 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterless Gene-pool Optimal Mixing Evolutionary Algorithms
Sep 11, 2021


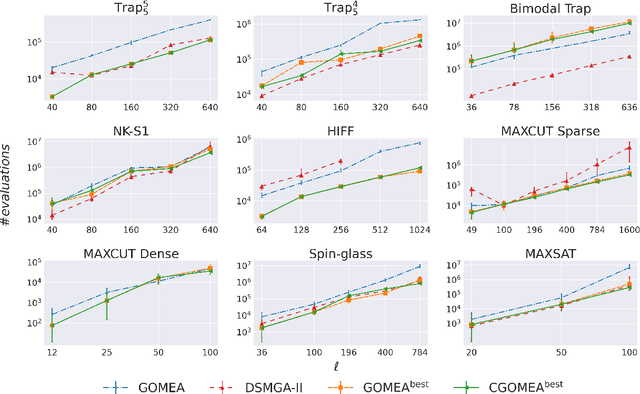
When it comes to solving optimization problems with evolutionary algorithms (EAs) in a reliable and scalable manner, detecting and exploiting linkage information, i.e., dependencies between variables, can be key. In this article, we present the latest version of, and propose substantial enhancements to, the Gene-pool Optimal Mixing Evoutionary Algorithm (GOMEA): an EA explicitly designed to estimate and exploit linkage information. We begin by performing a large-scale search over several GOMEA design choices, to understand what matters most and obtain a generally best-performing version of the algorithm. Next, we introduce a novel version of GOMEA, called CGOMEA, where linkage-based variation is further improved by filtering solution mating based on conditional dependencies. We compare our latest version of GOMEA, the newly introduced CGOMEA, and another contending linkage-aware EA DSMGA-II in an extensive experimental evaluation, involving a benchmark set of 9 black-box problems that can only be solved efficiently if their inherent dependency structure is unveiled and exploited. Finally, in an attempt to make EAs more usable and resilient to parameter choices, we investigate the performance of different automatic population management schemes for GOMEA and CGOMEA, de facto making the EAs parameterless. Our results show that GOMEA and CGOMEA significantly outperform the original GOMEA and DSMGA-II on most problems, setting a new state of the art for the field.
The five Is: Key principles for interpretable and safe conversational AI
Aug 31, 2021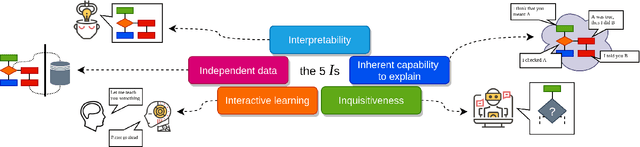
In this position paper, we present five key principles, namely interpretability, inherent capability to explain, independent data, interactive learning, and inquisitiveness, for the development of conversational AI that, unlike the currently popular black box approaches, is transparent and accountable. At present, there is a growing concern with the use of black box statistical language models: While displaying impressive average performance, such systems are also prone to occasional spectacular failures, for which there is no clear remedy. In an effort to initiate a discussion on possible alternatives, we outline and exemplify how our five principles enable the development of conversational AI systems that are transparent and thus safer for use. We also present some of the challenges inherent in the implementation of those principles.
Contemporary Symbolic Regression Methods and their Relative Performance
Jul 29, 2021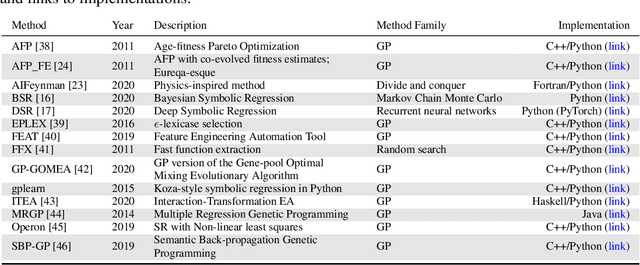
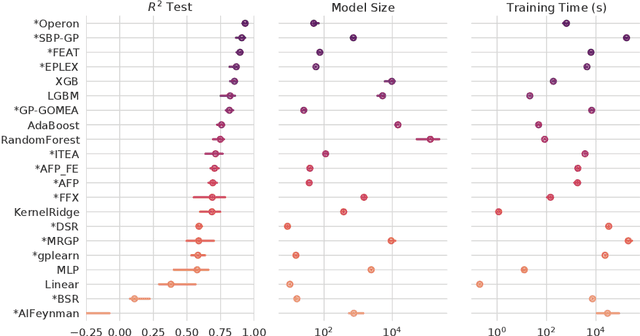

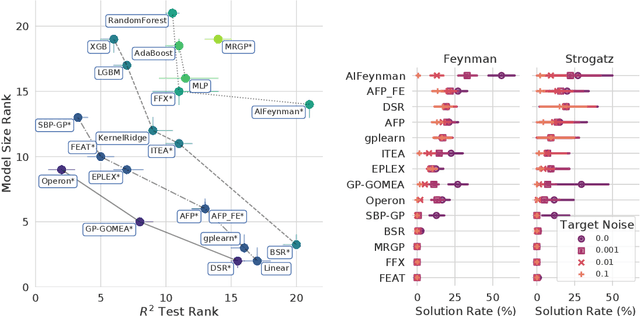
Many promising approaches to symbolic regression have been presented in recent years, yet progress in the field continues to suffer from a lack of uniform, robust, and transparent benchmarking standards. In this paper, we address this shortcoming by introducing an open-source, reproducible benchmarking platform for symbolic regression. We assess 14 symbolic regression methods and 7 machine learning methods on a set of 252 diverse regression problems. Our assessment includes both real-world datasets with no known model form as well as ground-truth benchmark problems, including physics equations and systems of ordinary differential equations. For the real-world datasets, we benchmark the ability of each method to learn models with low error and low complexity relative to state-of-the-art machine learning methods. For the synthetic problems, we assess each method's ability to find exact solutions in the presence of varying levels of noise. Under these controlled experiments, we conclude that the best performing methods for real-world regression combine genetic algorithms with parameter estimation and/or semantic search drivers. When tasked with recovering exact equations in the presence of noise, we find that deep learning and genetic algorithm-based approaches perform similarly. We provide a detailed guide to reproducing this experiment and contributing new methods, and encourage other researchers to collaborate with us on a common and living symbolic regression benchmark.
Model Learning with Personalized Interpretability Estimation (ML-PIE)
Apr 27, 2021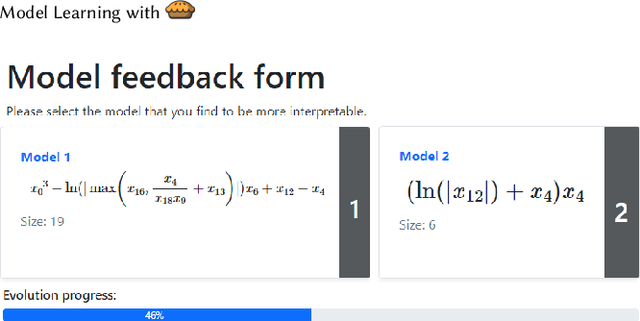
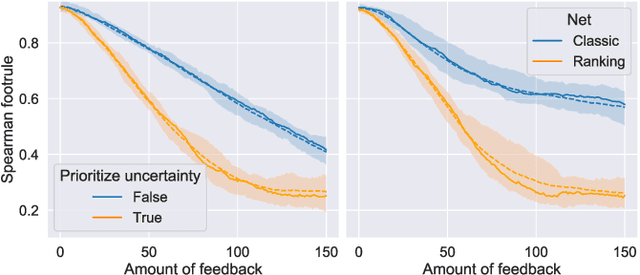
High-stakes applications require AI-generated models to be interpretable. Current algorithms for the synthesis of potentially interpretable models rely on objectives or regularization terms that represent interpretability only coarsely (e.g., model size) and are not designed for a specific user. Yet, interpretability is intrinsically subjective. In this paper, we propose an approach for the synthesis of models that are tailored to the user by enabling the user to steer the model synthesis process according to her or his preferences. We use a bi-objective evolutionary algorithm to synthesize models with trade-offs between accuracy and a user-specific notion of interpretability. The latter is estimated by a neural network that is trained concurrently to the evolution using the feedback of the user, which is collected using uncertainty-based active learning. To maximize usability, the user is only asked to tell, given two models at the time, which one is less complex. With experiments on two real-world datasets involving 61 participants, we find that our approach is capable of learning estimations of interpretability that can be very different for different users. Moreover, the users tend to prefer models found using the proposed approach over models found using non-personalized interpretability indices.
Simple Simultaneous Ensemble Learning in Genetic Programming
Oct 01, 2020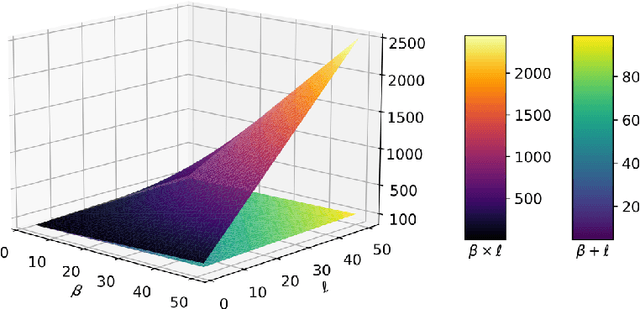
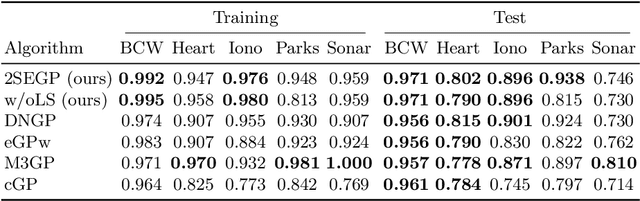
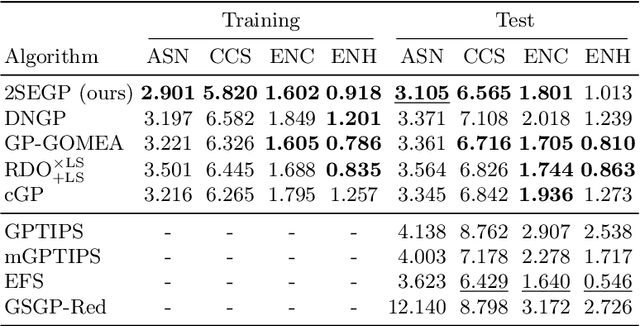
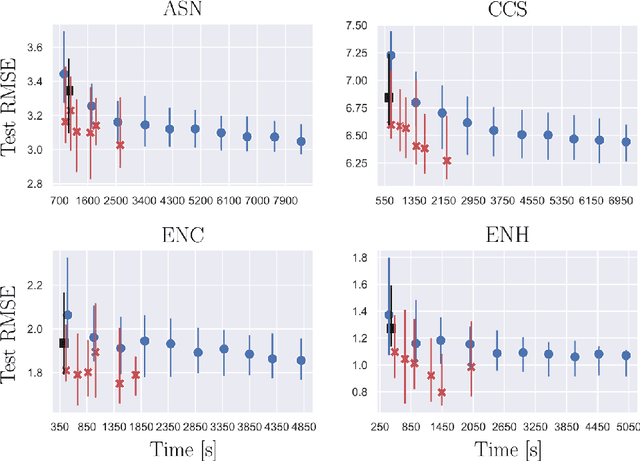
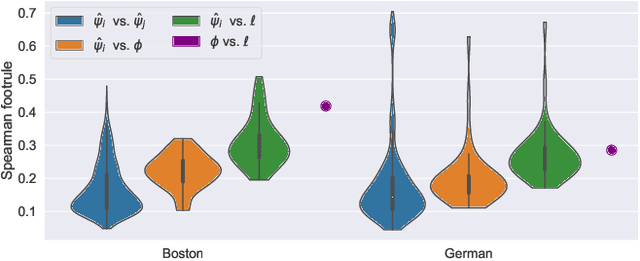
Learning ensembles by bagging can substantially improve the generalization performance of low-bias high-variance estimators, including those evolved by Genetic Programming (GP). Yet, the best way to learn ensembles in GP remains to be determined. This work attempts to fill the gap between existing GP ensemble learning algorithms, which are often either simple but expensive, or efficient but complex. We propose a new algorithm that is both simple and efficient, named Simple Simultaneous Ensemble Genetic Programming (2SEGP). 2SEGP is obtained by relatively minor modifications to fitness evaluation and selection of a classic GP algorithm, and its only drawback is an (arguably small) increase of the fitness evaluation cost from the classic $\mathcal{O}(n \ell)$ to $\mathcal{O}(n(\ell + \beta))$, with $n$ the number of observations and $\ell$/$\beta$ the estimator/ensemble size. Experimental comparisons on real-world datasets between supervised classification and regression show that, despite its simplicity, 2SEGP fares very well against state-of-the-art (ensemble and not) GP algorithms. We further provide insights into what matters in 2SEGP by (i) scaling $\beta$, (ii) ablating the proposed selection method, (iii) observing the evolvability induced by traditional subtree variation.
Learning a Formula of Interpretability to Learn Interpretable Formulas
May 28, 2020
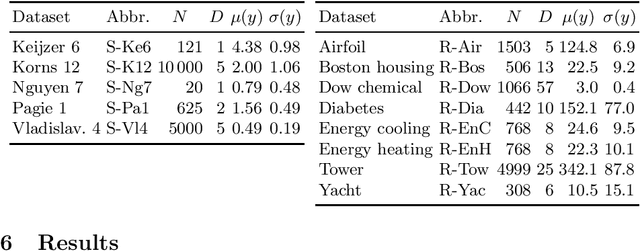

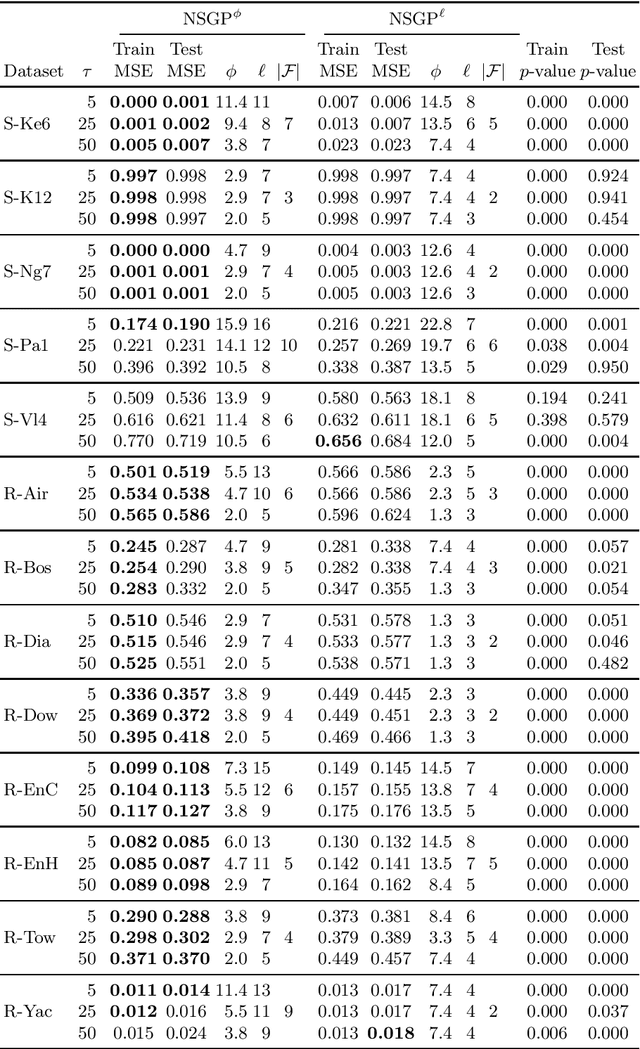
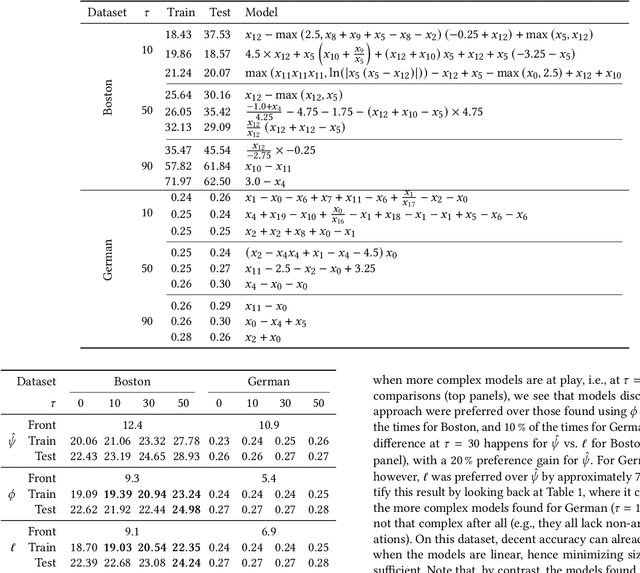
Many risk-sensitive applications require Machine Learning (ML) models to be interpretable. Attempts to obtain interpretable models typically rely on tuning, by trial-and-error, hyper-parameters of model complexity that are only loosely related to interpretability. We show that it is instead possible to take a meta-learning approach: an ML model of non-trivial Proxies of Human Interpretability (PHIs) can be learned from human feedback, then this model can be incorporated within an ML training process to directly optimize for interpretability. We show this for evolutionary symbolic regression. We first design and distribute a survey finalized at finding a link between features of mathematical formulas and two established PHIs, simulatability and decomposability. Next, we use the resulting dataset to learn an ML model of interpretability. Lastly, we query this model to estimate the interpretability of evolving solutions within bi-objective genetic programming. We perform experiments on five synthetic and eight real-world symbolic regression problems, comparing to the traditional use of solution size minimization. The results show that the use of our model leads to formulas that are, for a same level of accuracy-interpretability trade-off, either significantly more or equally accurate. Moreover, the formulas are also arguably more interpretable. Given the very positive results, we believe that our approach represents an important stepping stone for the design of next-generation interpretable (evolutionary) ML algorithms.
Machine learning for automatic construction of pseudo-realistic pediatric abdominal phantoms
Sep 09, 2019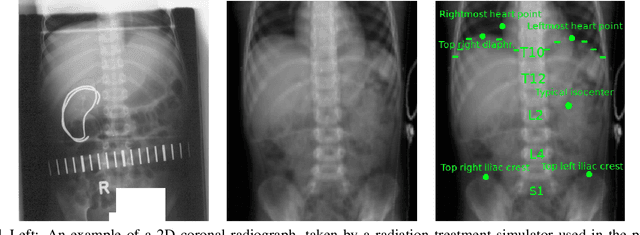
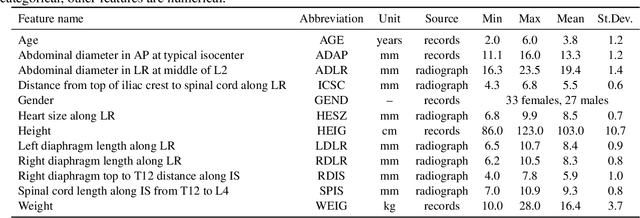
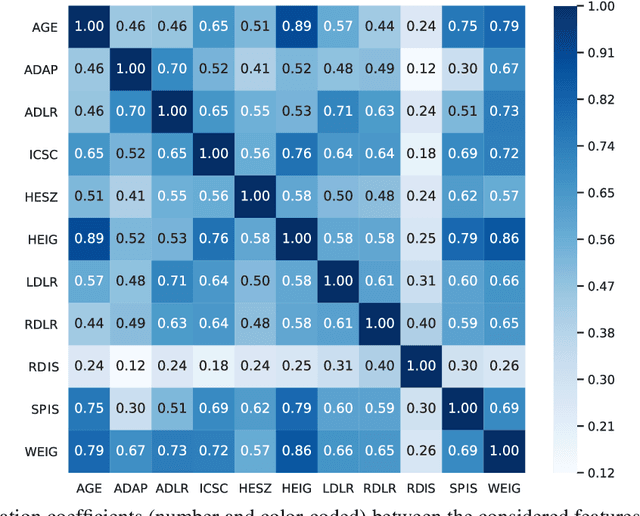

Machine Learning (ML) is proving extremely beneficial in many healthcare applications. In pediatric oncology, retrospective studies that investigate the relationship between treatment and late adverse effects still rely on simple heuristics. To assess the effects of radiation therapy, treatment plans are typically simulated on phantoms, i.e., virtual surrogates of patient anatomy. Currently, phantoms are built according to reasonable, yet simple, human-designed criteria. This often results in a lack of individualization. We present a novel approach that combines imaging and ML to build individualized phantoms automatically. Given the features of a patient treated historically (only 2D radiographs available), and a database of 3D Computed Tomography (CT) imaging with organ segmentations and relative patient features, our approach uses ML to predict how to assemble a patient-specific phantom automatically. Experiments on 60 abdominal CTs of pediatric patients show that our approach constructs significantly more representative phantoms than using current phantom building criteria, in terms of location and shape of the abdomen and of two considered organs, the liver and the spleen. Among several ML algorithms considered, the Gene-pool Optimal Mixing Evolutionary Algorithm for Genetic Programming (GP-GOMEA) is found to deliver the best performing models, which are, moreover, transparent and interpretable mathematical expressions.
On Explaining Machine Learning Models by Evolving Crucial and Compact Features
Jul 04, 2019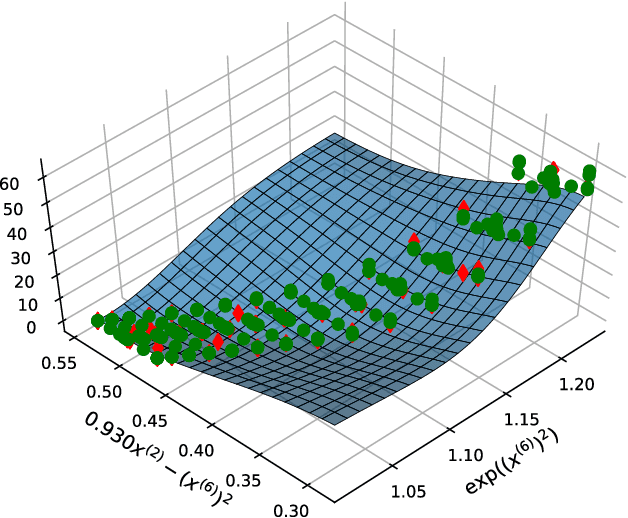

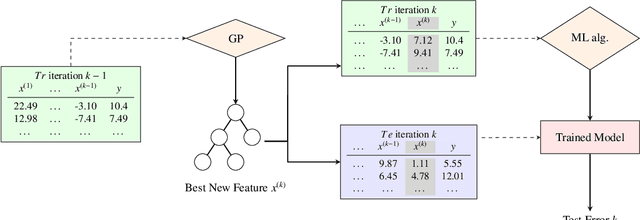
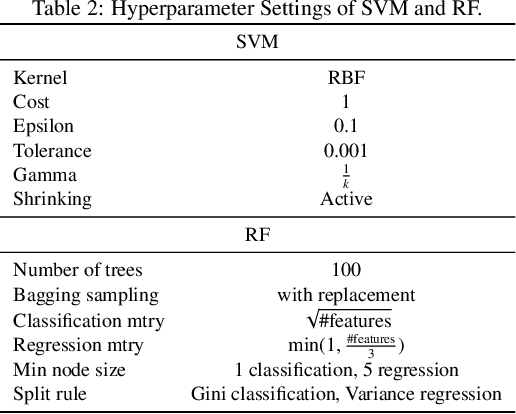
Feature construction can substantially improve the accuracy of Machine Learning (ML) algorithms. Genetic Programming (GP) has been proven to be effective at this task by evolving non-linear combinations of input features. GP additionally has the potential to improve ML explainability since explicit expressions are evolved. Yet, in most GP works the complexity of evolved features is not explicitly bound or minimized though this is arguably key for explainability. In this article, we assess to what extent GP still performs favorably at feature construction when constructing features that are (1) Of small-enough number, to enable visualization of the behavior of the ML model; (2) Of small-enough size, to enable interpretability of the features themselves; (3) Of sufficient informative power, to retain or even improve the performance of the ML algorithm. We consider a simple feature construction scheme using three different GP algorithms, as well as random search, to evolve features for four ML algorithms, including support vector machines and random forest. Our results on 20 datasets pertaining to classification and regression problems show that constructing only two compact features can be sufficient to rival the use of the entire original feature set. We further find that a modern GP algorithm, GP-GOMEA, performs best overall. These results, combined with examples that we provide of readable constructed features and of 2D visualizations of ML behavior, lead us to positively conclude that GP-based feature construction still works well when explicitly searching for compact features, making it extremely helpful to explain ML models.
A Model-based Genetic Programming Approach for Symbolic Regression of Small Expressions
Apr 05, 2019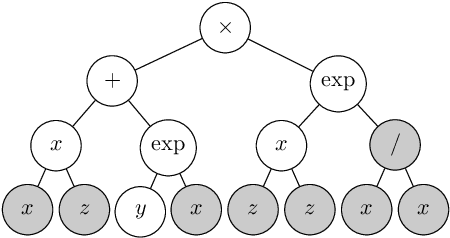

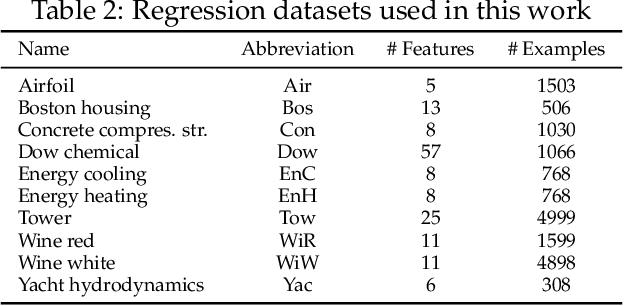
The Gene-pool Optimal Mixing Evolutionary Algorithm (GOMEA) is a model-based EA framework that has been shown to perform well in several domains, including Genetic Programming (GP). Differently from traditional EAs where variation acts randomly, GOMEA learns a model of interdependencies within the genotype, i.e., the linkage, to estimate what patterns to propagate. In this article, we study the role of Linkage Learning (LL) performed by GOMEA in Symbolic Regression (SR). We show that the non-uniformity in the distribution of the genotype in GP populations negatively biases LL, and propose a method to correct for this. We also propose approaches to improve LL when ephemeral random constants are used. Furthermore, we adapt a scheme of interleaving runs to alleviate the burden of tuning the population size, a crucial parameter for LL, to SR. We run experiments on 10 real-world datasets, enforcing a strict limitation on solution size, to enable interpretability. We find that the new LL method outperforms the standard one, and that GOMEA outperforms both traditional and semantic GP. We also find that the small solutions evolved by GOMEA are competitive with tuned decision trees, making GOMEA a promising new approach to SR.