 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperEmbed: Tradeoffs Between Resources and Performance in NLP Tasks with Hyperdimensional Computing enabled Embedding of n-gram Statistics
Mar 03, 2020
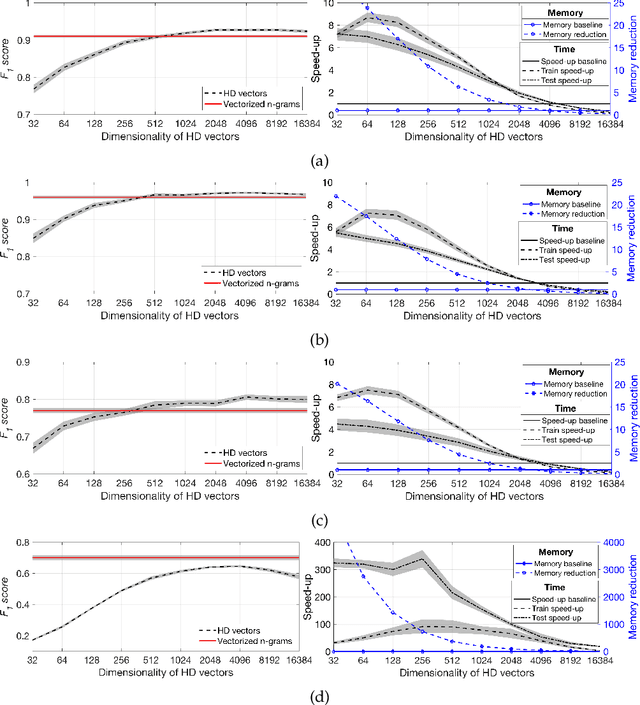
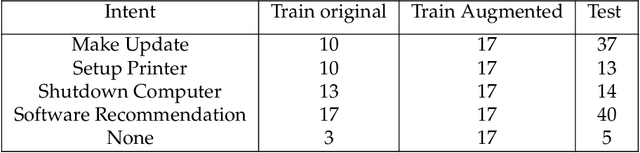
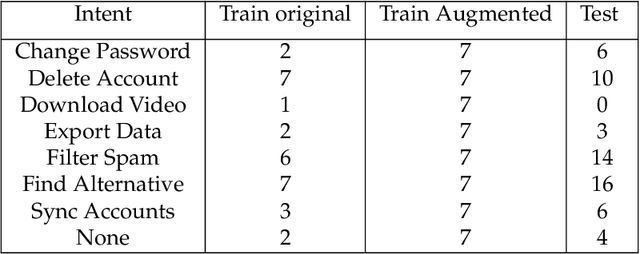
Recent advances in Deep Learning have led to a significant performance increase on several NLP tasks, however, the models become more and more computationally demanding. Therefore, this paper tackles the domain of computationally efficient algorithms for NLP tasks. In particular, it investigates distributed representations of n-gram statistics of texts. The representations are formed using hyperdimensional computing enabled embedding. These representations then serve as features, which are used as input to standard classifiers. We investigate the applicability of the embedding on one large and three small standard datasets for classification tasks using nine classifiers. The embedding achieved on par F1 scores while decreasing the time and memory requirements by several times compared to the conventional n-gram statistics, e.g., for one of the classifiers on a small dataset, the memory reduction was 6.18 times; while train and test speed-ups were 4.62 and 3.84 times, respectively. For many classifiers on the large dataset, the memory reduction was about 100 times and train and test speed-ups were over 100 times. More importantly, the usage of distributed representations formed via hyperdimensional computing allows dissecting the strict dependency between the dimensionality of the representation and the parameters of n-gram statistics, thus, opening a room for tradeoffs.
Improving Image Autoencoder Embeddings with Perceptual Loss
Jan 10, 2020

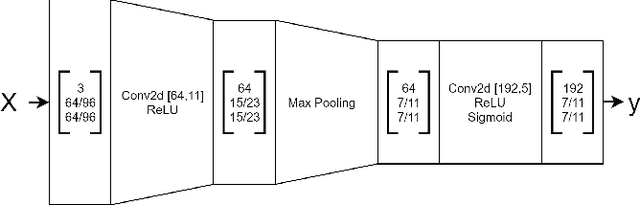
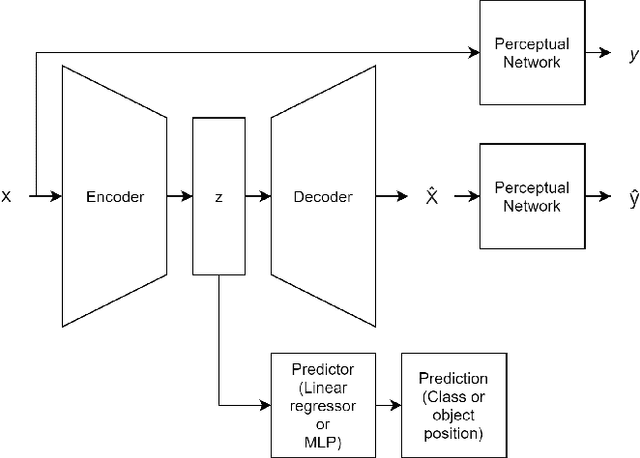
Autoencoders are commonly trained using element-wise loss. However, element-wise loss disregards high-level structures in the image which can lead to embeddings that disregard them as well. A recent improvement to autoencoders that help alleviate this problem is the use of perceptual loss. This work investigate perceptual loss from the perspective of encoder embeddings themselves. Autoencoders are trained to embed images from three different computer vision datasets using perceptual loss based on a pretrained model as well as pixel-wise loss. A host of different predictors are trained to perform object positioning and classification on the datasets given the embedded images as input. The two kinds of losses are evaluated by comparing how the predictors performed with embeddings from the differently trained autoencoders. The results show that, in the image domain, the embeddings generated by autoencoders trained with perceptual loss enable more accurate predictions than those trained with element-wise loss. Furthermore, the results show that, on the task of object-positioning of a small-scale feature, perceptual loss can improve the results by a factor 10. The experimental setup is available online: https://github.com/guspih/Perceptual-Autoencoders
Trainable Spectrally Initializable Matrix Transformations in Convolutional Neural Networks
Nov 13, 2019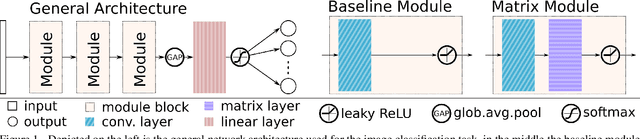
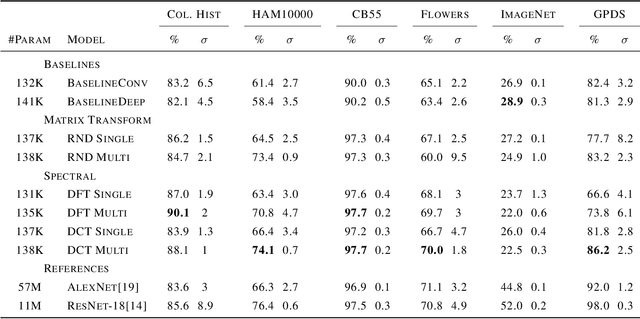
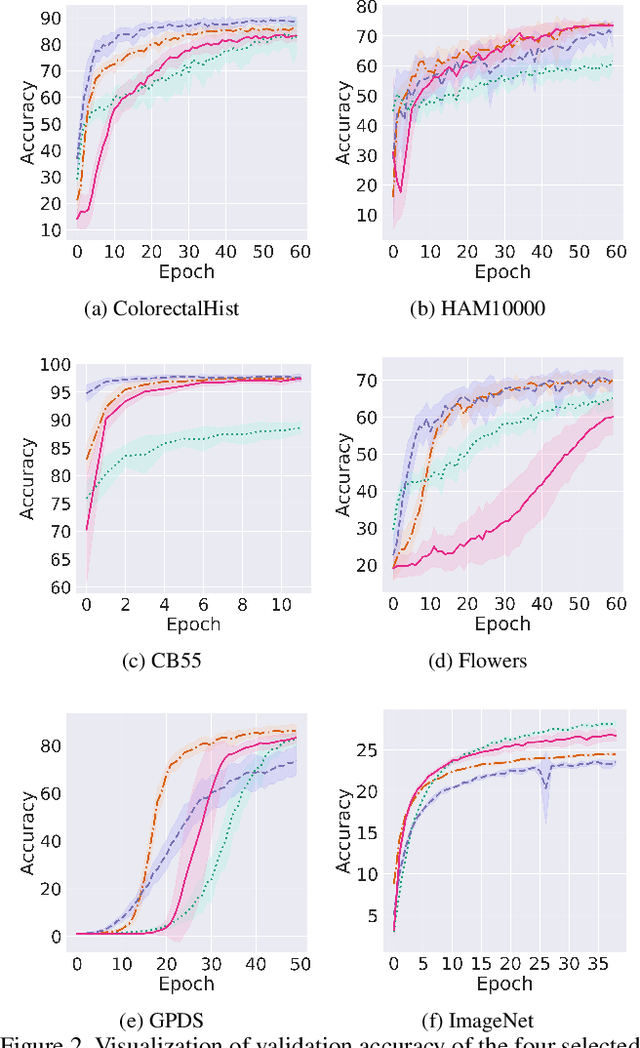
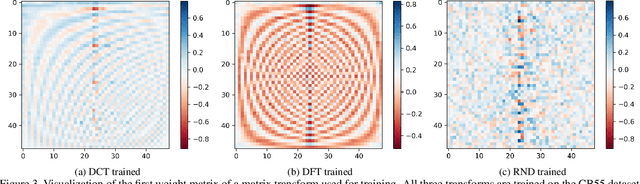
In this work, we investigate the application of trainable and spectrally initializable matrix transformations on the feature maps produced by convolution operations. While previous literature has already demonstrated the possibility of adding static spectral transformations as feature processors, our focus is on more general trainable transforms. We study the transforms in various architectural configurations on four datasets of different nature: from medical (ColorectalHist, HAM10000) and natural (Flowers, ImageNet) images to historical documents (CB55) and handwriting recognition (GPDS). With rigorous experiments that control for the number of parameters and randomness, we show that networks utilizing the introduced matrix transformations outperform vanilla neural networks. The observed accuracy increases by an average of 2.2 across all datasets. In addition, we show that the benefit of spectral initialization leads to significantly faster convergence, as opposed to randomly initialized matrix transformations. The transformations are implemented as auto-differentiable PyTorch modules that can be incorporated into any neural network architecture. The entire code base is open-source.
Labeling, Cutting, Grouping: an Efficient Text Line Segmentation Method for Medieval Manuscripts
Jul 01, 2019



This paper introduces a new way for text-line extraction by integrating deep-learning based pre-classification and state-of-the-art segmentation methods. Text-line extraction in complex handwritten documents poses a significant challenge, even to the most modern computer vision algorithms. Historical manuscripts are a particularly hard class of documents as they present several forms of noise, such as degradation, bleed-through, interlinear glosses, and elaborated scripts. In this work, we propose a novel method which uses semantic segmentation at pixel level as intermediate task, followed by a text-line extraction step. We measured the performance of our method on a recent dataset of challenging medieval manuscripts and surpassed state-of-the-art results by reducing the error by 80.7%. Furthermore, we demonstrate the effectiveness of our approach on various other datasets written in different scripts. Hence, our contribution is two-fold. First, we demonstrate that semantic pixel segmentation can be used as strong denoising pre-processing step before performing text line extraction. Second, we introduce a novel, simple and robust algorithm that leverages the high-quality semantic segmentation to achieve a text-line extraction performance of 99.42% line IU on a challenging dataset.
Improving Reproducible Deep Learning Workflows with DeepDIVA
Jun 11, 2019
The field of deep learning is experiencing a trend towards producing reproducible research. Nevertheless, it is still often a frustrating experience to reproduce scientific results. This is especially true in the machine learning community, where it is considered acceptable to have black boxes in your experiments. We present DeepDIVA, a framework designed to facilitate easy experimentation and their reproduction. This framework allows researchers to share their experiments with others, while providing functionality that allows for easy experimentation, such as: boilerplate code, experiment management, hyper-parameter optimization, verification of data integrity and visualization of data and results. Additionally, the code of DeepDIVA is well-documented and supported by several tutorials that allow a new user to quickly familiarize themselves with the framework.
Survey of Artificial Intelligence for Card Games and Its Application to the Swiss Game Jass
Jun 11, 2019In the last decades we have witnessed the success of applications of Artificial Intelligence to playing games. In this work we address the challenging field of games with hidden information and card games in particular. Jass is a very popular card game in Switzerland and is closely connected with Swiss culture. To the best of our knowledge, performances of Artificial Intelligence agents in the game of Jass do not outperform top players yet. Our contribution to the community is two-fold. First, we provide an overview of the current state-of-the-art of Artificial Intelligence methods for card games in general. Second, we discuss their application to the use-case of the Swiss card game Jass. This paper aims to be an entry point for both seasoned researchers and new practitioners who want to join in the Jass challenge.
A Comprehensive Study of ImageNet Pre-Training for Historical Document Image Analysis
May 22, 2019


Automatic analysis of scanned historical documents comprises a wide range of image analysis tasks, which are often challenging for machine learning due to a lack of human-annotated learning samples. With the advent of deep neural networks, a promising way to cope with the lack of training data is to pre-train models on images from a different domain and then fine-tune them on historical documents. In the current research, a typical example of such cross-domain transfer learning is the use of neural networks that have been pre-trained on the ImageNet database for object recognition. It remains a mostly open question whether or not this pre-training helps to analyse historical documents, which have fundamentally different image properties when compared with ImageNet. In this paper, we present a comprehensive empirical survey on the effect of ImageNet pre-training for diverse historical document analysis tasks, including character recognition, style classification, manuscript dating, semantic segmentation, and content-based retrieval. While we obtain mixed results for semantic segmentation at pixel-level, we observe a clear trend across different network architectures that ImageNet pre-training has a positive effect on classification as well as content-based retrieval.
ICDAR 2019 Historical Document Reading Challenge on Large Structured Chinese Family Records
Mar 18, 2019We propose a Historical Document Reading Challenge on Large Chinese Structured Family Records, in short ICDAR2019 HDRC CHINESE. The objective of the proposed competition is to recognize and analyze the layout, and finally detect and recognize the textlines and characters of the large historical document collection containing more than 20 000 pages kindly provided by FamilySearch.
Using Deep Object Features for Image Descriptions
Feb 25, 2019
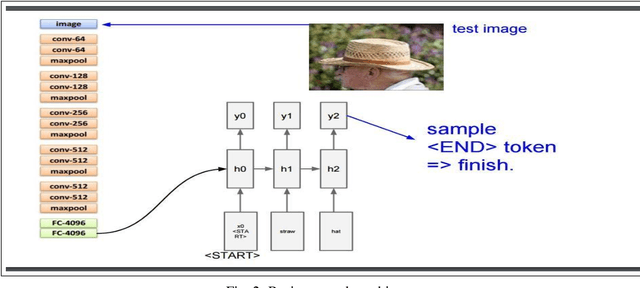
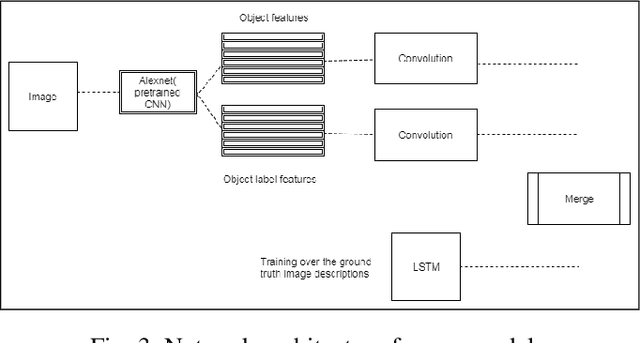

Inspired by recent advances in leveraging multiple modalities in machine translation, we introduce an encoder-decoder pipeline that uses (1) specific objects within an image and their object labels, (2) a language model for decoding joint embedding of object features and the object labels. Our pipeline merges prior detected objects from the image and their object labels and then learns the sequences of captions describing the particular image. The decoder model learns to extract descriptions for the image from scratch by decoding the joint representation of the object visual features and their object classes conditioned by the encoder component. The idea of the model is to concentrate only on the specific objects of the image and their labels for generating descriptions of the image rather than visual feature of the entire image. The model needs to be calibrated more by adjusting the parameters and settings to result in better accuracy and performance.
A Comprehensive guide to Bayesian Convolutional Neural Network with Variational Inference
Jan 08, 2019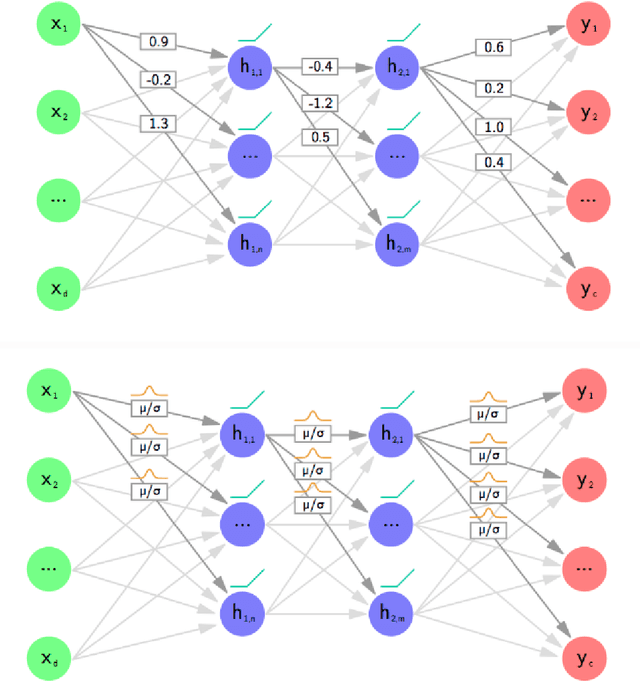
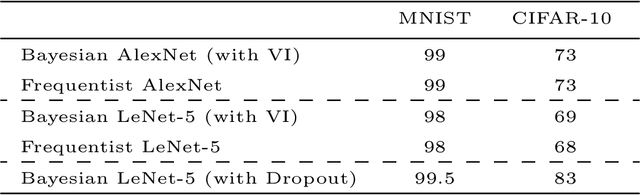
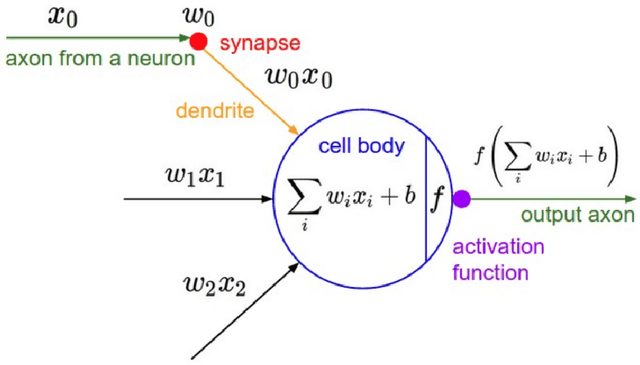

Artificial Neural Networks are connectionist systems that perform a given task by learning on examples without having prior knowledge about the task. This is done by finding an optimal point estimate for the weights in every node. Generally, the network using point estimates as weights perform well with large datasets, but they fail to express uncertainty in regions with little or no data, leading to overconfident decisions. In this paper, Bayesian Convolutional Neural Network (BayesCNN) using Variational Inference is proposed, that introduces probability distribution over the weights. Furthermore, the proposed BayesCNN architecture is applied to tasks like Image Classification, Image Super-Resolution and Generative Adversarial Networks. The results are compared to point-estimates based architectures on MNIST, CIFAR-10 and CIFAR-100 datasets for Image CLassification task, on BSD300 dataset for Image Super Resolution task and on CIFAR10 dataset again for Generative Adversarial Network task. BayesCNN is based on Bayes by Backprop which derives a variational approximation to the true posterior. We, therefore, introduce the idea of applying two convolutional operations, one for the mean and one for the variance. Our proposed method not only achieves performances equivalent to frequentist inference in identical architectures but also incorporate a measurement for uncertainties and regularisation. It further eliminates the use of dropout in the model. Moreover, we predict how certain the model prediction is based on the epistemic and aleatoric uncertainties and empirically show how the uncertainty can decrease, allowing the decisions made by the network to become more deterministic as the training accuracy increases. Finally, we propose ways to prune the Bayesian architecture and to make it more computational and time effective.