 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying Positive Speech on Twitter
Feb 24, 2017
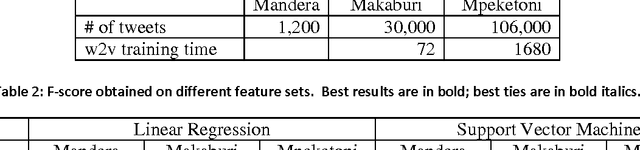
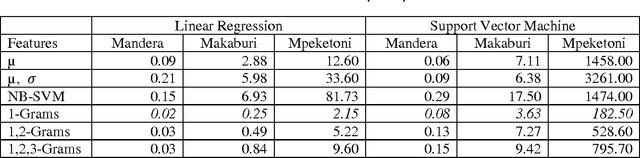

We present results of empirical studies on positive speech on Twitter. By positive speech we understand speech that works for the betterment of a given situation, in this case relations between different communities in a conflict-prone country. We worked with four Twitter data sets. Through semi-manual opinion mining, we found that positive speech accounted for < 1% of the data . In fully automated studies, we tested two approaches: unsupervised statistical analysis, and supervised text classification based on distributed word representation. We discuss benefits and challenges of those approaches and report empirical evidence obtained in the study.
Topic Modelling and Event Identification from Twitter Textual Data
Aug 08, 2016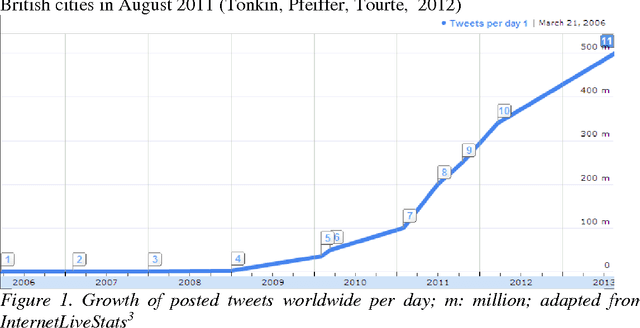
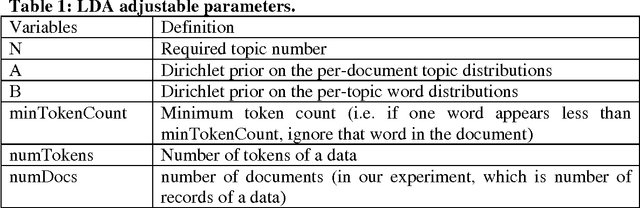
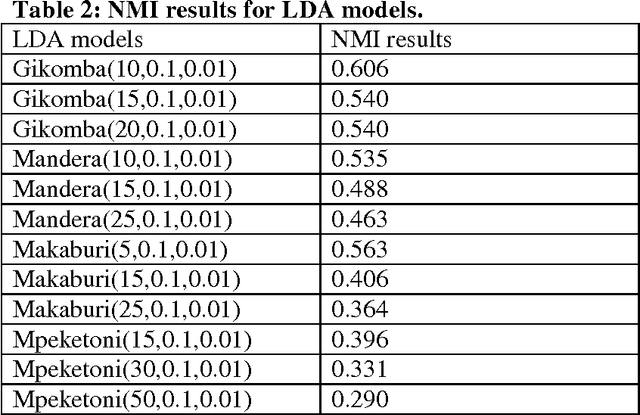
The tremendous growth of social media content on the Internet has inspired the development of the text analytics to understand and solve real-life problems. Leveraging statistical topic modelling helps researchers and practitioners in better comprehension of textual content as well as provides useful information for further analysis. Statistical topic modelling becomes especially important when we work with large volumes of dynamic text, e.g., Facebook or Twitter datasets. In this study, we summarize the message content of four data sets of Twitter messages relating to challenging social events in Kenya. We use Latent Dirichlet Allocation (LDA) topic modelling to analyze the content. Our study uses two evaluation measures, Normalized Mutual Information (NMI) and topic coherence analysis, to select the best LDA models. The obtained LDA results show that the tool can be effectively used to extract discussion topics and summarize them for further manual analysis