 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn handwriting pressure normalization for interoperability of different acquisition stylus
Mar 28, 2022



In this paper, we present a pressure characterization and normalization procedure for online handwritten acquisition. Normalization process has been tested in biometric recognition experiments (identification and verification) using online signature database MCYT, which consists of the signatures from 330 users. The goal is to analyze the real mismatch scenarios where users are enrolled with one stylus and then, later on, they produce some testing samples using a different stylus model with different pressure response. Experimental results show: 1) a saturation behavior in pressure signal 2) different dynamic ranges in the different stylus studied 3) improved biometric recognition accuracy by means of pressure signal normalization as well as a performance degradation in mismatched conditions 4) interoperability between different stylus can be obtained by means of pressure normalization. Normalization produces an improvement in signature identification rates higher than 7% (absolute value) when compared with mismatched scenarios.
* 11 pages, published in IEEE Access, vol. 9, pp. 18443-18453, 2021
Wide band sub-band speech coding using nonlinear prediction
Mar 24, 2022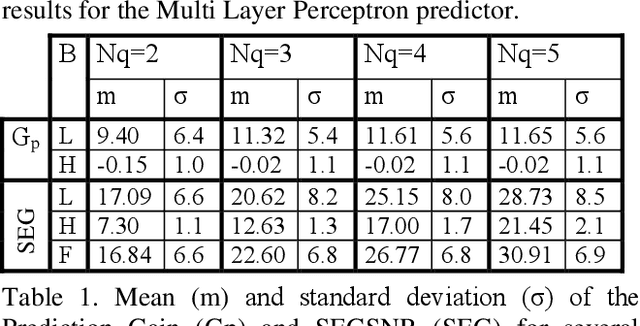
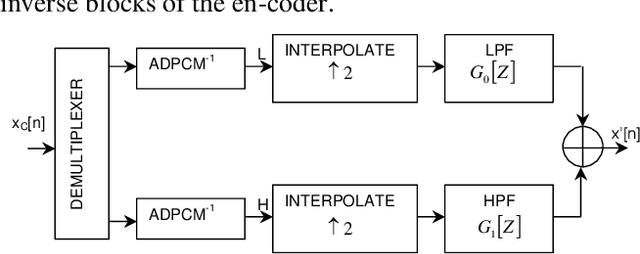
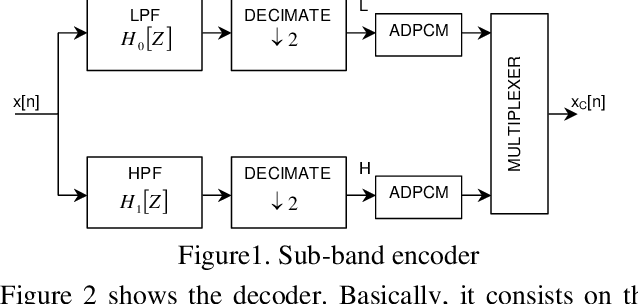
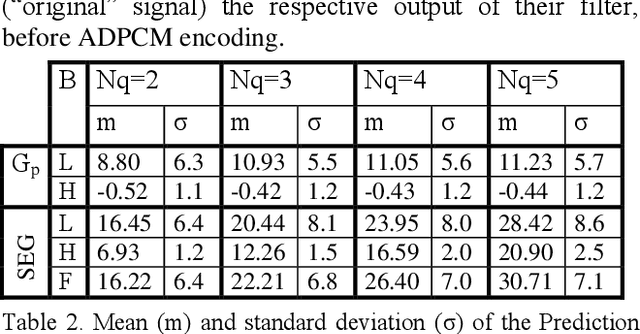
We compare a wide band sub-band speech coder using ADPCM schemes with linear prediction against the same scheme with nonlinear prediction based on multi-layer perceptrons. Exhaustive results are presented in each band, and the full signal. Our proposed scheme with non-linear neural net prediction outperforms the linear scheme up to 2 dB in SEGSNR. In addition, we propose a simple method based on a non-linearity in order to obtain a synthetic wide band signal from a narrow band signal.
* 4 pages, published in 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003. Proceedings. (ICASSP '03) Hong Kong, China
A combination between VQ and covariance matrices for speaker recognition
Mar 23, 2022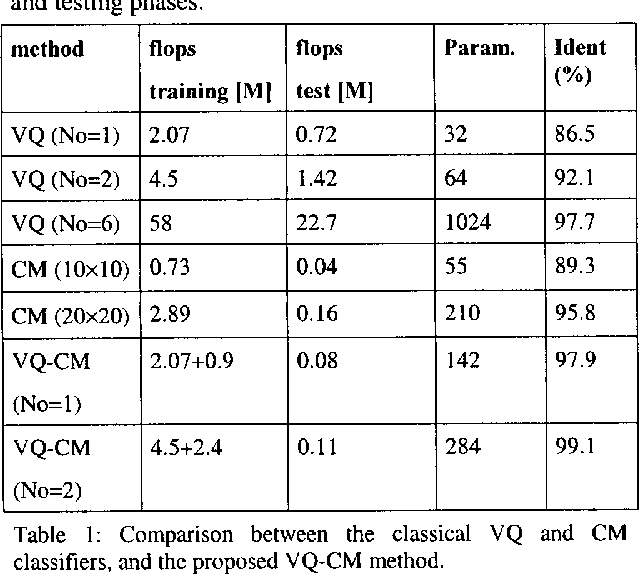
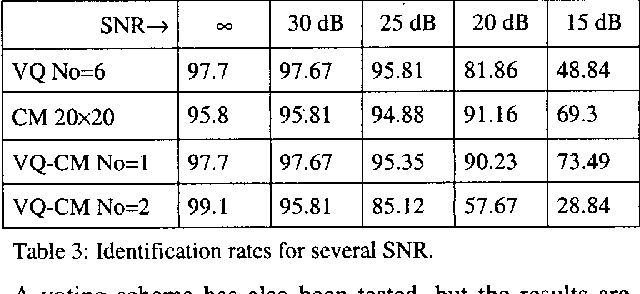
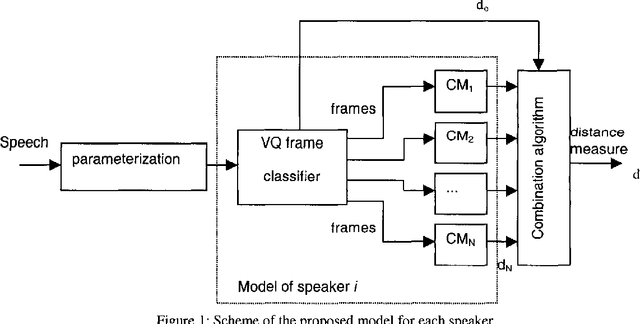

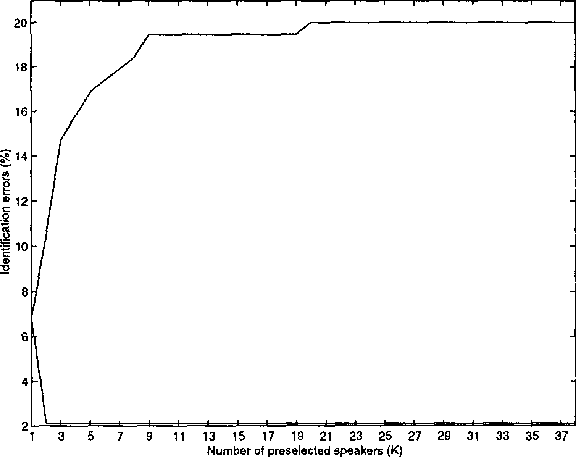
This paper presents a new algorithm for speaker recognition based on the combination between the classical Vector Quantization (VQ) and Covariance Matrix (CM) methods. The combined VQ-CM method improves the identification rates of each method alone, with comparable computational burden. It offers a straightforward procedure to obtain a model similar to GMM with full covariance matrices. Experimental results also show that it is more robust against noise than VQ or CM alone.
* 5 pages, published in 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No.01CH37221), Salt Lake City, UT, USA
Fast on-line signature recognition based on VQ with time modeling
Mar 23, 2022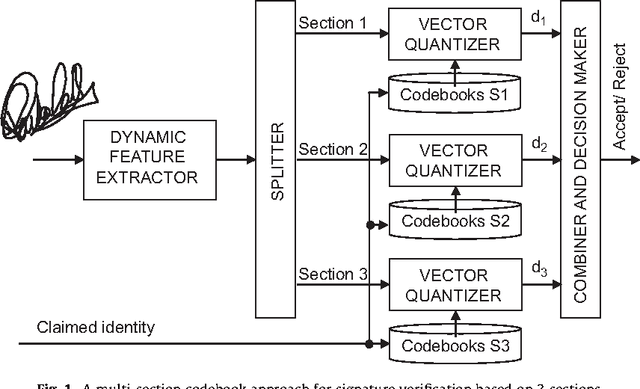
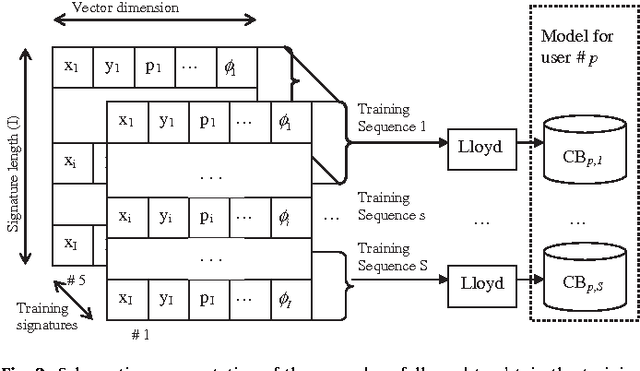

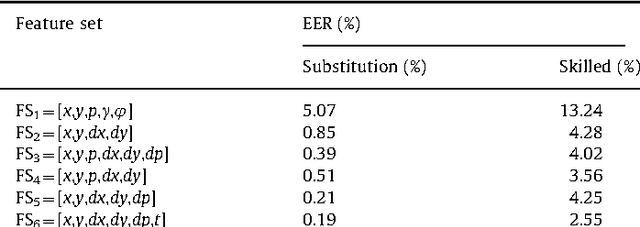
This paper proposes a multi-section vector quantization approach for on-line signature recognition. We have used the MCYT database, which consists of 330 users and 25 skilled forgeries per person performed by 5 different impostors. This database is larger than those typically used in the literature. Nevertheless, we also provide results from the SVC database. Our proposed system outperforms the winner of SVC with a reduced computational requirement, which is around 47 times lower than DTW. In addition, our system improves the database storage requirements due to vector compression, and is more privacy-friendly as it is not possible to recover the original signature using the codebooks. Experimental results with MCYT provide a 99.76% identification rate and 2.46% EER (skilled forgeries and individual threshold). Experimental results with SVC are 100% of identification rate and 0% (individual threshold) and 0.31% (general threshold) when using a two-section VQ approach.
* 23 pages, published in Engineering Applications of Artificial Intelligence, Volume 24, Issue 2, 2011, Pages 368-377, ISSN 0952-1976
Speaker recognition with a MLP classifier and LPCC codebook
Mar 22, 2022
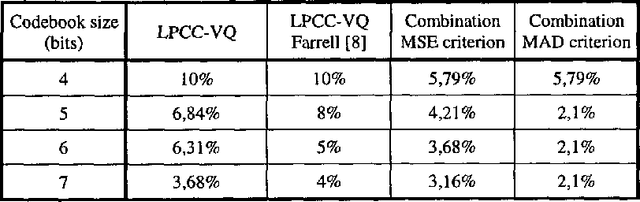
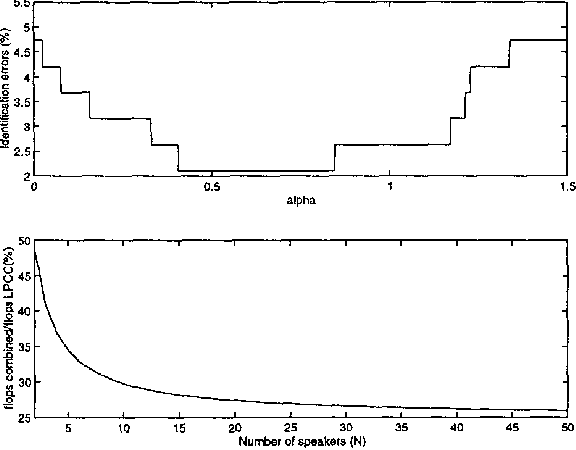
This paper improves the speaker recognition rates of a MLP classifier and LPCC codebook alone, using a linear combination between both methods. In simulations we have obtained an improvement of 4.7% over a LPCC codebook of 32 vectors and 1.5% for a codebook of 128 vectors (error rate drops from 3.68% to 2.1%). Also we propose an efficient algorithm that reduces the computational complexity of the LPCC-VQ system by a factor of 4.
* 4 pages, published in 1999 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings. ICASSP99 (Cat. No.99CH36258) Phoenix, AZ, USA
Nonlinear prediction with neural nets in ADPCM
Mar 22, 2022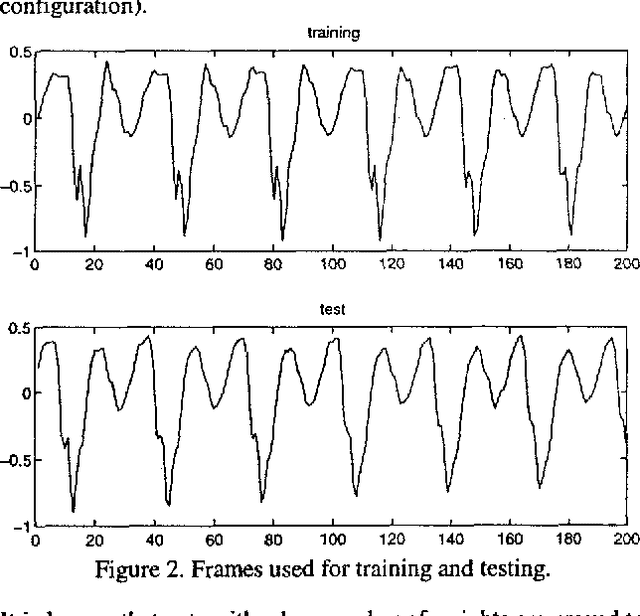
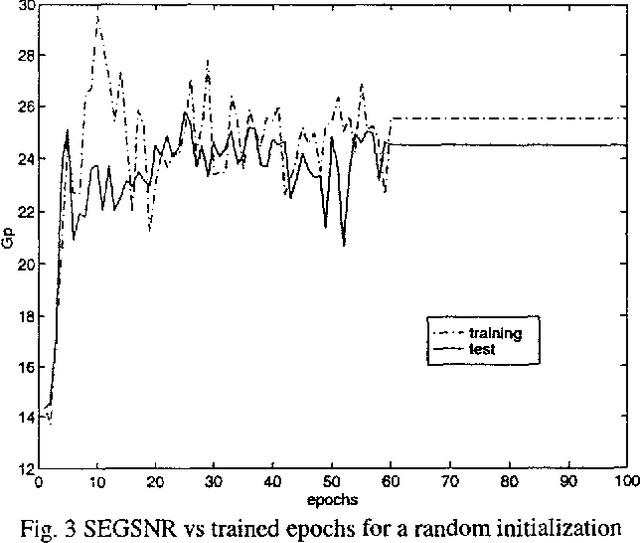
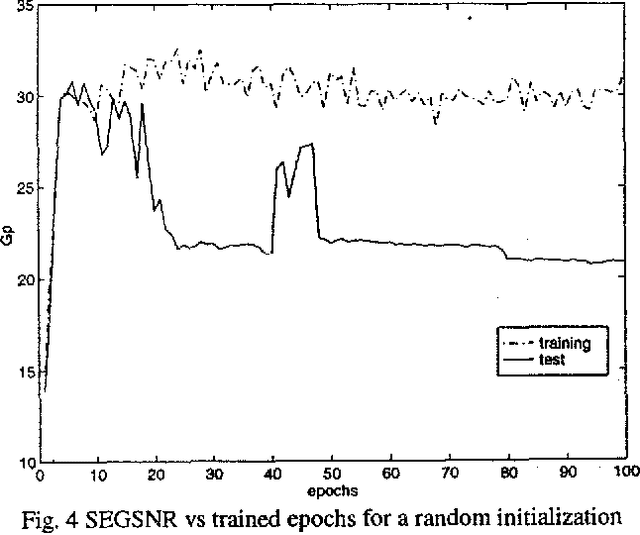
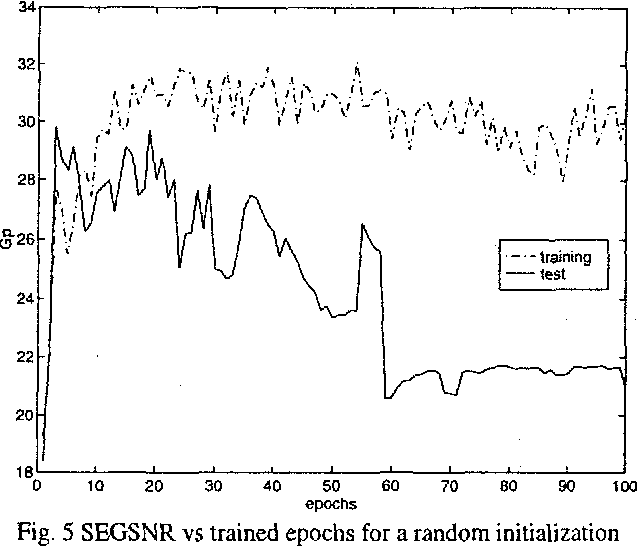
In the last years there has been a growing interest for nonlinear speech models. Several works have been published revealing the better performance of nonlinear techniques, but little attention has been dedicated to the implementation of the nonlinear model into real applications. This work is focused on the study of the behaviour of a nonlinear predictive model based on neural nets, in a speech waveform coder. Our novel scheme obtains an improvement in SEGSNR between 1 and 2 dB for an adaptive quantization ranging from 2 to 5 bits.
* 4 pages, published in Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP '98 (Cat. No.98CH36181) Seattle, WA, USA. arXiv admin note: text overlap with arXiv:2203.01818
Analysis of Disfluencies for automatic detection of Mild Cognitive Impartment: a deep learning approach
Mar 22, 2022
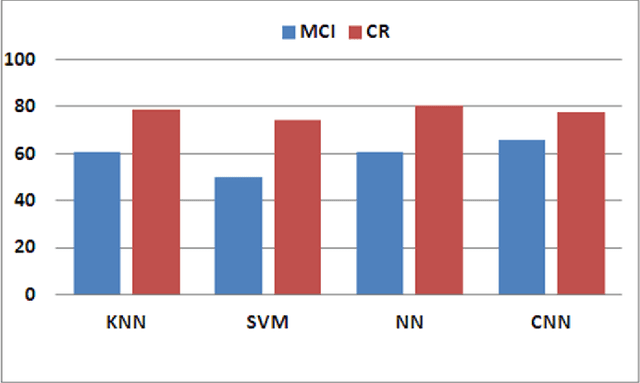
The so-called Mild Cognitive Impairment (MCI) or cognitive loss appears in a previous stage before Alzheimer's Disease (AD), but it does not seem sufficiently severe to interfere in independent abilities of daily life, so it usually does not receive an appropriate diagnosis. Its detection is a challenging issue to be addressed by medical specialists. This work presents a novel proposal based on automatic analysis of speech and disfluencies aimed at supporting MCI diagnosis. The approach includes deep learning by means of Convolutional Neural Networks (CNN) and non-linear multifeature modelling. Moreover, to select the most relevant features non-parametric Mann-Whitney U-testt and Support Vector Machine Attribute (SVM) evaluation are used.
* 5 pages, published in 2017 International Conference and Workshop on Bioinspired Intelligence (IWOBI), 2017, pp. 1-4, 10-12 July Funchal (Portugal)
Multi-class versus One-class classifier in spontaneous speech analysis oriented to Alzheimer Disease diagnosis
Mar 21, 2022
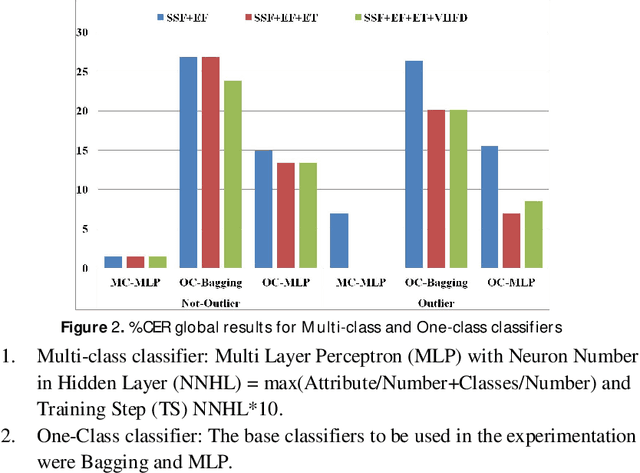
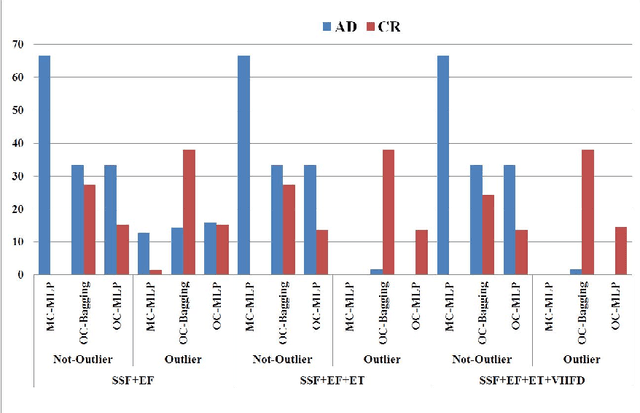
Most of medical developments require the ability to identify samples that are anomalous with respect to a target group or control group, in the sense they could belong to a new, previously unseen class or are not class data. In this case when there are not enough data to train two-class One-class classification appear like an available solution. On the other hand non-linear approaches could give very useful information. The aim of our project is to contribute to earlier diagnosis of AD and better estimates of its severity by using automatic analysis performed through new biomarkers extracted from speech signal. The methods selected in this case are speech biomarkers oriented to Spontaneous Speech and Emotional Response Analysis. In this approach One-class classifiers and two-class classifiers are analyzed. The use of information about outlier and Fractal Dimension features improves the system performance.
* 10 pages, published in International Conference on NONLINEAR SPEECH PROCESSING, NOLISP 2015 jointly organized with the 25th Italian Workshop on Neural Networks, WIRN 2015, held at May 2015, Vietri sul Mare, Salerno, Italy
Perceptual Features as Markers of Parkinson's Disease: The Issue of Clinical Interpretability
Mar 21, 2022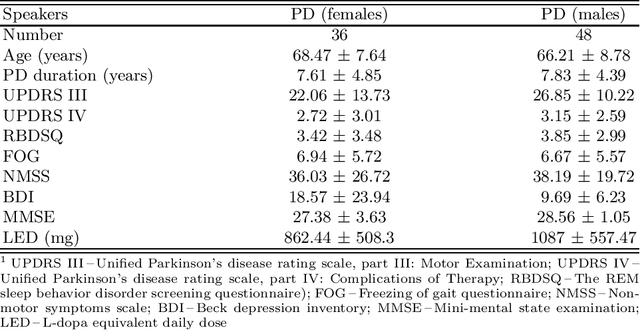
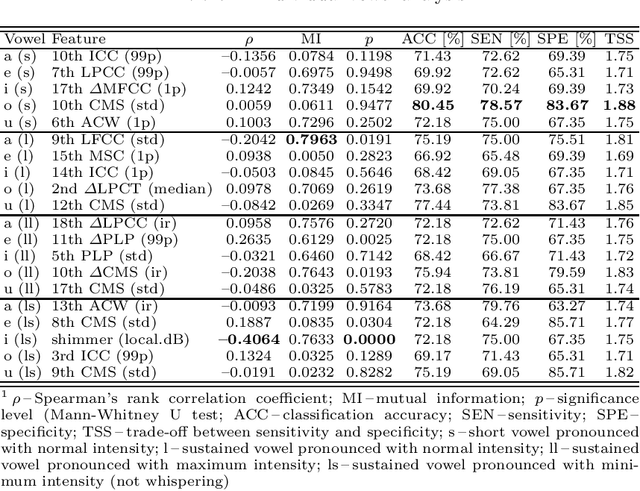
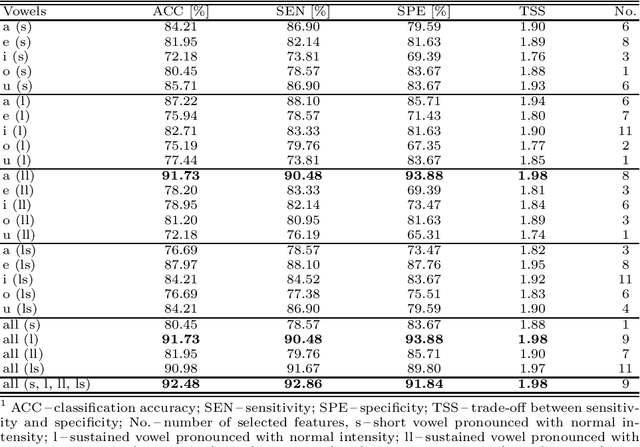
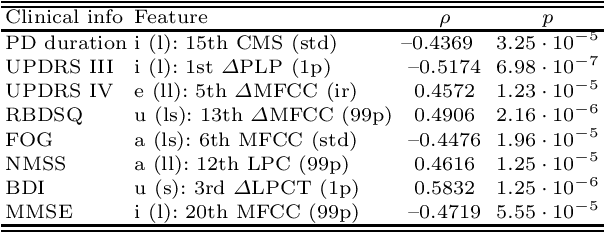
Up to 90% of patients with Parkinson's disease (PD) suffer from hypokinetic dysathria (HD) which is also manifested in the field of phonation. Clinical signs of HD like monoloudness, monopitch or hoarse voice are usually quantified by conventional clinical interpretable features (jitter, shimmer, harmonic-to-noise ratio, etc.). This paper provides large and robust insight into perceptual analysis of 5 Czech vowels of 84 PD patients and proves that despite the clinical inexplicability the perceptual features outperform the conventional ones, especially in terms of discrimination power (classification accuracy ACC = 92 %, sensitivity SEN = 93 %, specificity SPE = 92 %) and partial correlation with clinical scores like UPDRS (Unified Parkinson's disease rating scale), MMSE (Mini-mental state examination) or FOG (Freezing of gait questionnaire), where p < 0.0001.
* 8 pages, published in International Conference on NONLINEAR SPEECH PROCESSING, NOLISP 2015 jointly organized with the 25th Italian Workshop on Neural Networks, WIRN 2015, held at May 2015, Vietri sul Mare, Salerno, Italy
Identification of Hypokinetic Dysarthria Using Acoustic Analysis of Poem Recitation
Mar 18, 2022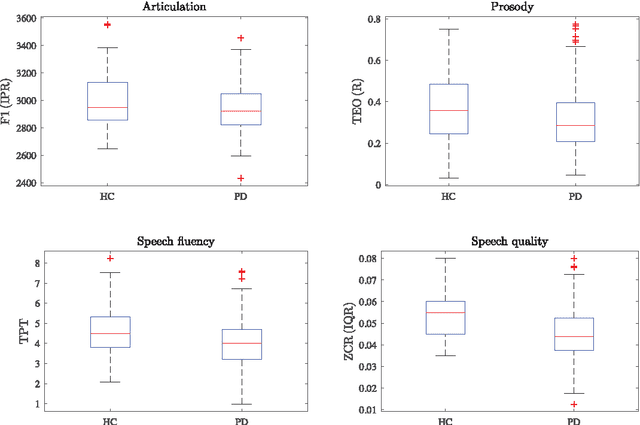
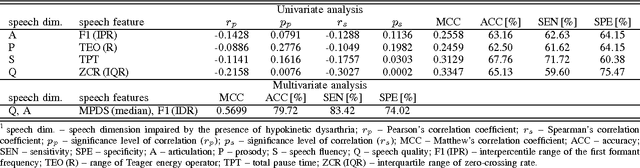
Up to 90 % of patients with Parkinson's disease (PD) suffer from hypokinetic dysarthria (HD). In this work, we analysed the power of conventional speech features quantifying imprecise articulation, dysprosody, speech dysfluency and speech quality deterioration extracted from a specialized poem recitation task to discriminate dysarthric and healthy speech. For this purpose, 152 speakers (53 healthy speakers, 99 PD patients) were examined. Only mildly strong correlation between speech features and clinical status of the speakers was observed. In the case of univariate classification analysis, sensitivity of 62.63% (imprecise articulation), 61.62% (dysprosody), 71.72% (speech dysfluency) and 59.60% (speech quality deterioration) was achieved. Multivariate classification analysis improved the classification performance. Sensitivity of 83.42% using only two features describing imprecise articulation and speech quality deterioration in HD was achieved. We showed the promising potential of the selected speech features and especially the use of poem recitation task to quantify and identify HD in PD.