 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus of Attention Improves Information Transfer in Visual Features
Jun 16, 2020
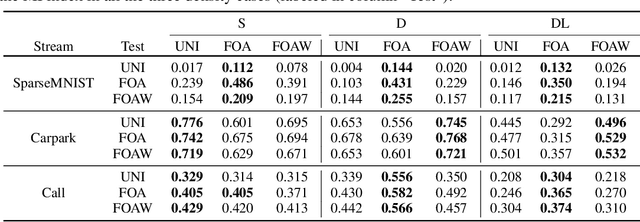

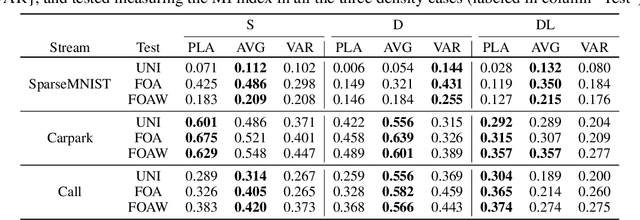
Unsupervised learning from continuous visual streams is a challenging problem that cannot be naturally and efficiently managed in the classic batch-mode setting of computation. The information stream must be carefully processed accordingly to an appropriate spatio-temporal distribution of the visual data, while most approaches of learning commonly assume uniform probability density. In this paper we focus on unsupervised learning for transferring visual information in a truly online setting by using a computational model that is inspired to the principle of least action in physics. The maximization of the mutual information is carried out by a temporal process which yields online estimation of the entropy terms. The model, which is based on second-order differential equations, maximizes the information transfer from the input to a discrete space of symbols related to the visual features of the input, whose computation is supported by hidden neurons. In order to better structure the input probability distribution, we use a human-like focus of attention model that, coherently with the information maximization model, is also based on second-order differential equations. We provide experimental results to support the theory by showing that the spatio-temporal filtering induced by the focus of attention allows the system to globally transfer more information from the input stream over the focused areas and, in some contexts, over the whole frames with respect to the unfiltered case that yields uniform probability distributions.
Deep Lagrangian Constraint-based Propagation in Graph Neural Networks
May 27, 2020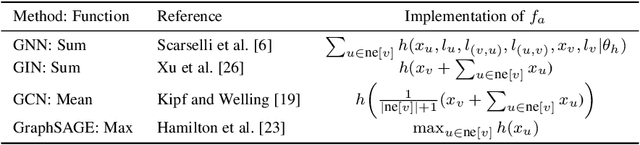
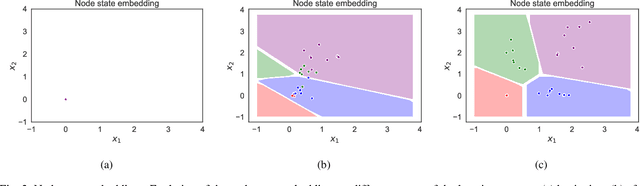
Several real-world applications are characterized by data that exhibit a complex structure that can be represented using graphs. The popularity of deep learning techniques renewed the interest in neural architectures able to process these patterns, inspired by the Graph Neural Network (GNN) model. GNNs encode the state of the nodes of the graph by means of an iterative diffusion procedure that, during the learning stage, must be computed at every epoch, until the fixed point of a learnable state transition function is reached, propagating the information among the neighbouring nodes. We propose a novel approach to learning in GNNs, based on constrained optimization in the Lagrangian framework. Learning both the transition function and the node states is the outcome of a joint process, in which the state convergence procedure is implicitly expressed by a constraint satisfaction mechanism, avoiding iterative epoch-wise procedures and the network unfolding. Our computational structure searches for saddle points of the Lagrangian in the adjoint space composed of weights, nodes state variables and Lagrange multipliers. This process is further enhanced by multiple layers of constraints that accelerate the diffusion process. An experimental analysis shows that the proposed approach compares favourably with popular models on several benchmarks.
A Lagrangian Approach to Information Propagation in Graph Neural Networks
Feb 19, 2020
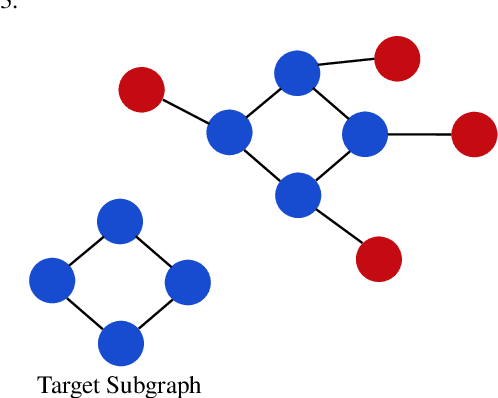
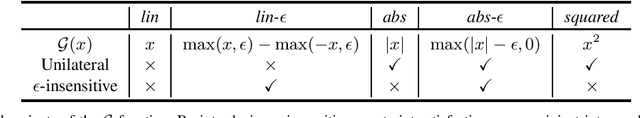
In many real world applications, data are characterized by a complex structure, that can be naturally encoded as a graph. In the last years, the popularity of deep learning techniques has renewed the interest in neural models able to process complex patterns. In particular, inspired by the Graph Neural Network (GNN) model, different architectures have been proposed to extend the original GNN scheme. GNNs exploit a set of state variables, each assigned to a graph node, and a diffusion mechanism of the states among neighbor nodes, to implement an iterative procedure to compute the fixed point of the (learnable) state transition function. In this paper, we propose a novel approach to the state computation and the learning algorithm for GNNs, based on a constraint optimisation task solved in the Lagrangian framework. The state convergence procedure is implicitly expressed by the constraint satisfaction mechanism and does not require a separate iterative phase for each epoch of the learning procedure. In fact, the computational structure is based on the search for saddle points of the Lagrangian in the adjoint space composed of weights, neural outputs (node states), and Lagrange multipliers. The proposed approach is compared experimentally with other popular models for processing graphs.
Local Propagation in Constraint-based Neural Network
Feb 18, 2020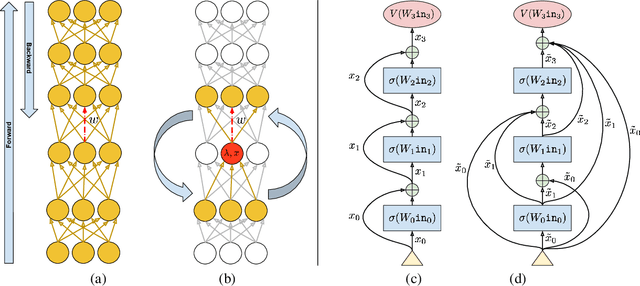
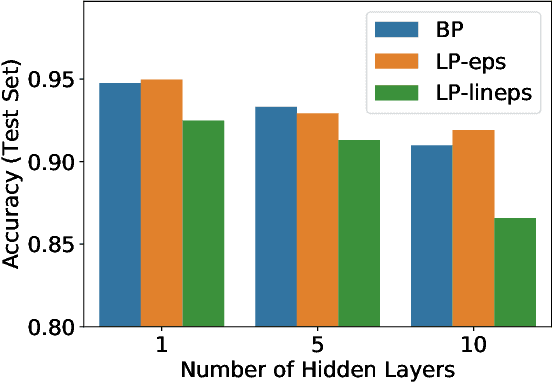
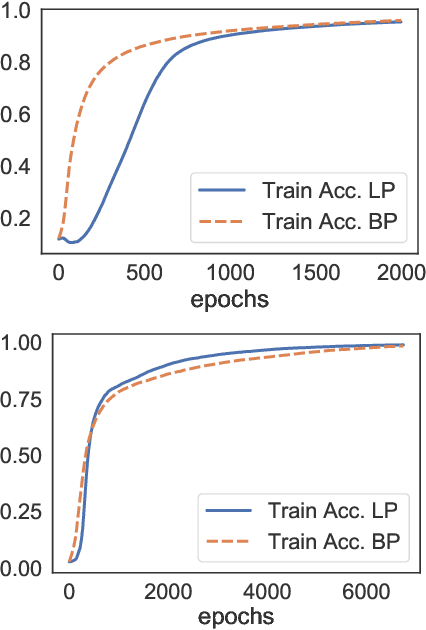
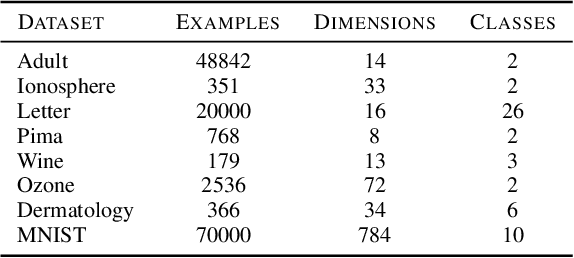
In this paper we study a constraint-based representation of neural network architectures. We cast the learning problem in the Lagrangian framework and we investigate a simple optimization procedure that is well suited to fulfil the so-called architectural constraints, learning from the available supervisions. The computational structure of the proposed Local Propagation (LP) algorithm is based on the search for saddle points in the adjoint space composed of weights, neural outputs, and Lagrange multipliers. All the updates of the model variables are locally performed, so that LP is fully parallelizable over the neural units, circumventing the classic problem of gradient vanishing in deep networks. The implementation of popular neural models is described in the context of LP, together with those conditions that trace a natural connection with Backpropagation. We also investigate the setting in which we tolerate bounded violations of the architectural constraints, and we provide experimental evidence that LP is a feasible approach to train shallow and deep networks, opening the road to further investigations on more complex architectures, easily describable by constraints.
Relational Neural Machines
Feb 06, 2020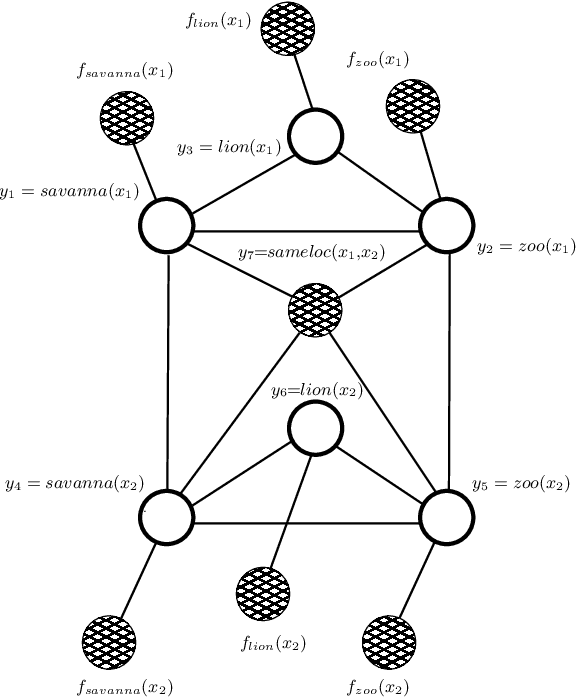


Deep learning has been shown to achieve impressive results in several tasks where a large amount of training data is available. However, deep learning solely focuses on the accuracy of the predictions, neglecting the reasoning process leading to a decision, which is a major issue in life-critical applications. Probabilistic logic reasoning allows to exploit both statistical regularities and specific domain expertise to perform reasoning under uncertainty, but its scalability and brittle integration with the layers processing the sensory data have greatly limited its applications. For these reasons, combining deep architectures and probabilistic logic reasoning is a fundamental goal towards the development of intelligent agents operating in complex environments. This paper presents Relational Neural Machines, a novel framework allowing to jointly train the parameters of the learners and of a First--Order Logic based reasoner. A Relational Neural Machine is able to recover both classical learning from supervised data in case of pure sub-symbolic learning, and Markov Logic Networks in case of pure symbolic reasoning, while allowing to jointly train and perform inference in hybrid learning tasks. Proper algorithmic solutions are devised to make learning and inference tractable in large-scale problems. The experiments show promising results in different relational tasks.
Conditions for Unnecessary Logical Constraints in Kernel Machines
Sep 24, 2019
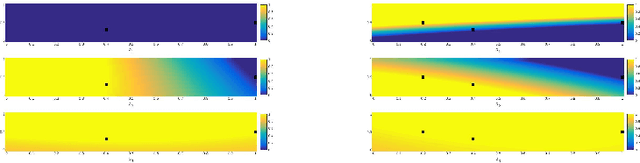
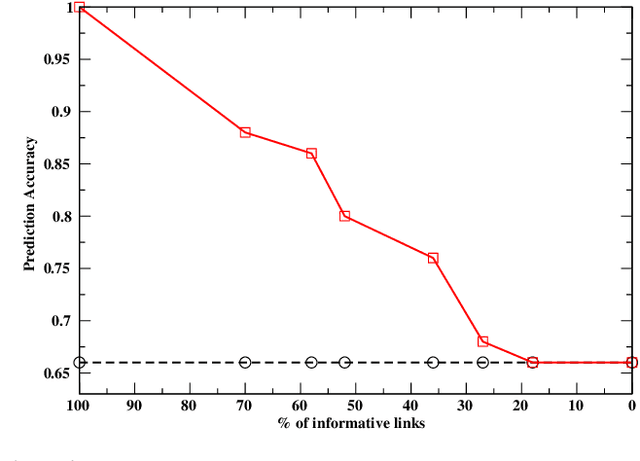
A main property of support vector machines consists in the fact that only a small portion of the training data is significant to determine the maximum margin separating hyperplane in the feature space, the so called support vectors. In a similar way, in the general scheme of learning from constraints, where possibly several constraints are considered, some of them may turn out to be unnecessary with respect to the learning optimization, even if they are active for a given optimal solution. In this paper we extend the definition of support vector to support constraint and we provide some criteria to determine which constraints can be removed from the learning problem still yielding the same optimal solutions. In particular, we discuss the case of logical constraints expressed by Lukasiewicz logic, where both inferential and algebraic arguments can be considered. Some theoretical results that characterize the concept of unnecessary constraint are proved and explained by means of examples.
Neural Poetry: Learning to Generate Poems using Syllables
Sep 24, 2019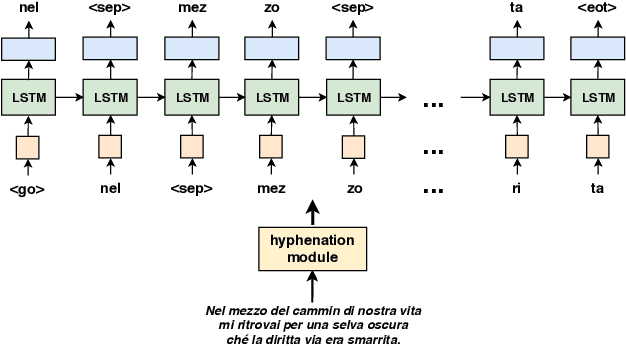


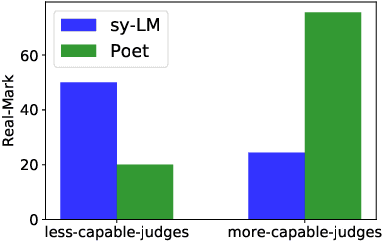
Motivated by the recent progresses on machine learning-based models that learn artistic styles, in this paper we focus on the problem of poem generation. This is a challenging task in which the machine has to capture the linguistic features that strongly characterize a certain poet, as well as the semantics of the poet's production, that are influenced by his personal experiences and by his literary background. Since poetry is constructed using syllables, that regulate the form and structure of poems, we propose a syllable-based neural language model, and we describe a poem generation mechanism that is designed around the poet style, automatically selecting the most representative generations. The poetic work of a target author is usually not enough to successfully train modern deep neural networks, so we propose a multi-stage procedure that exploits non-poetic works of the same author, and also other publicly available huge corpora to learn syntax and grammar of the target language. We focus on the Italian poet Dante Alighieri, widely famous for his Divine Comedy. A quantitative and qualitative experimental analysis of the generated tercets is reported, where we included expert judges with strong background in humanistic studies. The generated tercets are frequently considered to be real by a generic population of judges, with relative difference of 56.25\% with respect to the ones really authored by Dante, and expert judges perceived Dante's style and rhymes in the generated text.
Video Surveillance of Highway Traffic Events by Deep Learning Architectures
Sep 06, 2019

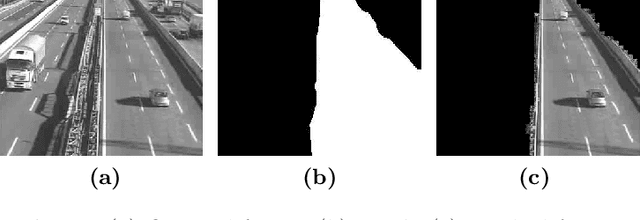
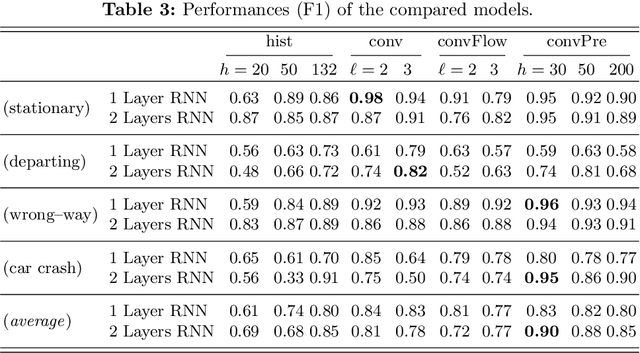
In this paper we describe a video surveillance system able to detect traffic events in videos acquired by fixed videocameras on highways. The events of interest consist in a specific sequence of situations that occur in the video, as for instance a vehicle stopping on the emergency lane. Hence, the detection of these events requires to analyze a temporal sequence in the video stream. We compare different approaches that exploit architectures based on Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs). A first approach extracts vectors of features, mostly related to motion, from each video frame and exploits a RNN fed with the resulting sequence of vectors. The other approaches are based directly on the sequence of frames, that are eventually enriched with pixel-wise motion information. The obtained stream is processed by an architecture that stacks a CNN and a RNN, and we also investigate a transfer-learning-based model. The results are very promising and the best architecture will be tested online in real operative conditions.
Learning in Text Streams: Discovery and Disambiguation of Entity and Relation Instances
Sep 06, 2019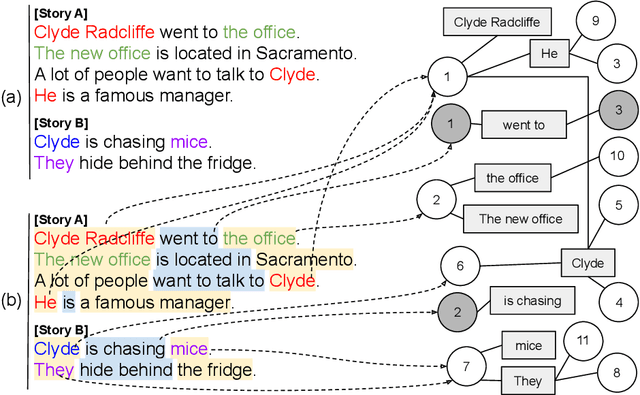
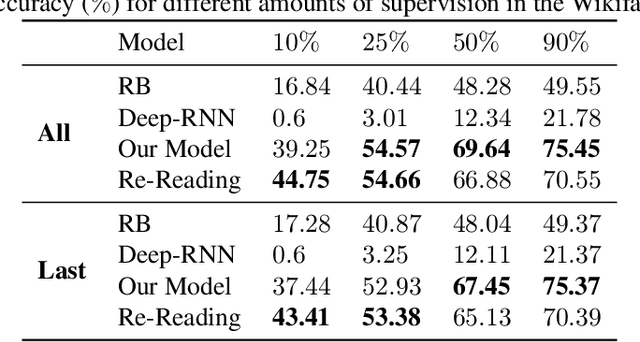
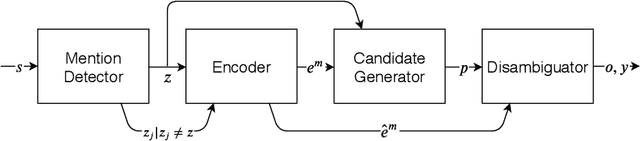

We consider a scenario where an artificial agent is reading a stream of text composed of a set of narrations, and it is informed about the identity of some of the individuals that are mentioned in the text portion that is currently being read. The agent is expected to learn to follow the narrations, thus disambiguating mentions and discovering new individuals. We focus on the case in which individuals are entities and relations, and we propose an end-to-end trainable memory network that learns to discover and disambiguate them in an online manner, performing one-shot learning, and dealing with a small number of sparse supervisions. Our system builds a not-given-in-advance knowledge base, and it improves its skills while reading unsupervised text. The model deals with abrupt changes in the narration, taking into account their effects when resolving co-references. We showcase the strong disambiguation and discovery skills of our model on a corpus of Wikipedia documents and on a newly introduced dataset, that we make publicly available.
Learning and T-Norms Theory
Jul 26, 2019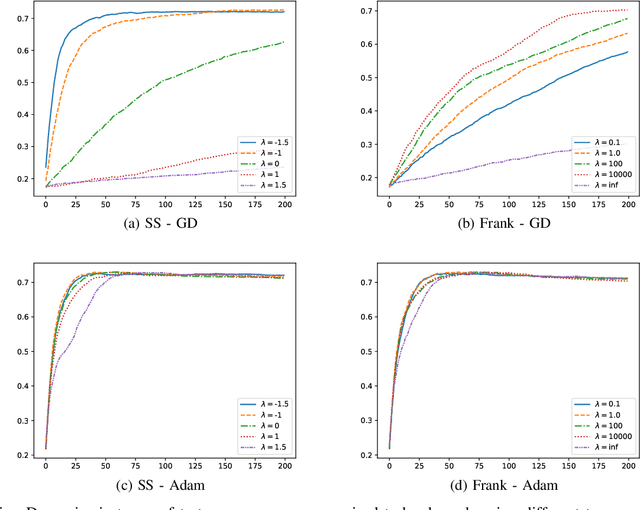


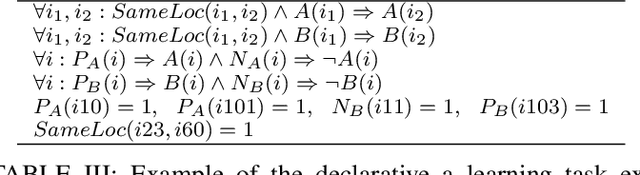
Deep learning has been shown to achieve impressive results in several domains like computer vision and natural language processing. Deep architectures are typically trained following a supervised scheme and, therefore, they rely on the availability of a large amount of labeled training data to effectively learn their parameters. Neuro-symbolic approaches have recently gained popularity to inject prior knowledge into a deep learner without requiring it to induce this knowledge from data. These approaches can potentially learn competitive solutions with a significant reduction of the amount of supervised data. A large class of neuro-symbolic approaches is based on First-Order Logic to represent prior knowledge, that is relaxed to a differentiable form using fuzzy logic. This paper shows that the loss function expressing these neuro-symbolic learning tasks can be unambiguously determined given the selection of a t-norm generator. When restricted to simple supervised learning, the presented theoretical apparatus provides a clean justification to the popular cross-entropy loss, that has been shown to provide faster convergence and to reduce the vanishing gradient problem in very deep structures. One advantage of the proposed learning formulation is that it can be extended to all the knowledge that can be represented by a neuro-symbolic method, and it allows the development of a novel class of loss functions, that the experimental results show to lead to faster convergence rates than other approaches previously proposed in the literature.