 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural paraphrasing by automatically crawled and aligned sentence pairs
Feb 16, 2024

Paraphrasing is the task of re-writing an input text using other words, without altering the meaning of the original content. Conversational systems can exploit automatic paraphrasing to make the conversation more natural, e.g., talking about a certain topic using different paraphrases in different time instants. Recently, the task of automatically generating paraphrases has been approached in the context of Natural Language Generation (NLG). While many existing systems simply consist in rule-based models, the recent success of the Deep Neural Networks in several NLG tasks naturally suggests the possibility of exploiting such networks for generating paraphrases. However, the main obstacle toward neural-network-based paraphrasing is the lack of large datasets with aligned pairs of sentences and paraphrases, that are needed to efficiently train the neural models. In this paper we present a method for the automatic generation of large aligned corpora, that is based on the assumption that news and blog websites talk about the same events using different narrative styles. We propose a similarity search procedure with linguistic constraints that, given a reference sentence, is able to locate the most similar candidate paraphrases out from millions of indexed sentences. The data generation process is evaluated in the case of the Italian language, performing experiments using pointer-based deep neural architectures.
* The 6th International Conference on Social Networks Analysis, Management and Security (SNAMS 2019)
Multitask Kernel-based Learning with Logic Constraints
Feb 16, 2024


This paper presents a general framework to integrate prior knowledge in the form of logic constraints among a set of task functions into kernel machines. The logic propositions provide a partial representation of the environment, in which the learner operates, that is exploited by the learning algorithm together with the information available in the supervised examples. In particular, we consider a multi-task learning scheme, where multiple unary predicates on the feature space are to be learned by kernel machines and a higher level abstract representation consists of logic clauses on these predicates, known to hold for any input. A general approach is presented to convert the logic clauses into a continuous implementation, that processes the outputs computed by the kernel-based predicates. The learning task is formulated as a primal optimization problem of a loss function that combines a term measuring the fitting of the supervised examples, a regularization term, and a penalty term that enforces the constraints on both supervised and unsupervised examples. The proposed semi-supervised learning framework is particularly suited for learning in high dimensionality feature spaces, where the supervised training examples tend to be sparse and generalization difficult. Unlike for standard kernel machines, the cost function to optimize is not generally guaranteed to be convex. However, the experimental results show that it is still possible to find good solutions using a two stage learning schema, in which first the supervised examples are learned until convergence and then the logic constraints are forced. Some promising experimental results on artificial multi-task learning tasks are reported, showing how the classification accuracy can be effectively improved by exploiting the a priori rules and the unsupervised examples.
* The 19th European Conference on Artificial Intelligence (ECAI 2010)
AI-Powered Arabic Crossword Puzzle Generation for Educational Applications
Dec 03, 2023



This paper presents the first Arabic crossword puzzle generator driven by advanced AI technology. Leveraging cutting-edge large language models including GPT4, GPT3-Davinci, GPT3-Curie, GPT3-Babbage, GPT3-Ada, and BERT, the system generates distinctive and challenging clues. Based on a dataset comprising over 50,000 clue-answer pairs, the generator employs fine-tuning, few/zero-shot learning strategies, and rigorous quality-checking protocols to enforce the generation of high-quality clue-answer pairs. Importantly, educational crosswords contribute to enhancing memory, expanding vocabulary, and promoting problem-solving skills, thereby augmenting the learning experience through a fun and engaging approach, reshaping the landscape of traditional learning methods. The overall system can be exploited as a powerful educational tool that amalgamates AI and innovative learning techniques, heralding a transformative era for Arabic crossword puzzles and the intersection of technology and education.
Italian Crossword Generator: Enhancing Education through Interactive Word Puzzles
Nov 27, 2023Educational crosswords offer numerous benefits for students, including increased engagement, improved understanding, critical thinking, and memory retention. Creating high-quality educational crosswords can be challenging, but recent advances in natural language processing and machine learning have made it possible to use language models to generate nice wordplays. The exploitation of cutting-edge language models like GPT3-DaVinci, GPT3-Curie, GPT3-Babbage, GPT3-Ada, and BERT-uncased has led to the development of a comprehensive system for generating and verifying crossword clues. A large dataset of clue-answer pairs was compiled to fine-tune the models in a supervised manner to generate original and challenging clues from a given keyword. On the other hand, for generating crossword clues from a given text, Zero/Few-shot learning techniques were used to extract clues from the input text, adding variety and creativity to the puzzles. We employed the fine-tuned model to generate data and labeled the acceptability of clue-answer parts with human supervision. To ensure quality, we developed a classifier by fine-tuning existing language models on the labeled dataset. Conversely, to assess the quality of clues generated from the given text using zero/few-shot learning, we employed a zero-shot learning approach to check the quality of generated clues. The results of the evaluation have been very promising, demonstrating the effectiveness of the approach in creating high-standard educational crosswords that offer students engaging and rewarding learning experiences.
Multitask Kernel-based Learning with First-Order Logic Constraints
Nov 08, 2023In this paper we propose a general framework to integrate supervised and unsupervised examples with background knowledge expressed by a collection of first-order logic clauses into kernel machines. In particular, we consider a multi-task learning scheme where multiple predicates defined on a set of objects are to be jointly learned from examples, enforcing a set of FOL constraints on the admissible configurations of their values. The predicates are defined on the feature spaces, in which the input objects are represented, and can be either known a priori or approximated by an appropriate kernel-based learner. A general approach is presented to convert the FOL clauses into a continuous implementation that can deal with the outputs computed by the kernel-based predicates. The learning problem is formulated as a semi-supervised task that requires the optimization in the primal of a loss function that combines a fitting loss measure on the supervised examples, a regularization term, and a penalty term that enforces the constraints on both the supervised and unsupervised examples. Unfortunately, the penalty term is not convex and it can hinder the optimization process. However, it is possible to avoid poor solutions by using a two stage learning schema, in which the supervised examples are learned first and then the constraints are enforced.
* The 20th International Conference on Inductive Logic Programming (ILP 2010). Florence, Italy. June 27-30 2010
SortNet: Learning To Rank By a Neural-Based Sorting Algorithm
Nov 03, 2023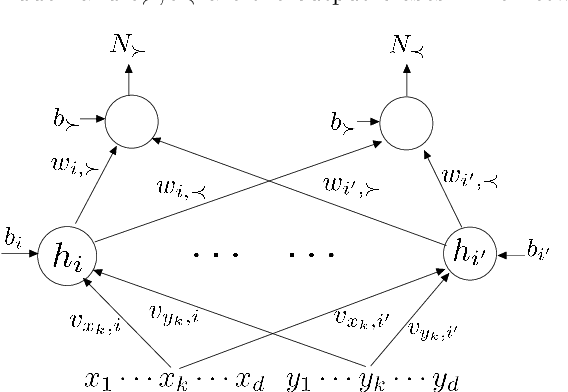
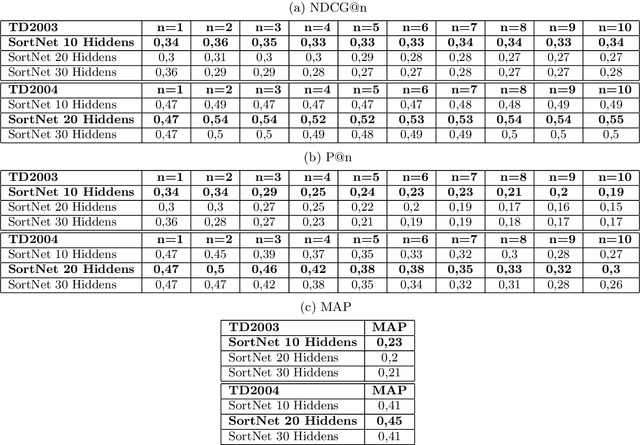
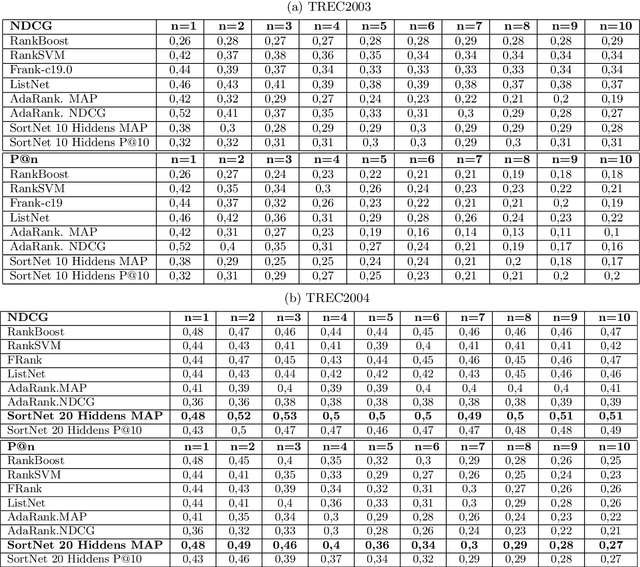
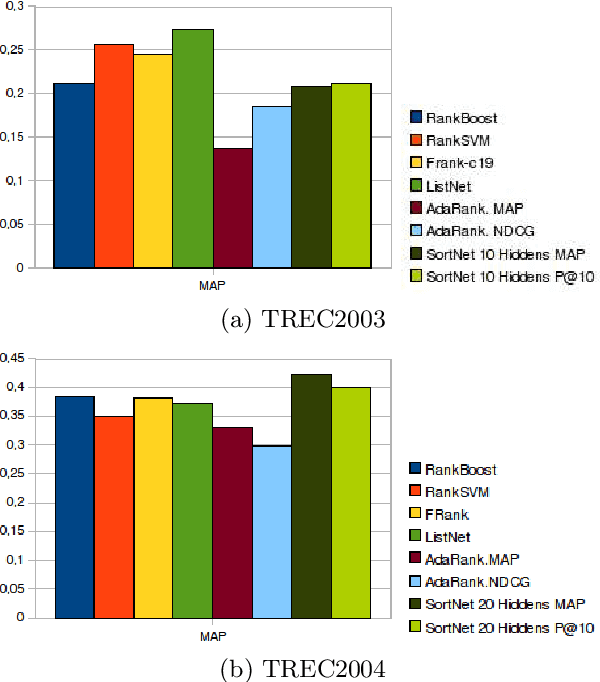
The problem of relevance ranking consists of sorting a set of objects with respect to a given criterion. Since users may prefer different relevance criteria, the ranking algorithms should be adaptable to the user needs. Two main approaches exist in literature for the task of learning to rank: 1) a score function, learned by examples, which evaluates the properties of each object yielding an absolute relevance value that can be used to order the objects or 2) a pairwise approach, where a "preference function" is learned using pairs of objects to define which one has to be ranked first. In this paper, we present SortNet, an adaptive ranking algorithm which orders objects using a neural network as a comparator. The neural network training set provides examples of the desired ordering between pairs of items and it is constructed by an iterative procedure which, at each iteration, adds the most informative training examples. Moreover, the comparator adopts a connectionist architecture that is particularly suited for implementing a preference function. We also prove that such an architecture has the universal approximation property and can implement a wide class of functions. Finally, the proposed algorithm is evaluated on the LETOR dataset showing promising performances in comparison with other state of the art algorithms.
* The 31st Annual International ACM SIGIR Conference (SIGIR 2008) - Workshop: Learning to Rank for Information Retrieval (LR4IR), Singapore, July 20-24 2008 - ISBN:978-16-05581-64-4
Logic Explained Networks
Aug 11, 2021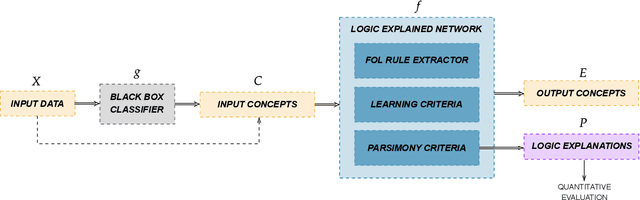

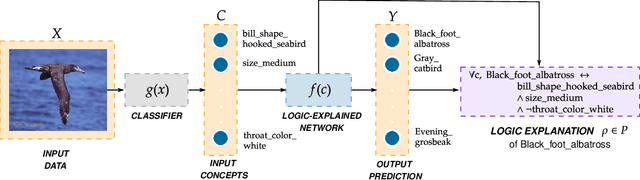

The large and still increasing popularity of deep learning clashes with a major limit of neural network architectures, that consists in their lack of capability in providing human-understandable motivations of their decisions. In situations in which the machine is expected to support the decision of human experts, providing a comprehensible explanation is a feature of crucial importance. The language used to communicate the explanations must be formal enough to be implementable in a machine and friendly enough to be understandable by a wide audience. In this paper, we propose a general approach to Explainable Artificial Intelligence in the case of neural architectures, showing how a mindful design of the networks leads to a family of interpretable deep learning models called Logic Explained Networks (LENs). LENs only require their inputs to be human-understandable predicates, and they provide explanations in terms of simple First-Order Logic (FOL) formulas involving such predicates. LENs are general enough to cover a large number of scenarios. Amongst them, we consider the case in which LENs are directly used as special classifiers with the capability of being explainable, or when they act as additional networks with the role of creating the conditions for making a black-box classifier explainable by FOL formulas. Despite supervised learning problems are mostly emphasized, we also show that LENs can learn and provide explanations in unsupervised learning settings. Experimental results on several datasets and tasks show that LENs may yield better classifications than established white-box models, such as decision trees and Bayesian rule lists, while providing more compact and meaningful explanations.
Learning Representations for Sub-Symbolic Reasoning
Jun 01, 2021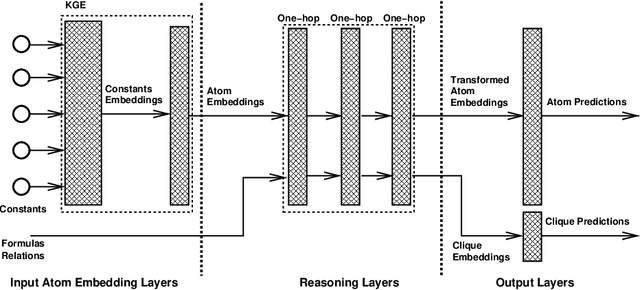

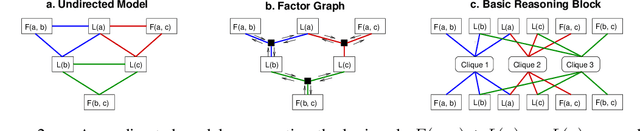
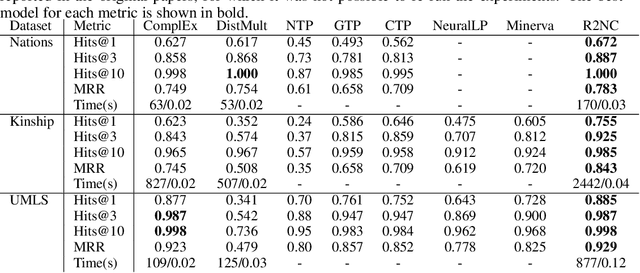
Neuro-symbolic methods integrate neural architectures, knowledge representation and reasoning. However, they have been struggling at both dealing with the intrinsic uncertainty of the observations and scaling to real world applications. This paper presents Relational Reasoning Networks (R2N), a novel end-to-end model that performs relational reasoning in the latent space of a deep learner architecture, where the representations of constants, ground atoms and their manipulations are learned in an integrated fashion. Unlike flat architectures like Knowledge Graph Embedders, which can only represent relations between entities, R2Ns define an additional computational structure, accounting for higher-level relations among the ground atoms. The considered relations can be explicitly known, like the ones defined by logic formulas, or defined as unconstrained correlations among groups of ground atoms. R2Ns can be applied to purely symbolic tasks or as a neuro-symbolic platform to integrate learning and reasoning in heterogeneous problems with both symbolic and feature-based represented entities. The proposed model bridges the gap between previous neuro-symbolic methods that have been either limited in terms of scalability or expressivity. The proposed methodology is shown to achieve state-of-the-art results in different experimental settings.
Generate and Revise: Reinforcement Learning in Neural Poetry
Feb 08, 2021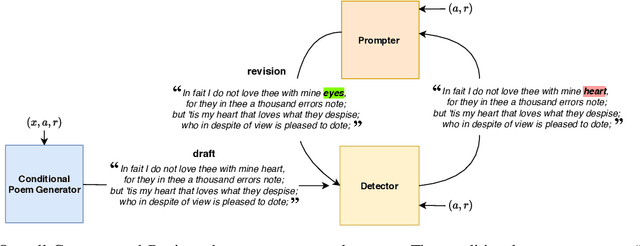

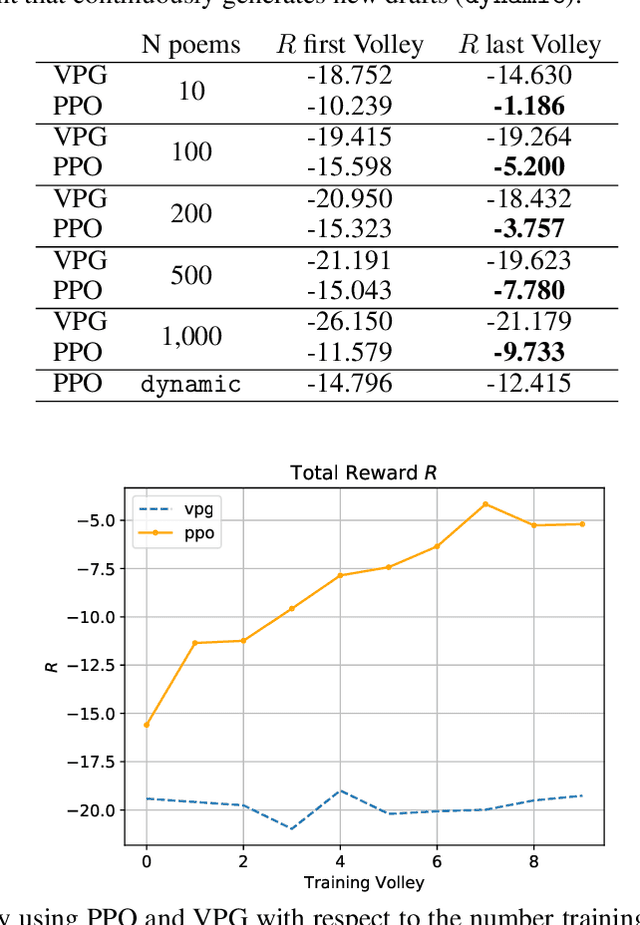

Writers, poets, singers usually do not create their compositions in just one breath. Text is revisited, adjusted, modified, rephrased, even multiple times, in order to better convey meanings, emotions and feelings that the author wants to express. Amongst the noble written arts, Poetry is probably the one that needs to be elaborated the most, since the composition has to formally respect predefined meter and rhyming schemes. In this paper, we propose a framework to generate poems that are repeatedly revisited and corrected, as humans do, in order to improve their overall quality. We frame the problem of revising poems in the context of Reinforcement Learning and, in particular, using Proximal Policy Optimization. Our model generates poems from scratch and it learns to progressively adjust the generated text in order to match a target criterion. We evaluate this approach in the case of matching a rhyming scheme, without having any information on which words are responsible of creating rhymes and on how to coherently alter the poem words. The proposed framework is general and, with an appropriate reward shaping, it can be applied to other text generation problems.
Vulgaris: Analysis of a Corpus for Middle-Age Varieties of Italian Language
Oct 12, 2020
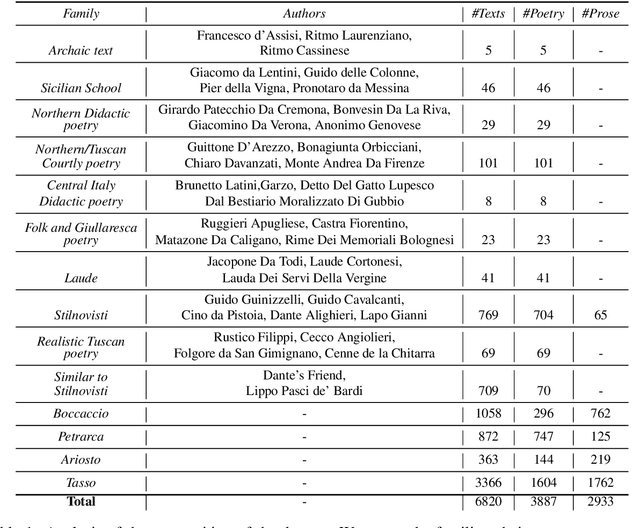
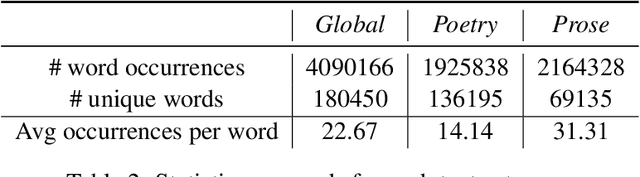

Italian is a Romance language that has its roots in Vulgar Latin. The birth of the modern Italian started in Tuscany around the 14th century, and it is mainly attributed to the works of Dante Alighieri, Francesco Petrarca and Giovanni Boccaccio, who are among the most acclaimed authors of the medieval age in Tuscany. However, Italy has been characterized by a high variety of dialects, which are often loosely related to each other, due to the past fragmentation of the territory. Italian has absorbed influences from many of these dialects, as also from other languages due to dominion of portions of the country by other nations, such as Spain and France. In this work we present Vulgaris, a project aimed at studying a corpus of Italian textual resources from authors of different regions, ranging in a time period between 1200 and 1600. Each composition is associated to its author, and authors are also grouped in families, i.e. sharing similar stylistic/chronological characteristics. Hence, the dataset is not only a valuable resource for studying the diachronic evolution of Italian and the differences between its dialects, but it is also useful to investigate stylistic aspects between single authors. We provide a detailed statistical analysis of the data, and a corpus-driven study in dialectology and diachronic varieties.