 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemSketches-2021: experimenting with the machine processing of the pilot semantic sketches corpus
May 23, 2025The paper deals with elaborating different approaches to the machine processing of semantic sketches. It presents the pilot open corpus of semantic sketches. Different aspects of creating the sketches are discussed, as well as the tasks that the sketches can help to solve. Special attention is paid to the creation of the machine processing tools for the corpus. For this purpose, the SemSketches-2021 Shared Task was organized. The participants were given the anonymous sketches and a set of contexts containing the necessary predicates. During the Task, one had to assign the proper contexts to the corresponding sketches.
The Pilot Corpus of the English Semantic Sketches
May 23, 2025The paper is devoted to the creation of the semantic sketches for English verbs. The pilot corpus consists of the English-Russian sketch pairs and is aimed to show what kind of contrastive studies the sketches help to conduct. Special attention is paid to the cross-language differences between the sketches with similar semantics. Moreover, we discuss the process of building a semantic sketch, and analyse the mistakes that could give insight to the linguistic nature of sketches.
Zhestyatsky at SemEval-2021 Task 2: ReLU over Cosine Similarity for BERT Fine-tuning
Apr 13, 2021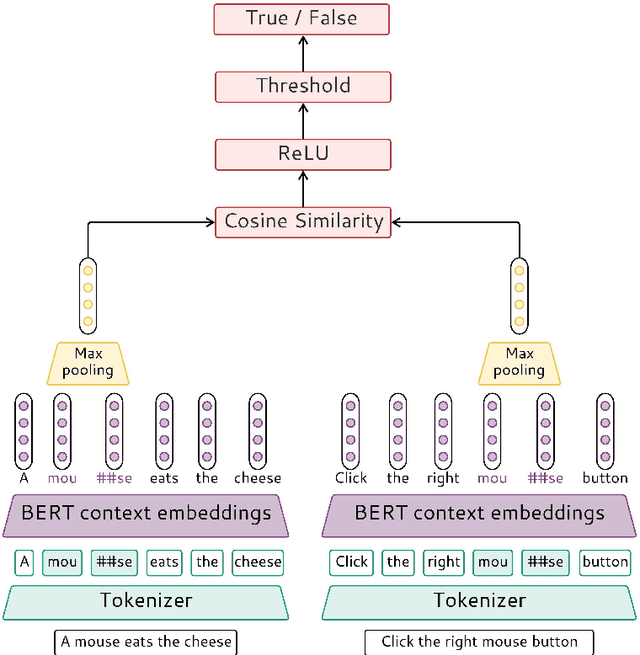
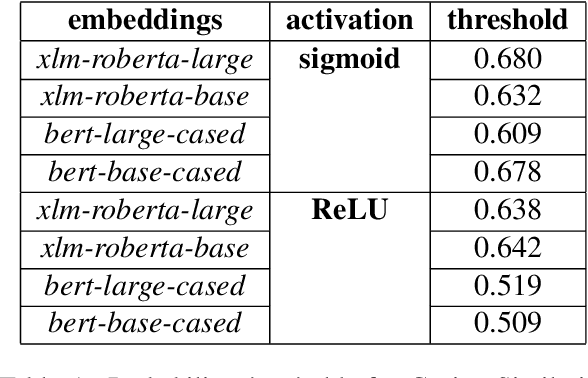
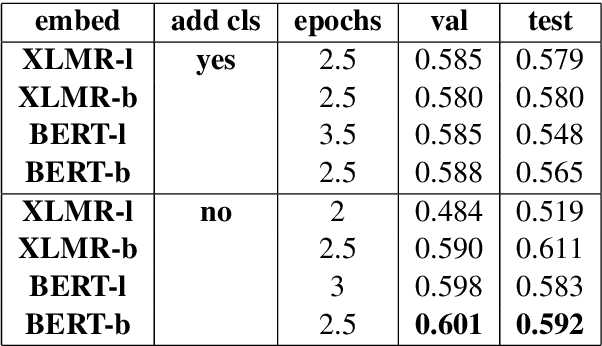
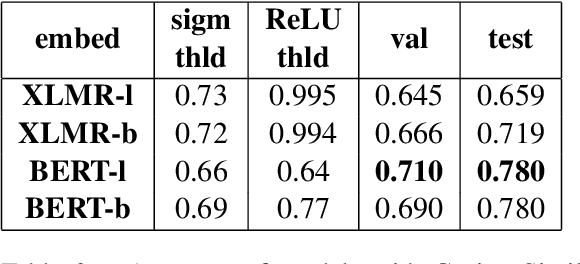
This paper presents our contribution to SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation (MCL-WiC). Our experiments cover English (EN-EN) sub-track from the multilingual setting of the task. We experiment with several pre-trained language models and investigate an impact of different top-layers on fine-tuning. We find the combination of Cosine Similarity and ReLU activation leading to the most effective fine-tuning procedure. Our best model results in accuracy 92.7%, which is the fourth-best score in EN-EN sub-track.
Automated Word Stress Detection in Russian
Jul 12, 2019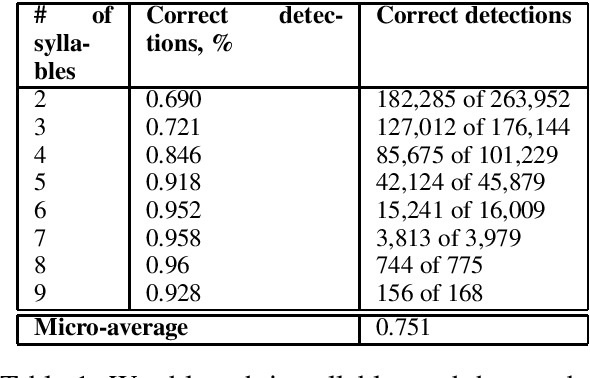
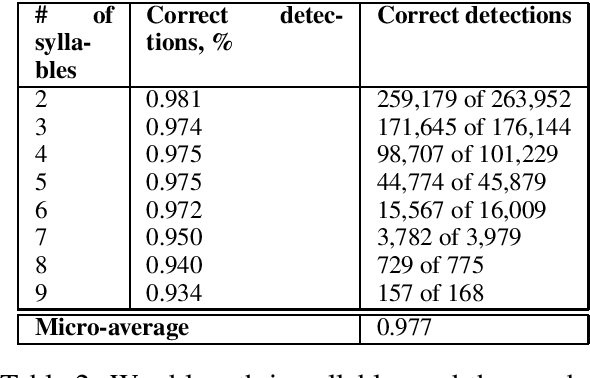
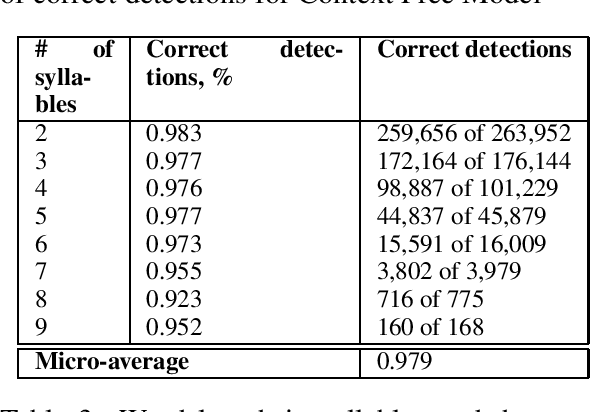
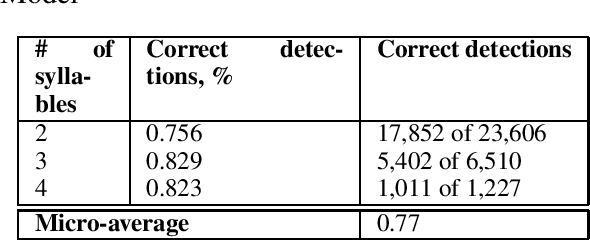
In this study we address the problem of automated word stress detection in Russian using character level models and no part-speech-taggers. We use a simple bidirectional RNN with LSTM nodes and achieve the accuracy of 90% or higher. We experiment with two training datasets and show that using the data from an annotated corpus is much more efficient than using a dictionary, since it allows us to take into account word frequencies and the morphological context of the word.
* SCLeM 2017
AGRR-2019: A Corpus for Gapping Resolution in Russian
Jun 10, 2019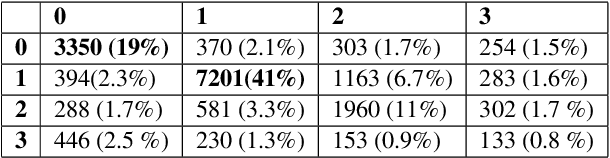
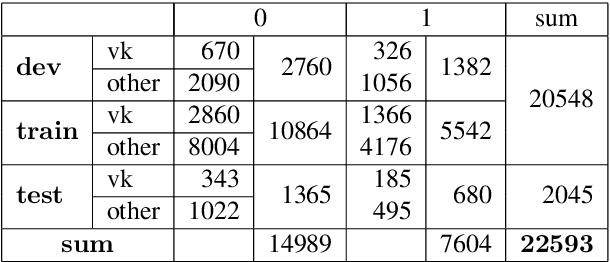
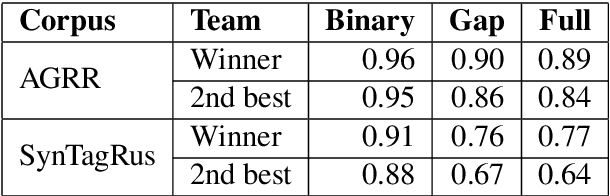
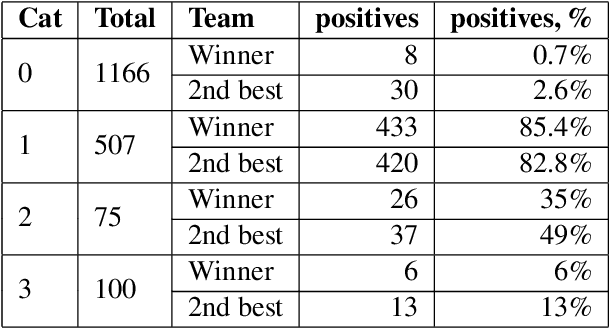
This paper provides a comprehensive overview of the gapping dataset for Russian that consists of 7.5k sentences with gapping (as well as 15k relevant negative sentences) and comprises data from various genres: news, fiction, social media and technical texts. The dataset was prepared for the Automatic Gapping Resolution Shared Task for Russian (AGRR-2019) - a competition aimed at stimulating the development of NLP tools and methods for processing of ellipsis. In this paper, we pay special attention to the gapping resolution methods that were introduced within the shared task as well as an alternative test set that illustrates that our corpus is a diverse and representative subset of Russian language gapping sufficient for effective utilization of machine learning techniques.
Char-RNN for Word Stress Detection in East Slavic Languages
Jun 10, 2019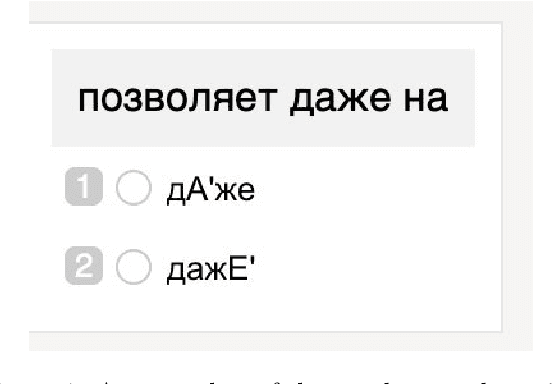

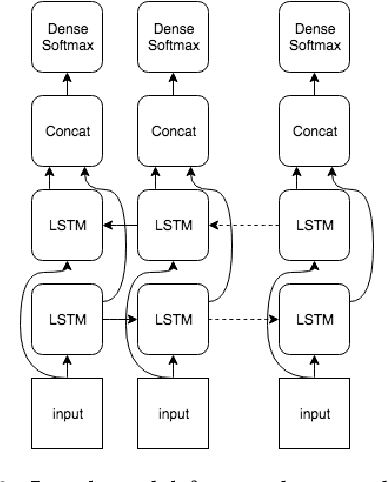
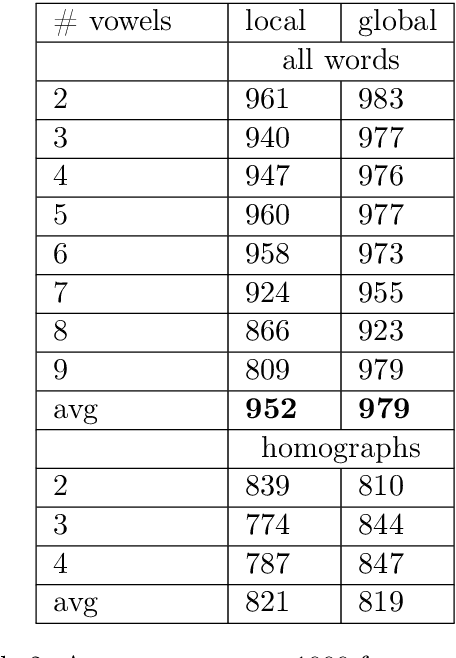
We explore how well a sequence labeling approach, namely, recurrent neural network, is suited for the task of resource-poor and POS tagging free word stress detection in the Russian, Ukranian, Belarusian languages. We present new datasets, annotated with the word stress, for the three languages and compare several RNN models trained on three languages and explore possible applications of the transfer learning for the task. We show that it is possible to train a model in a cross-lingual setting and that using additional languages improves the quality of the results.
* Proceedings of the Sixth Workshop on NLP for Similar Languages, Varieties and Dialects at NAACL-2019