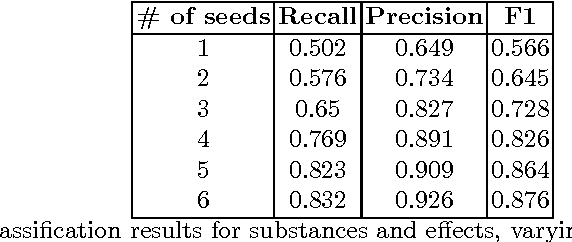
New Psychoactive Substances (NPS) are drugs that lay in a grey area of legislation, since they are not internationally and officially banned, possibly leading to their not prosecutable trade. The exacerbation of the phenomenon is that NPS can be easily sold and bought online. Here, we consider large corpora of textual posts, published on online forums specialized on drug discussions, plus a small set of known substances and associated effects, which we call seeds. We propose a semi-supervised approach to knowledge extraction, applied to the detection of drugs (comprising NPS) and effects from the corpora under investigation. Based on the very small set of initial seeds, the work highlights how a contrastive approach and context deduction are effective in detecting substances and effects from the corpora. Our promising results, which feature a F1 score close to 0.9, pave the way for shortening the detection time of new psychoactive substances, once these are discussed and advertised on the Internet.
A matter of words: NLP for quality evaluation of Wikipedia medical articles
Mar 07, 2016
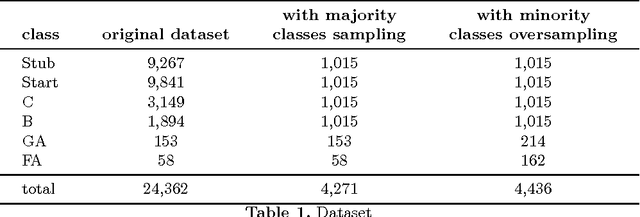

Automatic quality evaluation of Web information is a task with many fields of applications and of great relevance, especially in critical domains like the medical one. We move from the intuition that the quality of content of medical Web documents is affected by features related with the specific domain. First, the usage of a specific vocabulary (Domain Informativeness); then, the adoption of specific codes (like those used in the infoboxes of Wikipedia articles) and the type of document (e.g., historical and technical ones). In this paper, we propose to leverage specific domain features to improve the results of the evaluation of Wikipedia medical articles. In particular, we evaluate the articles adopting an "actionable" model, whose features are related to the content of the articles, so that the model can also directly suggest strategies for improving a given article quality. We rely on Natural Language Processing (NLP) and dictionaries-based techniques in order to extract the bio-medical concepts in a text. We prove the effectiveness of our approach by classifying the medical articles of the Wikipedia Medicine Portal, which have been previously manually labeled by the Wiki Project team. The results of our experiments confirm that, by considering domain-oriented features, it is possible to obtain sensible improvements with respect to existing solutions, mainly for those articles that other approaches have less correctly classified. Other than being interesting by their own, the results call for further research in the area of domain specific features suitable for Web data quality assessment.
DNA-inspired online behavioral modeling and its application to spambot detection
Jan 30, 2016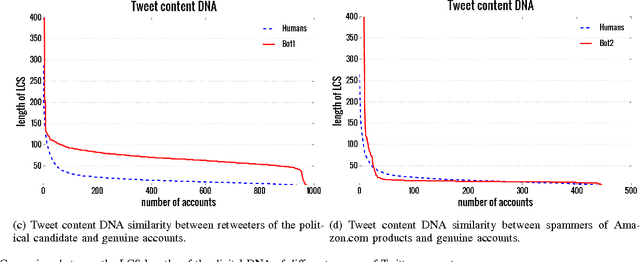
We propose a strikingly novel, simple, and effective approach to model online user behavior: we extract and analyze digital DNA sequences from user online actions and we use Twitter as a benchmark to test our proposal. We obtain an incisive and compact DNA-inspired characterization of user actions. Then, we apply standard DNA analysis techniques to discriminate between genuine and spambot accounts on Twitter. An experimental campaign supports our proposal, showing its effectiveness and viability. To the best of our knowledge, we are the first ones to identify and adapt DNA-inspired techniques to online user behavioral modeling. While Twitter spambot detection is a specific use case on a specific social media, our proposed methodology is platform and technology agnostic, hence paving the way for diverse behavioral characterization tasks.
Fame for sale: efficient detection of fake Twitter followers
Nov 10, 2015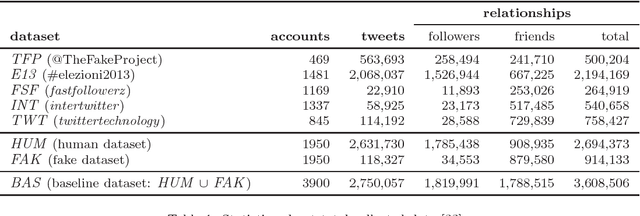


$\textit{Fake followers}$ are those Twitter accounts specifically created to inflate the number of followers of a target account. Fake followers are dangerous for the social platform and beyond, since they may alter concepts like popularity and influence in the Twittersphere - hence impacting on economy, politics, and society. In this paper, we contribute along different dimensions. First, we review some of the most relevant existing features and rules (proposed by Academia and Media) for anomalous Twitter accounts detection. Second, we create a baseline dataset of verified human and fake follower accounts. Such baseline dataset is publicly available to the scientific community. Then, we exploit the baseline dataset to train a set of machine-learning classifiers built over the reviewed rules and features. Our results show that most of the rules proposed by Media provide unsatisfactory performance in revealing fake followers, while features proposed in the past by Academia for spam detection provide good results. Building on the most promising features, we revise the classifiers both in terms of reduction of overfitting and cost for gathering the data needed to compute the features. The final result is a novel $\textit{Class A}$ classifier, general enough to thwart overfitting, lightweight thanks to the usage of the less costly features, and still able to correctly classify more than 95% of the accounts of the original training set. We ultimately perform an information fusion-based sensitivity analysis, to assess the global sensitivity of each of the features employed by the classifier. The findings reported in this paper, other than being supported by a thorough experimental methodology and interesting on their own, also pave the way for further investigation on the novel issue of fake Twitter followers.