 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrative Variations in a Virtual Storyteller
Aug 29, 2017

Research on storytelling over the last 100 years has distinguished at least two levels of narrative representation (1) story, or fabula; and (2) discourse, or sujhet. We use this distinction to create Fabula Tales, a computational framework for a virtual storyteller that can tell the same story in different ways through the implementation of general narratological variations, such as varying direct vs. indirect speech, character voice (style), point of view, and focalization. A strength of our computational framework is that it is based on very general methods for re-using existing story content, either from fables or from personal narratives collected from blogs. We first explain how a simple annotation tool allows naive annotators to easily create a deep representation of fabula called a story intention graph, and show how we use this representation to generate story tellings automatically. Then we present results of two studies testing our narratological parameters, and showing that different tellings affect the reader's perception of the story and characters.
Generating Sentence Planning Variations for Story Telling
Aug 29, 2017
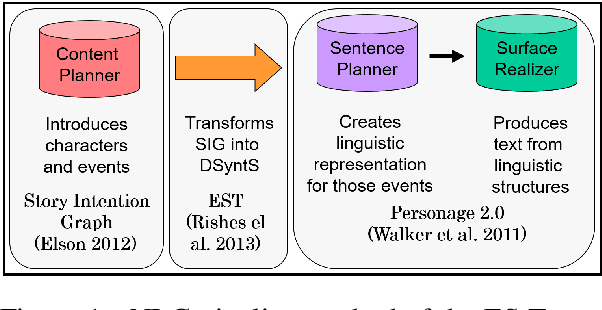

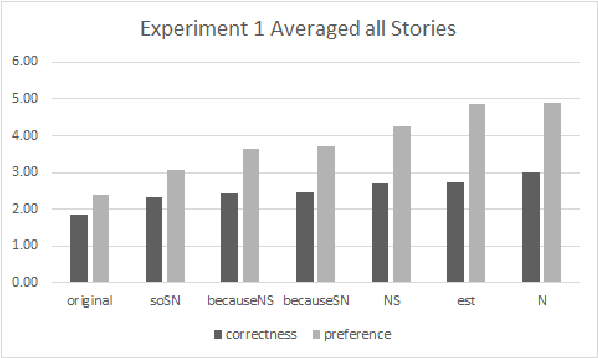
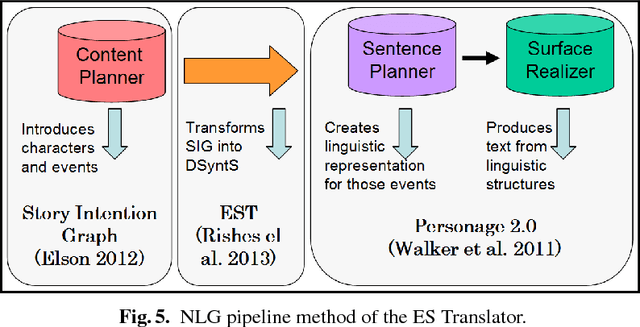
There has been a recent explosion in applications for dialogue interaction ranging from direction-giving and tourist information to interactive story systems. Yet the natural language generation (NLG) component for many of these systems remains largely handcrafted. This limitation greatly restricts the range of applications; it also means that it is impossible to take advantage of recent work in expressive and statistical language generation that can dynamically and automatically produce a large number of variations of given content. We propose that a solution to this problem lies in new methods for developing language generation resources. We describe the ES-Translator, a computational language generator that has previously been applied only to fables, and quantitatively evaluate the domain independence of the EST by applying it to personal narratives from weblogs. We then take advantage of recent work on language generation to create a parameterized sentence planner for story generation that provides aggregation operations, variations in discourse and in point of view. Finally, we present a user evaluation of different personal narrative retellings.
Identifying Subjective and Figurative Language in Online Dialogue
Aug 29, 2017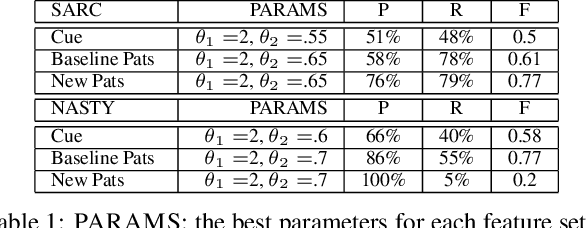
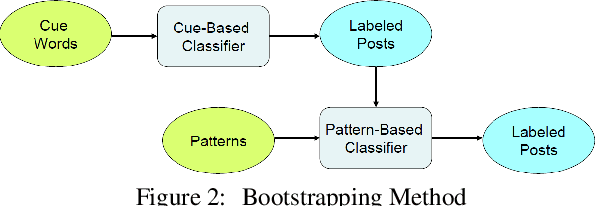
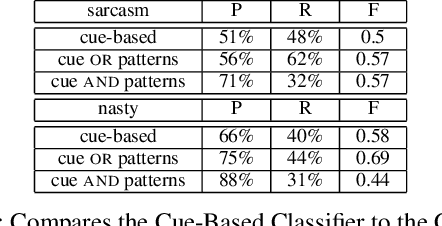
More and more of the information on the web is dialogic, from Facebook newsfeeds, to forum conversations, to comment threads on news articles. In contrast to traditional, monologic resources such as news, highly social dialogue is very frequent in social media. We aim to automatically identify sarcastic and nasty utterances in unannotated online dialogue, extending a bootstrapping method previously applied to the classification of monologic subjective sentences in Riloff and Weibe 2003. We have adapted the method to fit the sarcastic and nasty dialogic domain. Our method is as follows: 1) Explore methods for identifying sarcastic and nasty cue words and phrases in dialogues; 2) Use the learned cues to train a sarcastic (nasty) Cue-Based Classifier; 3) Learn general syntactic extraction patterns from the sarcastic (nasty) utterances and define fine-tuned sarcastic patterns to create a Pattern-Based Classifier; 4) Combine both Cue-Based and fine-tuned Pattern-Based Classifiers to maximize precision at the expense of recall and test on unannotated utterances.
Generating Different Story Tellings from Semantic Representations of Narrative
Aug 29, 2017
In order to tell stories in different voices for different audiences, interactive story systems require: (1) a semantic representation of story structure, and (2) the ability to automatically generate story and dialogue from this semantic representation using some form of Natural Language Generation (NLG). However, there has been limited research on methods for linking story structures to narrative descriptions of scenes and story events. In this paper we present an automatic method for converting from Scheherazade's story intention graph, a semantic representation, to the input required by the Personage NLG engine. Using 36 Aesop Fables distributed in DramaBank, a collection of story encodings, we train translation rules on one story and then test these rules by generating text for the remaining 35. The results are measured in terms of the string similarity metrics Levenshtein Distance and BLEU score. The results show that we can generate the 35 stories with correct content: the test set stories on average are close to the output of the Scheherazade realizer, which was customized to this semantic representation. We provide some examples of story variations generated by personage. In future work, we will experiment with measuring the quality of the same stories generated in different voices, and with techniques for making storytelling interactive.
M2D: Monolog to Dialog Generation for Conversational Story Telling
Aug 24, 2017
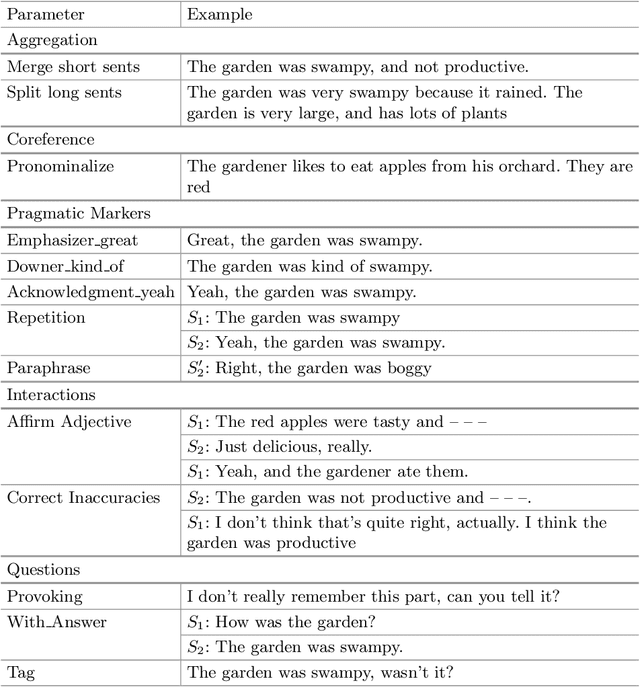
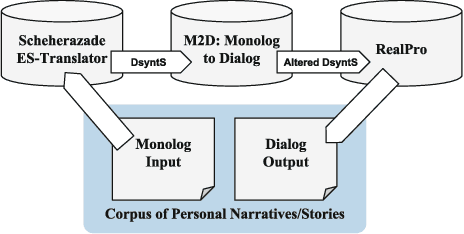
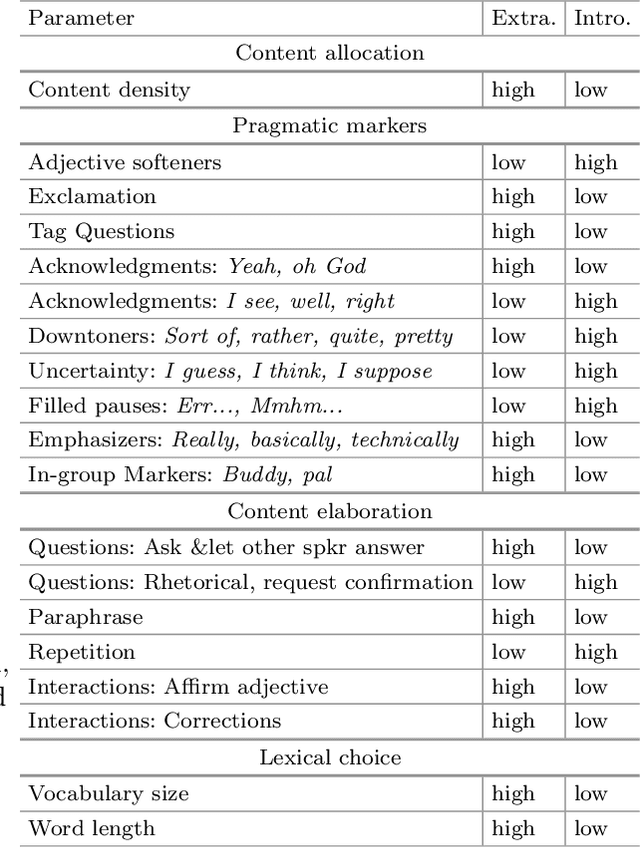
Storytelling serves many different social functions, e.g. stories are used to persuade, share troubles, establish shared values, learn social behaviors, and entertain. Moreover, stories are often told conversationally through dialog, and previous work suggests that information provided dialogically is more engaging than when provided in monolog. In this paper, we present algorithms for converting a deep representation of a story into a dialogic storytelling, that can vary aspects of the telling, including the personality of the storytellers. We conduct several experiments to test whether dialogic storytellings are more engaging, and whether automatically generated variants in linguistic form that correspond to personality differences can be recognized in an extended storytelling dialog.
Centering, Anaphora Resolution, and Discourse Structure
Aug 11, 1997

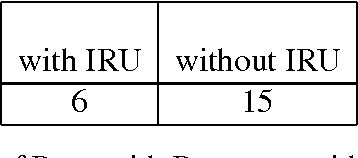
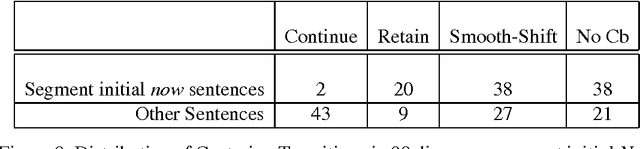
Centering was formulated as a model of the relationship between attentional state, the form of referring expressions, and the coherence of an utterance within a discourse segment (Grosz, Joshi and Weinstein, 1986; Grosz, Joshi and Weinstein, 1995). In this chapter, I argue that the restriction of centering to operating within a discourse segment should be abandoned in order to integrate centering with a model of global discourse structure. The within-segment restriction causes three problems. The first problem is that centers are often continued over discourse segment boundaries with pronominal referring expressions whose form is identical to those that occur within a discourse segment. The second problem is that recent work has shown that listeners perceive segment boundaries at various levels of granularity. If centering models a universal processing phenomenon, it is implausible that each listener is using a different centering algorithm.The third issue is that even for utterances within a discourse segment, there are strong contrasts between utterances whose adjacent utterance within a segment is hierarchically recent and those whose adjacent utterance within a segment is linearly recent. This chapter argues that these problems can be eliminated by replacing Grosz and Sidner's stack model of attentional state with an alternate model, the cache model. I show how the cache model is easily integrated with the centering algorithm, and provide several types of data from naturally occurring discourses that support the proposed integrated model. Future work should provide additional support for these claims with an examination of a larger corpus of naturally occurring discourses.
* 35 pages, uses elsart12, lingmacros, named, psfig
PARADISE: A Framework for Evaluating Spoken Dialogue Agents
Apr 15, 1997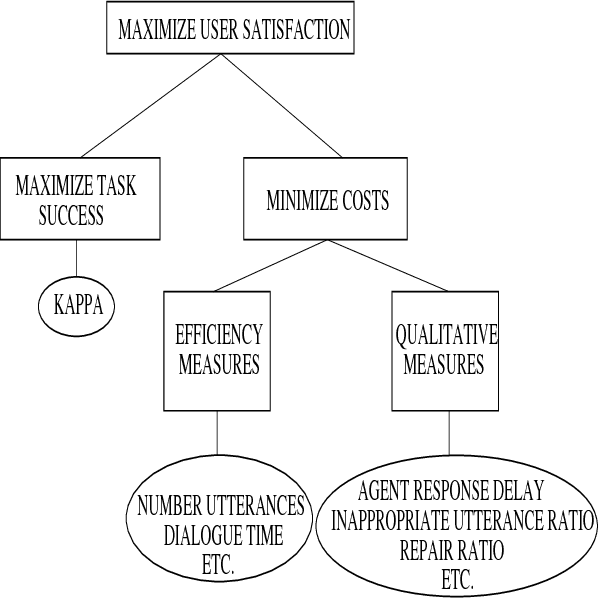



This paper presents PARADISE (PARAdigm for DIalogue System Evaluation), a general framework for evaluating spoken dialogue agents. The framework decouples task requirements from an agent's dialogue behaviors, supports comparisons among dialogue strategies, enables the calculation of performance over subdialogues and whole dialogues, specifies the relative contribution of various factors to performance, and makes it possible to compare agents performing different tasks by normalizing for task complexity.
* 10 pages, uses aclap, psfig, lingmacros, times
Improvising Linguistic Style: Social and Affective Bases for Agent Personality
Feb 26, 1997
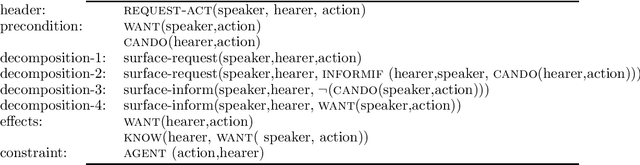


This paper introduces Linguistic Style Improvisation, a theory and set of algorithms for improvisation of spoken utterances by artificial agents, with applications to interactive story and dialogue systems. We argue that linguistic style is a key aspect of character, and show how speech act representations common in AI can provide abstract representations from which computer characters can improvise. We show that the mechanisms proposed introduce the possibility of socially oriented agents, meet the requirements that lifelike characters be believable, and satisfy particular criteria for improvisation proposed by Hayes-Roth.
* 10 pages, uses aaai.sty, lingmacros.sty, psfig.sty
Inferring Acceptance and Rejection in Dialogue by Default Rules of Inference
Sep 07, 1996
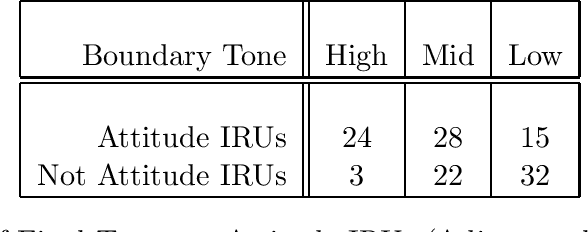

This paper discusses the processes by which conversants in a dialogue can infer whether their assertions and proposals have been accepted or rejected by their conversational partners. It expands on previous work by showing that logical consistency is a necessary indicator of acceptance, but that it is not sufficient, and that logical inconsistency is sufficient as an indicator of rejection, but it is not necessary. I show how conversants can use information structure and prosody as well as logical reasoning in distinguishing between acceptances and logically consistent rejections, and relate this work to previous work on implicature and default reasoning by introducing three new classes of rejection: {\sc implicature rejections}, {\sc epistemic rejections} and {\sc deliberation rejections}. I show how these rejections are inferred as a result of default inferences, which, by other analyses, would have been blocked by the context. In order to account for these facts, I propose a model of the common ground that allows these default inferences to go through, and show how the model, originally proposed to account for the various forms of acceptance, can also model all types of rejection.
* 37 pages, uses fullpage, lingmacros, named
Limited Attention and Discourse Structure
Aug 14, 1996

This squib examines the role of limited attention in a theory of discourse structure and proposes a model of attentional state that relates current hierarchical theories of discourse structure to empirical evidence about human discourse processing capabilities. First, I present examples that are not predicted by Grosz and Sidner's stack model of attentional state. Then I consider an alternative model of attentional state, the cache model, which accounts for the examples, and which makes particular processing predictions. Finally I suggest a number of ways that future research could distinguish the predictions of the cache model and the stack model.