 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Mapping and Dual-Branch Reconstruction for 2D-3D Multimodal Industrial Anomaly Detection
Mar 04, 2026Multimodal industrial anomaly detection benefits from integrating RGB appearance with 3D surface geometry, yet existing \emph{unsupervised} approaches commonly rely on memory banks, teacher-student architectures, or fragile fusion schemes, limiting robustness under noisy depth, weak texture, or missing modalities. This paper introduces \textbf{CMDR-IAD}, a lightweight and modality-flexible unsupervised framework for reliable anomaly detection in 2D+3D multimodal as well as single-modality (2D-only or 3D-only) settings. \textbf{CMDR-IAD} combines bidirectional 2D$\leftrightarrow$3D cross-modal mapping to model appearance-geometry consistency with dual-branch reconstruction that independently captures normal texture and geometric structure. A two-part fusion strategy integrates these cues: a reliability-gated mapping anomaly highlights spatially consistent texture-geometry discrepancies, while a confidence-weighted reconstruction anomaly adaptively balances appearance and geometric deviations, yielding stable and precise anomaly localization even in depth-sparse or low-texture regions. On the MVTec 3D-AD benchmark, CMDR-IAD achieves state-of-the-art performance while operating without memory banks, reaching 97.3\% image-level AUROC (I-AUROC), 99.6\% pixel-level AUROC (P-AUROC), and 97.6\% AUPRO. On a real-world polyurethane cutting dataset, the 3D-only variant attains 92.6\% I-AUROC and 92.5\% P-AUROC, demonstrating strong effectiveness under practical industrial conditions. These results highlight the framework's robustness, modality flexibility, and the effectiveness of the proposed fusion strategies for industrial visual inspection. Our source code is available at https://github.com/ECGAI-Research/CMDR-IAD/
T2IBias: Uncovering Societal Bias Encoded in the Latent Space of Text-to-Image Generative Models
Nov 15, 2025Text-to-image (T2I) generative models are largely used in AI-powered real-world applications and value creation. However, their strategic deployment raises critical concerns for responsible AI management, particularly regarding the reproduction and amplification of race- and gender-related stereotypes that can undermine organizational ethics. In this work, we investigate whether such societal biases are systematically encoded within the pretrained latent spaces of state-of-the-art T2I models. We conduct an empirical study across the five most popular open-source models, using ten neutral, profession-related prompts to generate 100 images per profession, resulting in a dataset of 5,000 images evaluated by diverse human assessors representing different races and genders. We demonstrate that all five models encode and amplify pronounced societal skew: caregiving and nursing roles are consistently feminized, while high-status professions such as corporate CEO, politician, doctor, and lawyer are overwhelmingly represented by males and mostly White individuals. We further identify model-specific patterns, such as QWEN-Image's near-exclusive focus on East Asian outputs, Kandinsky's dominance of White individuals, and SDXL's comparatively broader but still biased distributions. These results provide critical insights for AI project managers and practitioners, enabling them to select equitable AI models and customized prompts that generate images in alignment with the principles of responsible AI. We conclude by discussing the risks of these biases and proposing actionable strategies for bias mitigation in building responsible GenAI systems. The code and Data Repository: https://github.com/Sufianlab/T2IBias
Real-Time Human Fall Detection using a Lightweight Pose Estimation Technique
Jan 03, 2024The elderly population is increasing rapidly around the world. There are no enough caretakers for them. Use of AI-based in-home medical care systems is gaining momentum due to this. Human fall detection is one of the most important tasks of medical care system for the aged people. Human fall is a common problem among elderly people. Detection of a fall and providing medical help as early as possible is very important to reduce any further complexity. The chances of death and other medical complications can be reduced by detecting and providing medical help as early as possible after the fall. There are many state-of-the-art fall detection techniques available these days, but the majority of them need very high computing power. In this paper, we proposed a lightweight and fast human fall detection system using pose estimation. We used `Movenet' for human joins key-points extraction. Our proposed method can work in real-time on any low-computing device with any basic camera. All computation can be processed locally, so there is no problem of privacy of the subject. We used two datasets `GMDCSA' and `URFD' for the experiment. We got the sensitivity value of 0.9375 and 0.9167 for the dataset `GMDCSA' and `URFD' respectively. The source code and the dataset GMDCSA of our work are available online to access.
Vision-based Human Fall Detection Systems using Deep Learning: A Review
Jul 22, 2022
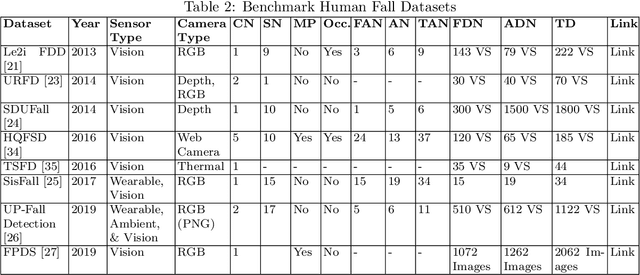


Human fall is one of the very critical health issues, especially for elders and disabled people living alone. The number of elder populations is increasing steadily worldwide. Therefore, human fall detection is becoming an effective technique for assistive living for those people. For assistive living, deep learning and computer vision have been used largely. In this review article, we discuss deep learning (DL)-based state-of-the-art non-intrusive (vision-based) fall detection techniques. We also present a survey on fall detection benchmark datasets. For a clear understanding, we briefly discuss different metrics which are used to evaluate the performance of the fall detection systems. This article also gives a future direction on vision-based human fall detection techniques.