 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpus Statistics in Text Classification of Online Data
Mar 16, 2018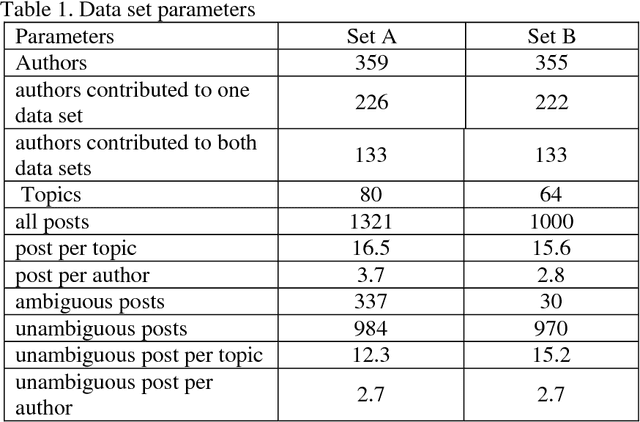
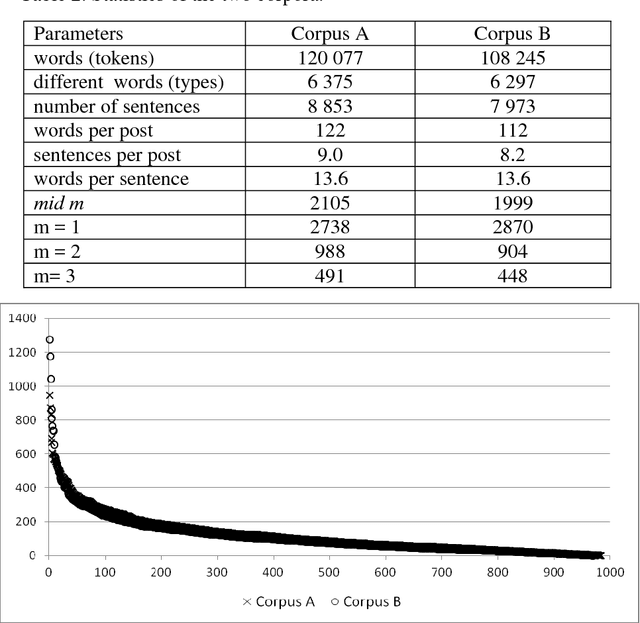
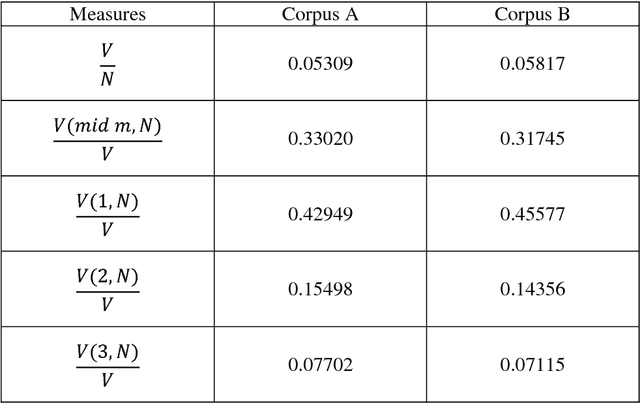
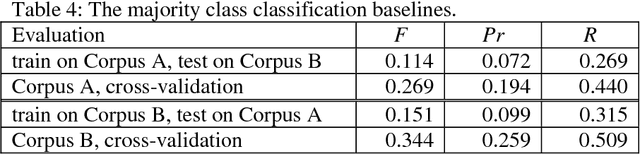
Transformation of Machine Learning (ML) from a boutique science to a generally accepted technology has increased importance of reproduction and transportability of ML studies. In the current work, we investigate how corpus characteristics of textual data sets correspond to text classification results. We work with two data sets gathered from sub-forums of an online health-related forum. Our empirical results are obtained for a multi-class sentiment analysis application.
One Single Deep Bidirectional LSTM Network for Word Sense Disambiguation of Text Data
Feb 25, 2018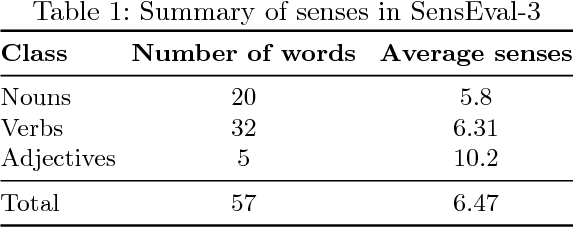
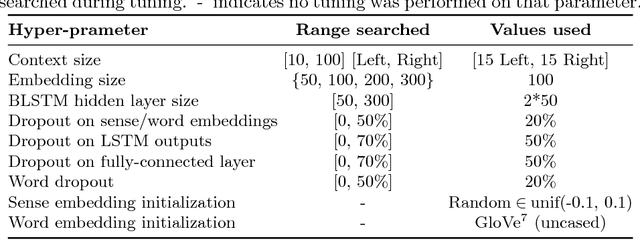
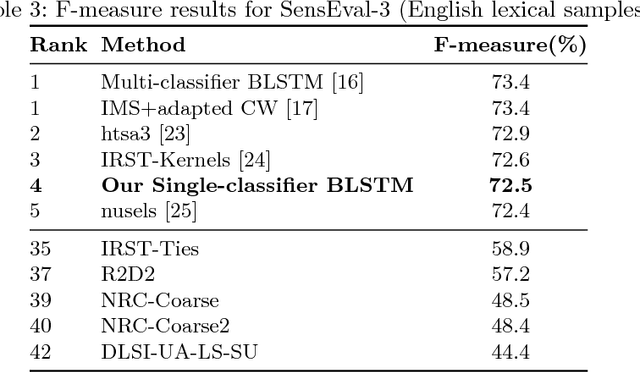

Due to recent technical and scientific advances, we have a wealth of information hidden in unstructured text data such as offline/online narratives, research articles, and clinical reports. To mine these data properly, attributable to their innate ambiguity, a Word Sense Disambiguation (WSD) algorithm can avoid numbers of difficulties in Natural Language Processing (NLP) pipeline. However, considering a large number of ambiguous words in one language or technical domain, we may encounter limiting constraints for proper deployment of existing WSD models. This paper attempts to address the problem of one-classifier-per-one-word WSD algorithms by proposing a single Bidirectional Long Short-Term Memory (BLSTM) network which by considering senses and context sequences works on all ambiguous words collectively. Evaluated on SensEval-3 benchmark, we show the result of our model is comparable with top-performing WSD algorithms. We also discuss how applying additional modifications alleviates the model fault and the need for more training data.
Studying Positive Speech on Twitter
Feb 24, 2017
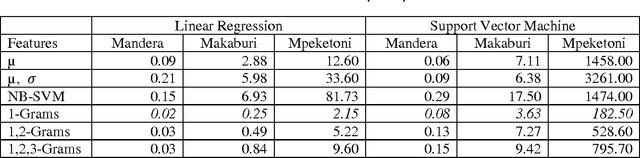

We present results of empirical studies on positive speech on Twitter. By positive speech we understand speech that works for the betterment of a given situation, in this case relations between different communities in a conflict-prone country. We worked with four Twitter data sets. Through semi-manual opinion mining, we found that positive speech accounted for < 1% of the data . In fully automated studies, we tested two approaches: unsupervised statistical analysis, and supervised text classification based on distributed word representation. We discuss benefits and challenges of those approaches and report empirical evidence obtained in the study.
Topic Modelling and Event Identification from Twitter Textual Data
Aug 08, 2016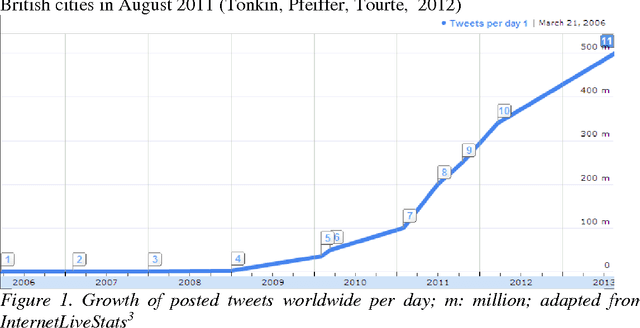
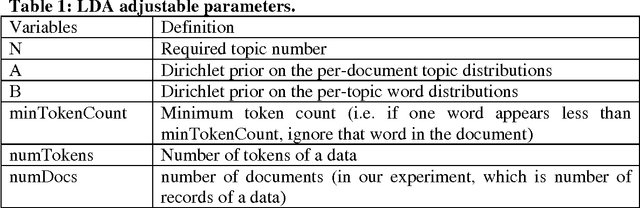
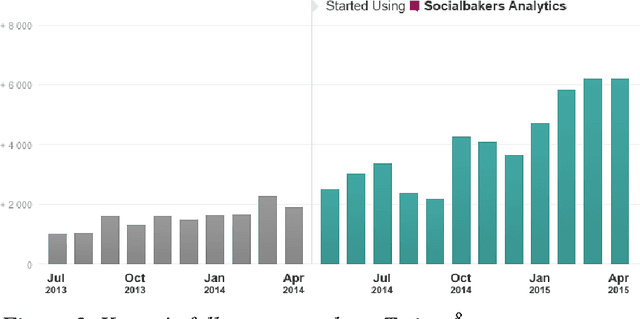
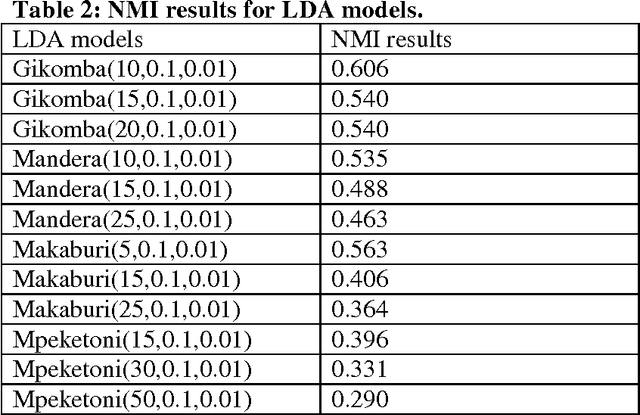
The tremendous growth of social media content on the Internet has inspired the development of the text analytics to understand and solve real-life problems. Leveraging statistical topic modelling helps researchers and practitioners in better comprehension of textual content as well as provides useful information for further analysis. Statistical topic modelling becomes especially important when we work with large volumes of dynamic text, e.g., Facebook or Twitter datasets. In this study, we summarize the message content of four data sets of Twitter messages relating to challenging social events in Kenya. We use Latent Dirichlet Allocation (LDA) topic modelling to analyze the content. Our study uses two evaluation measures, Normalized Mutual Information (NMI) and topic coherence analysis, to select the best LDA models. The obtained LDA results show that the tool can be effectively used to extract discussion topics and summarize them for further manual analysis
Multi-Labeled Classification of Demographic Attributes of Patients: a case study of diabetics patients
Mar 26, 2015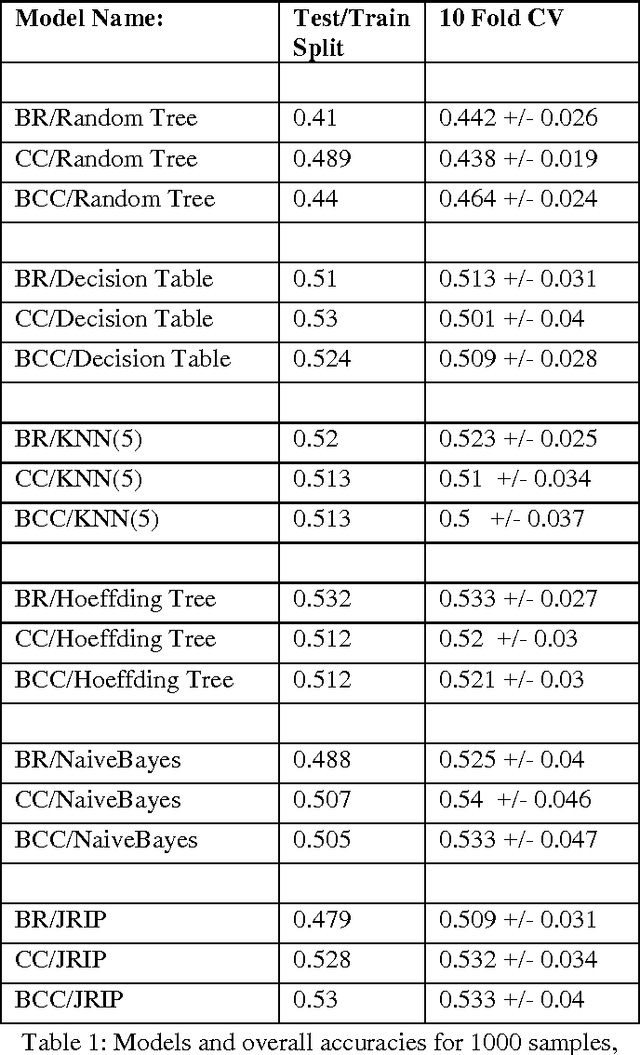
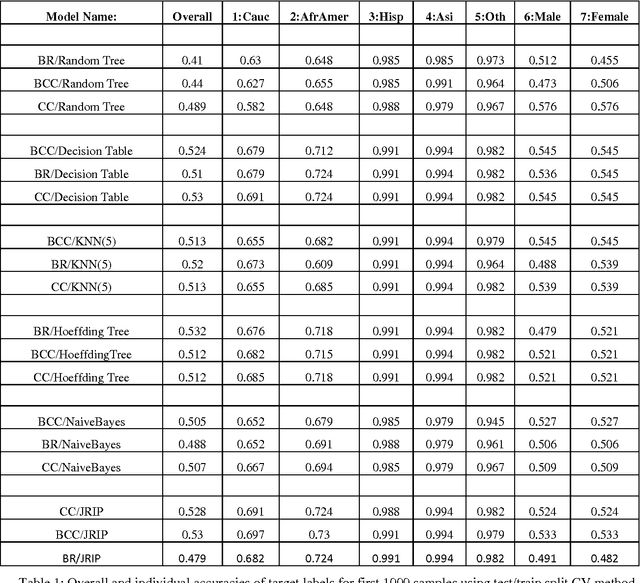

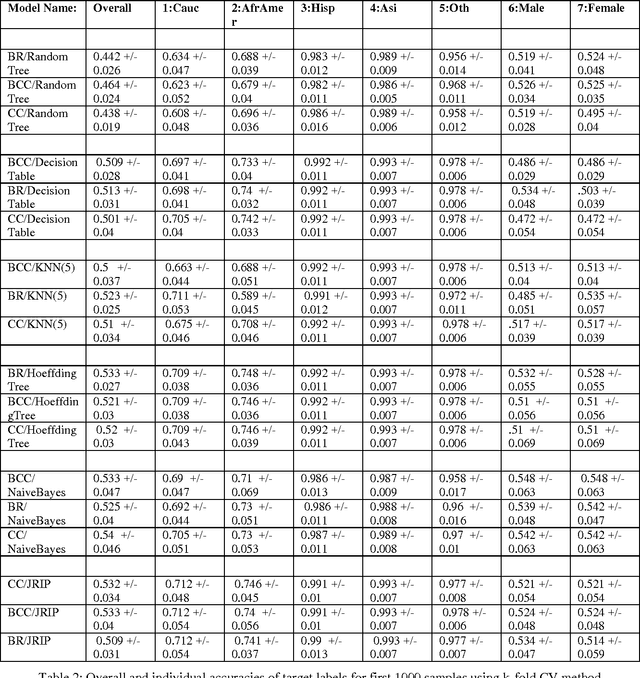
Automated learning of patients demographics can be seen as multi-label problem where a patient model is based on different race and gender groups. The resulting model can be further integrated into Privacy-Preserving Data Mining, where it can be used to assess risk of identification of different patient groups. Our project considers relations between diabetes and demographics of patients as a multi-labelled problem. Most research in this area has been done as binary classification, where the target class is finding if a person has diabetes or not. But very few, and maybe no work has been done in multi-labeled analysis of the demographics of patients who are likely to be diagnosed with diabetes. To identify such groups, we applied ensembles of several multi-label learning algorithms.