 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2021 Task 1: Lexical Complexity Prediction
Jun 01, 2021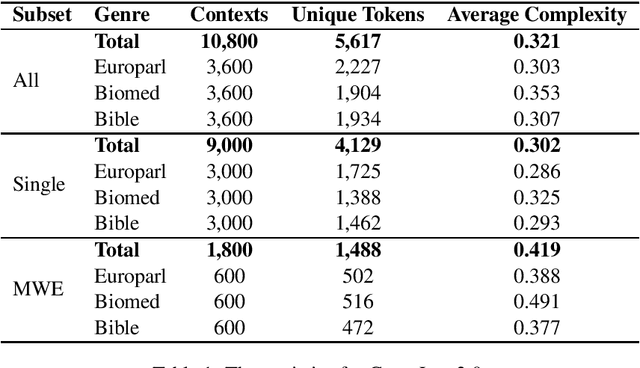
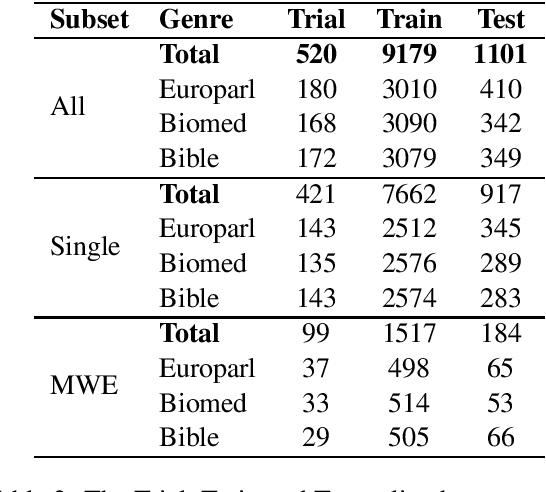
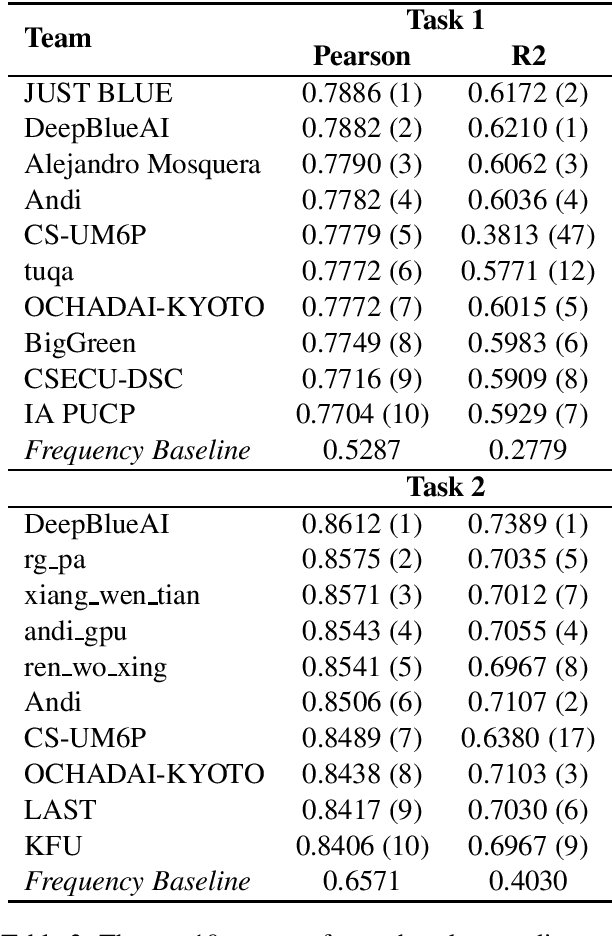
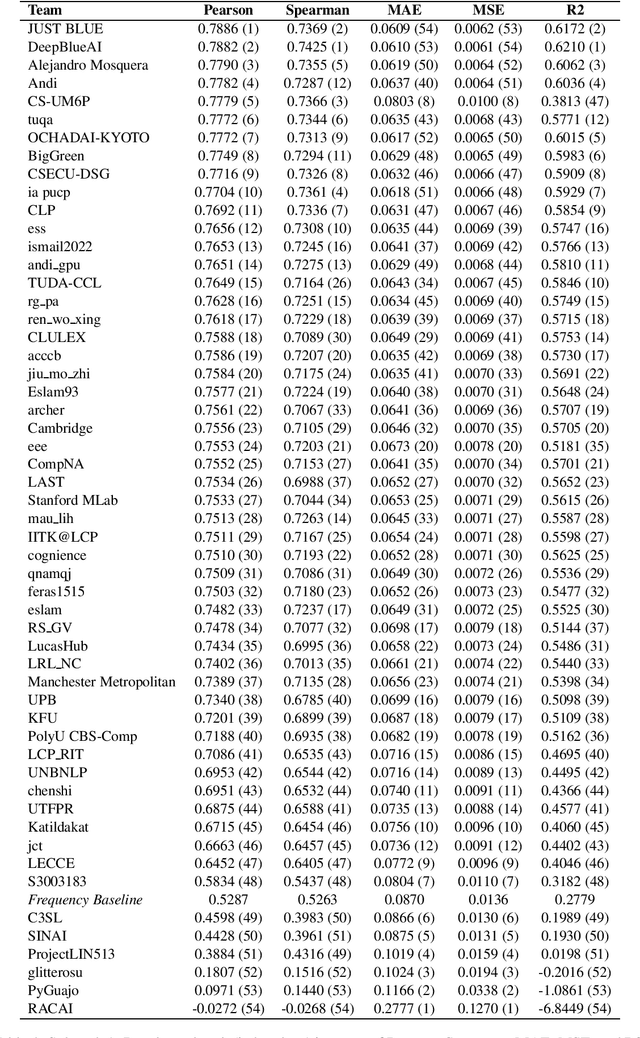
This paper presents the results and main findings of SemEval-2021 Task 1 - Lexical Complexity Prediction. We provided participants with an augmented version of the CompLex Corpus (Shardlow et al 2020). CompLex is an English multi-domain corpus in which words and multi-word expressions (MWEs) were annotated with respect to their complexity using a five point Likert scale. SemEval-2021 Task 1 featured two Sub-tasks: Sub-task 1 focused on single words and Sub-task 2 focused on MWEs. The competition attracted 198 teams in total, of which 54 teams submitted official runs on the test data to Sub-task 1 and 37 to Sub-task 2.
An Exploratory Analysis of the Relation Between Offensive Language and Mental Health
May 31, 2021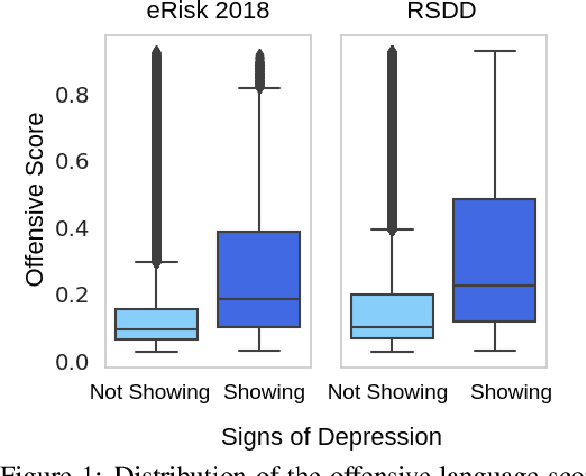
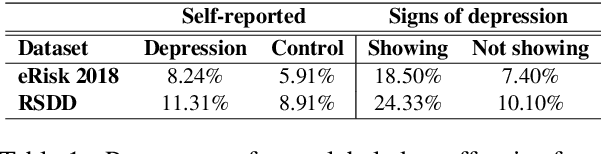
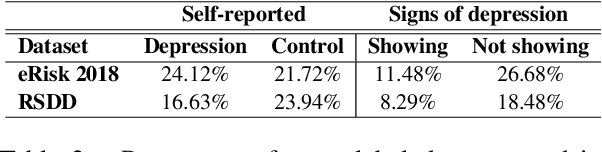
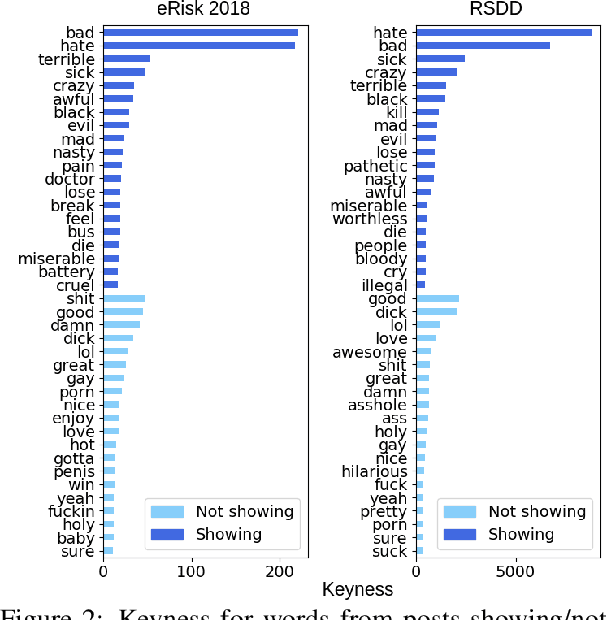
In this paper, we analyze the interplay between the use of offensive language and mental health. We acquired publicly available datasets created for offensive language identification and depression detection and we train computational models to compare the use of offensive language in social media posts written by groups of individuals with and without self-reported depression diagnosis. We also look at samples written by groups of individuals whose posts show signs of depression according to recent related studies. Our analysis indicates that offensive language is more frequently used in the samples written by individuals with self-reported depression as well as individuals showing signs of depression. The results discussed here open new avenues in research in politeness/offensiveness and mental health.
Multilingual Offensive Language Identification for Low-resource Languages
May 20, 2021
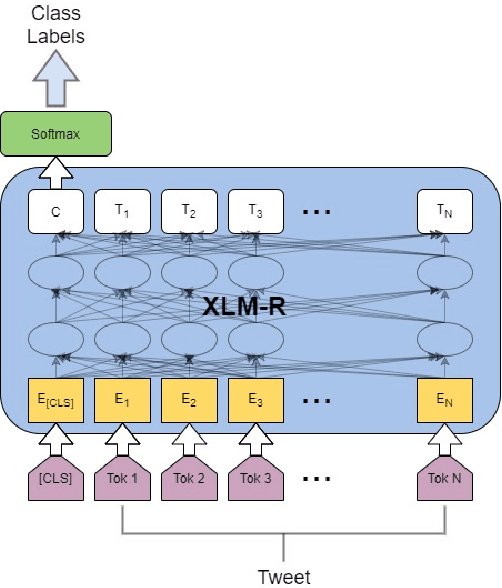
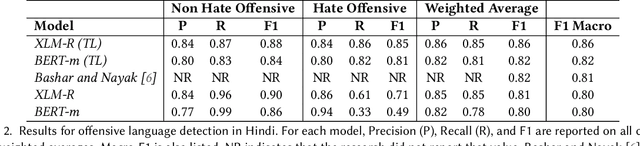
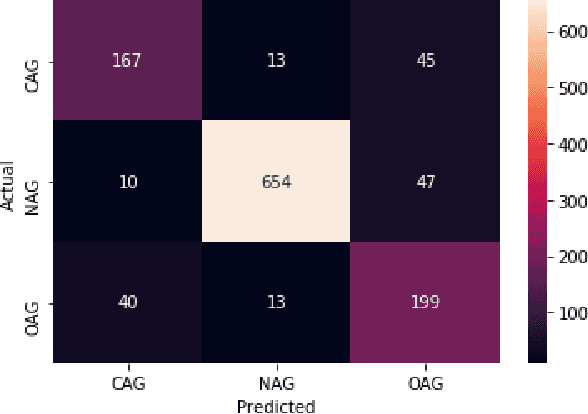
Offensive content is pervasive in social media and a reason for concern to companies and government organizations. Several studies have been recently published investigating methods to detect the various forms of such content (e.g. hate speech, cyberbullying, and cyberaggression). The clear majority of these studies deal with English partially because most annotated datasets available contain English data. In this paper, we take advantage of available English datasets by applying cross-lingual contextual word embeddings and transfer learning to make predictions in low-resource languages. We project predictions on comparable data in Arabic, Bengali, Danish, Greek, Hindi, Spanish, and Turkish. We report results of 0.8415 F1 macro for Bengali in TRAC-2 shared task, 0.8532 F1 macro for Danish and 0.8701 F1 macro for Greek in OffensEval 2020, 0.8568 F1 macro for Hindi in HASOC 2019 shared task and 0.7513 F1 macro for Spanish in in SemEval-2019 Task 5 (HatEval) showing that our approach compares favourably to the best systems submitted to recent shared tasks on these three languages. Additionally, we report competitive performance on Arabic, and Turkish using the training and development sets of OffensEval 2020 shared task. The results for all languages confirm the robustness of cross-lingual contextual embeddings and transfer learning for this task.
LCP-RIT at SemEval-2021 Task 1: Exploring Linguistic Features for Lexical Complexity Prediction
May 18, 2021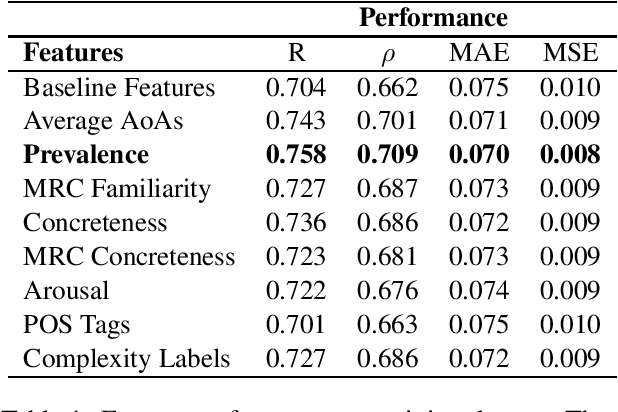
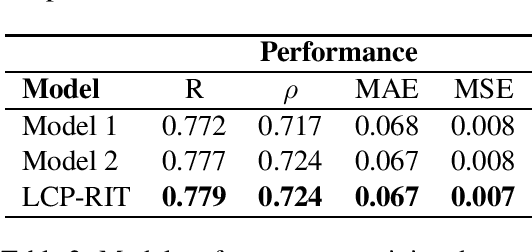
This paper describes team LCP-RIT's submission to the SemEval-2021 Task 1: Lexical Complexity Prediction (LCP). The task organizers provided participants with an augmented version of CompLex (Shardlow et al., 2020), an English multi-domain dataset in which words in context were annotated with respect to their complexity using a five point Likert scale. Our system uses logistic regression and a wide range of linguistic features (e.g. psycholinguistic features, n-grams, word frequency, POS tags) to predict the complexity of single words in this dataset. We analyze the impact of different linguistic features in the classification performance and we evaluate the results in terms of mean absolute error, mean squared error, Pearson correlation, and Spearman correlation.
WLV-RIT at SemEval-2021 Task 5: A Neural Transformer Framework for Detecting Toxic Spans
Apr 15, 2021
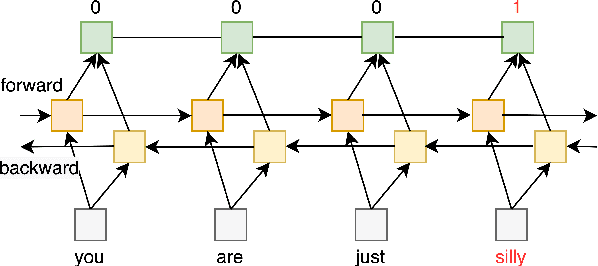
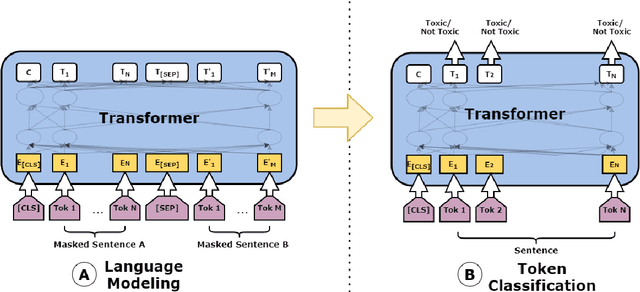
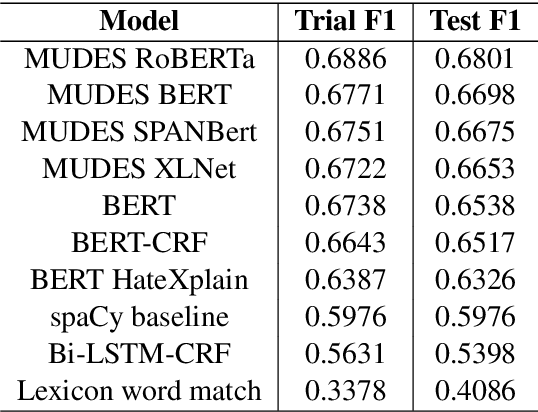
In recent years, the widespread use of social media has led to an increase in the generation of toxic and offensive content on online platforms. In response, social media platforms have worked on developing automatic detection methods and employing human moderators to cope with this deluge of offensive content. While various state-of-the-art statistical models have been applied to detect toxic posts, there are only a few studies that focus on detecting the words or expressions that make a post offensive. This motivates the organization of the SemEval-2021 Task 5: Toxic Spans Detection competition, which has provided participants with a dataset containing toxic spans annotation in English posts. In this paper, we present the WLV-RIT entry for the SemEval-2021 Task 5. Our best performing neural transformer model achieves an $0.68$ F1-Score. Furthermore, we develop an open-source framework for multilingual detection of offensive spans, i.e., MUDES, based on neural transformers that detect toxic spans in texts.
Domain-specific MT for Low-resource Languages: The case of Bambara-French
Mar 31, 2021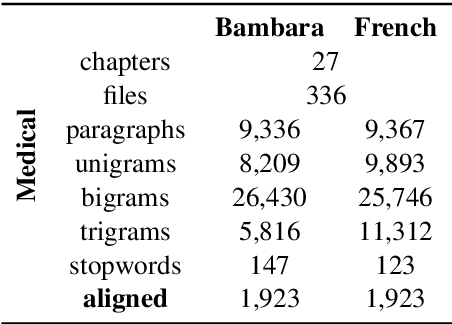
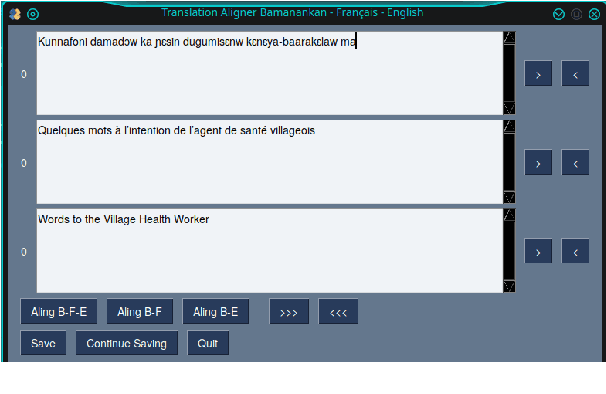
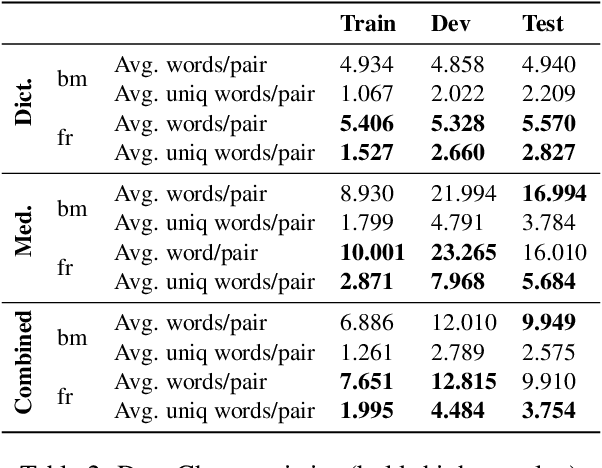
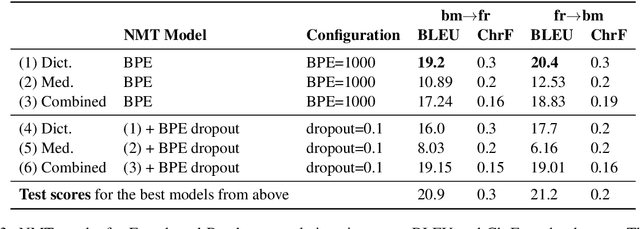
Translating to and from low-resource languages is a challenge for machine translation (MT) systems due to a lack of parallel data. In this paper we address the issue of domain-specific MT for Bambara, an under-resourced Mande language spoken in Mali. We present the first domain-specific parallel dataset for MT of Bambara into and from French. We discuss challenges in working with small quantities of domain-specific data for a low-resource language and we present the results of machine learning experiments on this data.
Comparing Approaches to Dravidian Language Identification
Mar 09, 2021

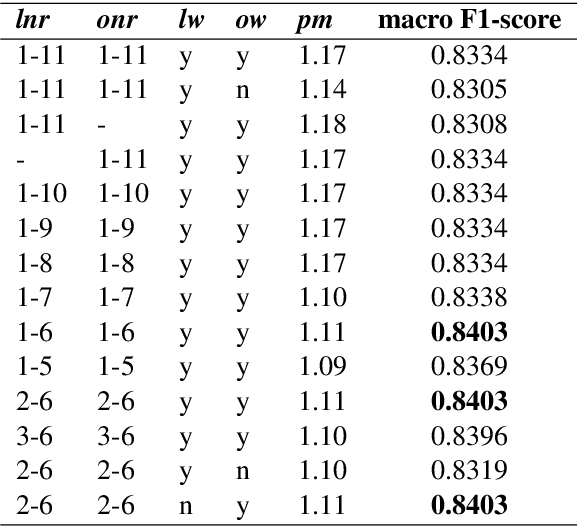
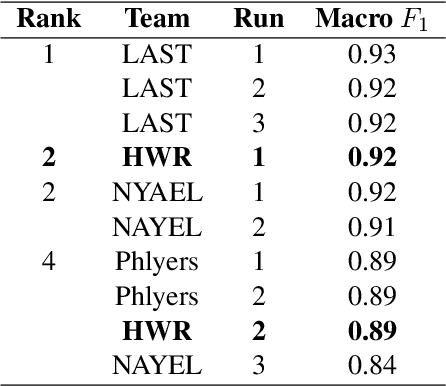
This paper describes the submissions by team HWR to the Dravidian Language Identification (DLI) shared task organized at VarDial 2021 workshop. The DLI training set includes 16,674 YouTube comments written in Roman script containing code-mixed text with English and one of the three South Dravidian languages: Kannada, Malayalam, and Tamil. We submitted results generated using two models, a Naive Bayes classifier with adaptive language models, which has shown to obtain competitive performance in many language and dialect identification tasks, and a transformer-based model which is widely regarded as the state-of-the-art in a number of NLP tasks. Our first submission was sent in the closed submission track using only the training set provided by the shared task organisers, whereas the second submission is considered to be open as it used a pretrained model trained with external data. Our team attained shared second position in the shared task with the submission based on Naive Bayes. Our results reinforce the idea that deep learning methods are not as competitive in language identification related tasks as they are in many other text classification tasks.
MUDES: Multilingual Detection of Offensive Spans
Feb 18, 2021
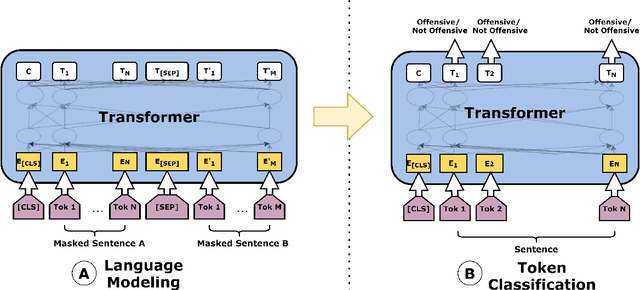
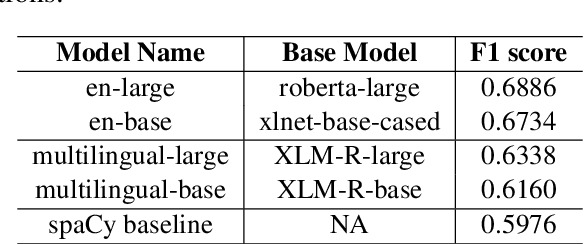
The interest in offensive content identification in social media has grown substantially in recent years. Previous work has dealt mostly with post level annotations. However, identifying offensive spans is useful in many ways. To help coping with this important challenge, we present MUDES, a multilingual system to detect offensive spans in texts. MUDES features pre-trained models, a Python API for developers, and a user-friendly web-based interface. A detailed description of MUDES' components is presented in this paper.
Predicting Lexical Complexity in English Texts
Feb 17, 2021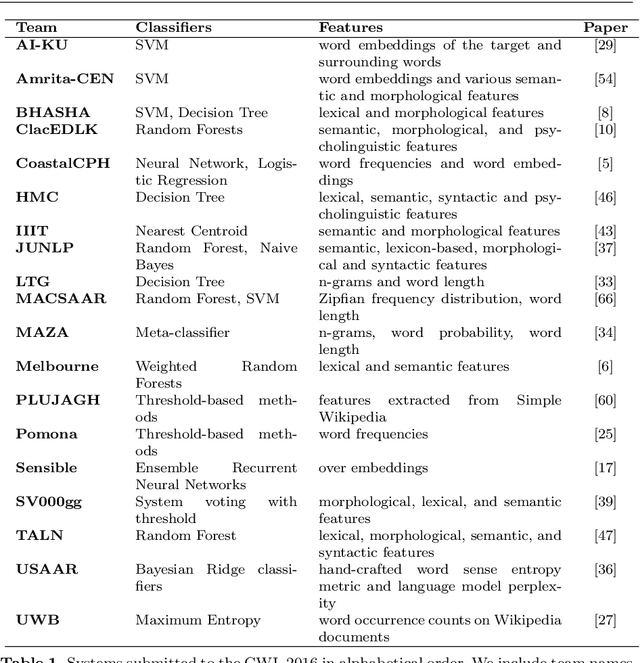
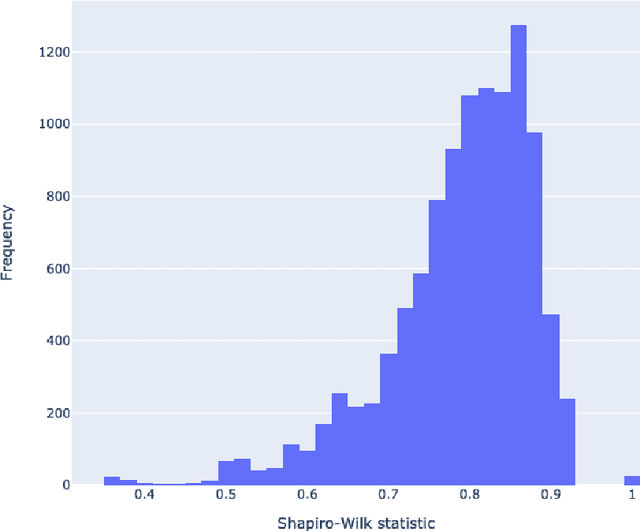
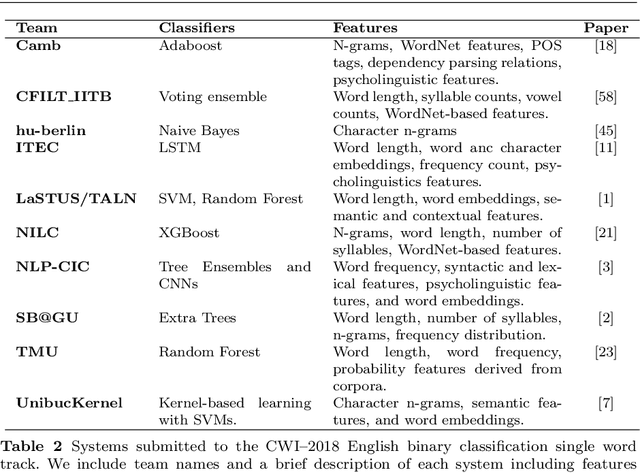
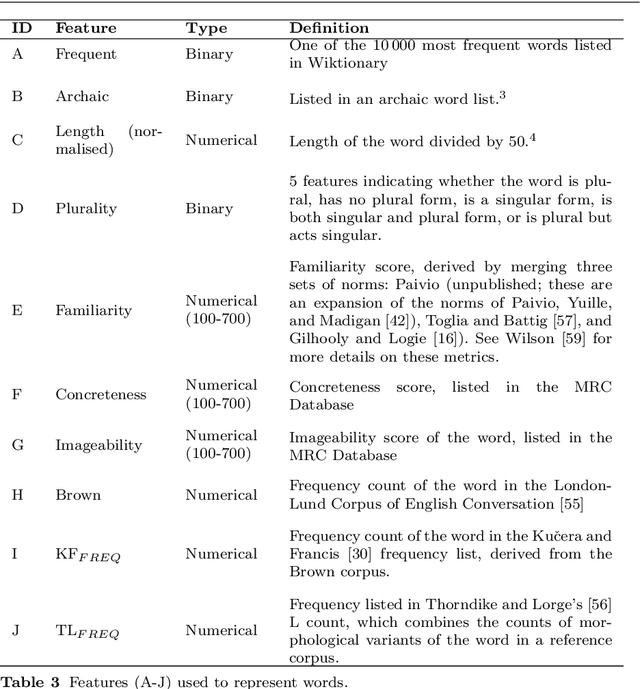
The first step in most text simplification is to predict which words are considered complex for a given target population before carrying out lexical substitution. This task is commonly referred to as Complex Word Identification (CWI) and it is often modelled as a supervised classification problem. For training such systems, annotated datasets in which words and sometimes multi-word expressions are labelled regarding complexity are required. In this paper we analyze previous work carried out in this task and investigate the properties of complex word identification datasets for English.
Neural Machine Translation for Extremely Low-Resource African Languages: A Case Study on Bambara
Nov 10, 2020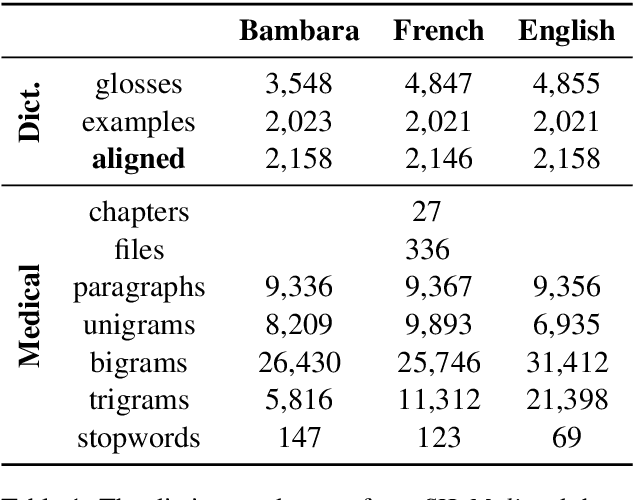
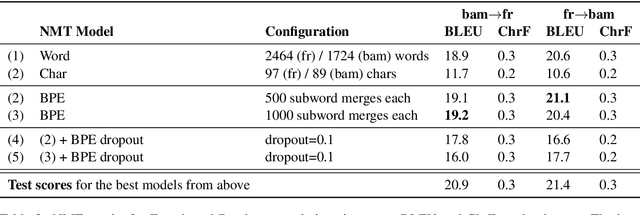
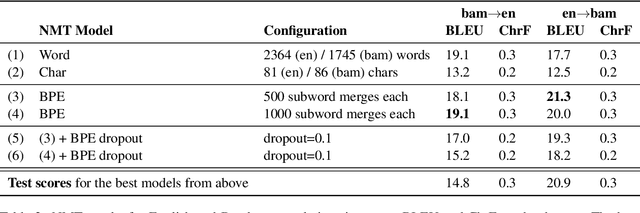
Low-resource languages present unique challenges to (neural) machine translation. We discuss the case of Bambara, a Mande language for which training data is scarce and requires significant amounts of pre-processing. More than the linguistic situation of Bambara itself, the socio-cultural context within which Bambara speakers live poses challenges for automated processing of this language. In this paper, we present the first parallel data set for machine translation of Bambara into and from English and French and the first benchmark results on machine translation to and from Bambara. We discuss challenges in working with low-resource languages and propose strategies to cope with data scarcity in low-resource machine translation (MT).