 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirically Evaluating an Adaptable Spoken Dialogue System
Mar 05, 1999

Recent technological advances have made it possible to build real-time, interactive spoken dialogue systems for a wide variety of applications. However, when users do not respect the limitations of such systems, performance typically degrades. Although users differ with respect to their knowledge of system limitations, and although different dialogue strategies make system limitations more apparent to users, most current systems do not try to improve performance by adapting dialogue behavior to individual users. This paper presents an empirical evaluation of TOOT, an adaptable spoken dialogue system for retrieving train schedules on the web. We conduct an experiment in which 20 users carry out 4 tasks with both adaptable and non-adaptable versions of TOOT, resulting in a corpus of 80 dialogues. The values for a wide range of evaluation measures are then extracted from this corpus. Our results show that adaptable TOOT generally outperforms non-adaptable TOOT, and that the utility of adaptation depends on TOOT's initial dialogue strategies.
PARADISE: A Framework for Evaluating Spoken Dialogue Agents
Apr 15, 1997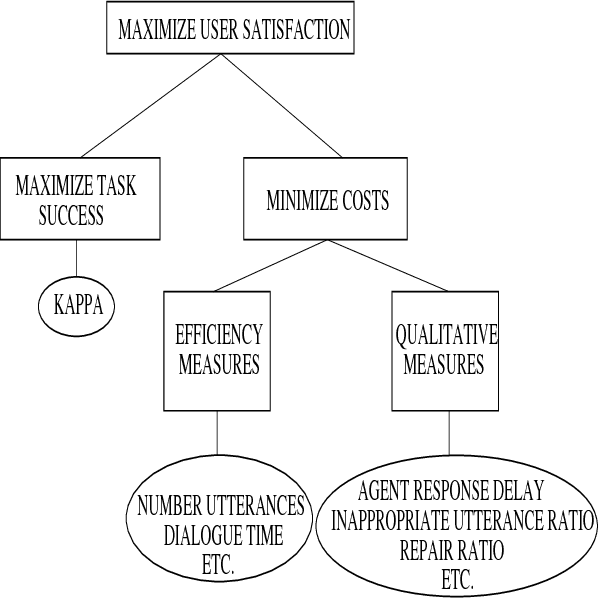



This paper presents PARADISE (PARAdigm for DIalogue System Evaluation), a general framework for evaluating spoken dialogue agents. The framework decouples task requirements from an agent's dialogue behaviors, supports comparisons among dialogue strategies, enables the calculation of performance over subdialogues and whole dialogues, specifies the relative contribution of various factors to performance, and makes it possible to compare agents performing different tasks by normalizing for task complexity.
* 10 pages, uses aclap, psfig, lingmacros, times
Cue Phrase Classification Using Machine Learning
Sep 09, 1996


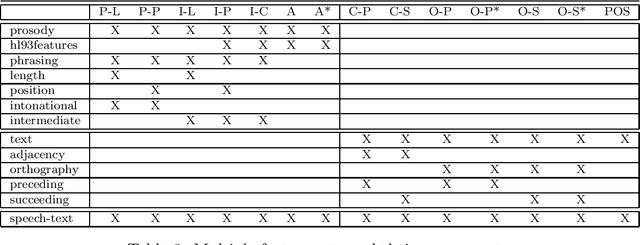
Cue phrases may be used in a discourse sense to explicitly signal discourse structure, but also in a sentential sense to convey semantic rather than structural information. Correctly classifying cue phrases as discourse or sentential is critical in natural language processing systems that exploit discourse structure, e.g., for performing tasks such as anaphora resolution and plan recognition. This paper explores the use of machine learning for classifying cue phrases as discourse or sentential. Two machine learning programs (Cgrendel and C4.5) are used to induce classification models from sets of pre-classified cue phrases and their features in text and speech. Machine learning is shown to be an effective technique for not only automating the generation of classification models, but also for improving upon previous results. When compared to manually derived classification models already in the literature, the learned models often perform with higher accuracy and contain new linguistic insights into the data. In addition, the ability to automatically construct classification models makes it easier to comparatively analyze the utility of alternative feature representations of the data. Finally, the ease of retraining makes the learning approach more scalable and flexible than manual methods.
* 42 pages, uses jair.sty, theapa.bst, theapa.sty
Combining Multiple Knowledge Sources for Discourse Segmentation
May 10, 1995

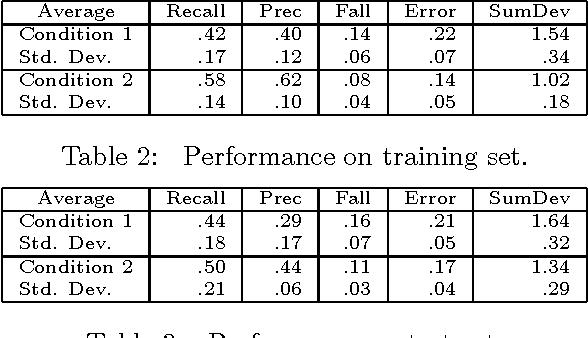
We predict discourse segment boundaries from linguistic features of utterances, using a corpus of spoken narratives as data. We present two methods for developing segmentation algorithms from training data: hand tuning and machine learning. When multiple types of features are used, results approach human performance on an independent test set (both methods), and using cross-validation (machine learning).
Intention-based Segmentation: Human Reliability and Correlation with Linguistic Cues
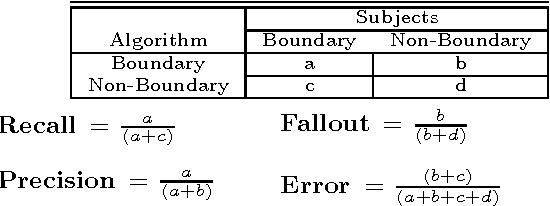
May 09, 1994Certain spans of utterances in a discourse, referred to here as segments, are widely assumed to form coherent units. Further, the segmental structure of discourse has been claimed to constrain and be constrained by many phenomena. However, there is weak consensus on the nature of segments and the criteria for recognizing or generating them. We present quantitative results of a two part study using a corpus of spontaneous, narrative monologues. The first part evaluates the statistical reliability of human segmentation of our corpus, where speaker intention is the segmentation criterion. We then use the subjects' segmentations to evaluate the correlation of discourse segmentation with three linguistic cues (referential noun phrases, cue words, and pauses), using information retrieval metrics.
Classifying Cue Phrases in Text and Speech Using Machine Learning
May 09, 1994Cue phrases may be used in a discourse sense to explicitly signal discourse structure, but also in a sentential sense to convey semantic rather than structural information. This paper explores the use of machine learning for classifying cue phrases as discourse or sentential. Two machine learning programs (Cgrendel and C4.5) are used to induce classification rules from sets of pre-classified cue phrases and their features. Machine learning is shown to be an effective technique for not only automating the generation of classification rules, but also for improving upon previous results.