 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSphere-Depth: A Benchmark for Depth Estimation Methods with Varying Spherical Camera Orientations
Apr 25, 2026Reliable depth estimation from spherical images is crucial for 360° vision in robotic navigation and immersive scene understanding. However, the onboard spherical camera can experience unintentional pose variations in real-world robotic platforms that, along with the geometric distortions inherent in equirectangular projections, significantly impact the effectiveness of depth estimation. To study this issue, a novel public benchmark, called Sphere-Depth, is introduced to systematically evaluate the robustness of monocular depth estimation models from equirectangular images in a reproducible way. Camera pose perturbations are simulated and used to assess the performance of a popular perspective-based model, Depth Anything, and of spherical-aware models such as Depth Anywhere, ACDNet, Bifuse++, and SliceNet. Furthermore, to ensure meaningful evaluation across models, a depth calibration-based error protocol is proposed to convert predicted relative depth values into metric depth values using supervised learned scaling factors for each model. Experiments show that even models explicitly designed to process spherical images exhibit substantial performance degradation when variations in the camera pose are observed with respect to the canonical pose. The full benchmark, evaluation protocol, and dataset splits are made publicly available at: https://github.com/sgazzeh/Sphere_depth
* Preprint
Learn&Drop: Fast Learning of CNNs based on Layer Dropping
Apr 25, 2026This paper proposes a new method to improve the training efficiency of deep convolutional neural networks. During training, the method evaluates scores to measure how much each layer's parameters change and whether the layer will continue learning or not. Based on these scores, the network is scaled down such that the number of parameters to be learned is reduced, yielding a speed up in training. Unlike state-of-the-art methods that try to compress the network to be used in the inference phase or to limit the number of operations performed in the backpropagation phase, the proposed method is novel in that it focuses on reducing the number of operations performed by the network in the forward propagation during training. The proposed training strategy has been validated on two widely used architecture families: VGG and ResNet. Experiments on MNIST, CIFAR-10 and Imagenette show that, with the proposed method, the training time of the models is more than halved without significantly impacting accuracy. The FLOPs reduction in the forward propagation during training ranges from 17.83\% for VGG-11 to 83.74\% for ResNet-152. These results demonstrate the effectiveness of the proposed technique in speeding up learning of CNNs. The technique will be especially useful in applications where fine-tuning or online training of convolutional models is required, for instance because data arrive sequentially.
* Preprint. Paper accepted to Springer Neural Computing and Applications
The Text Classification Pipeline: Starting Shallow going Deeper
Dec 30, 2024



Text Classification (TC) stands as a cornerstone within the realm of Natural Language Processing (NLP), particularly when viewed through the lens of computer science and engineering. The past decade has seen deep learning revolutionize TC, propelling advancements in text retrieval, categorization, information extraction, and summarization. The scholarly literature is rich with datasets, models, and evaluation criteria, with English being the predominant language of focus, despite studies involving Arabic, Chinese, Hindi, and others. The efficacy of TC models relies heavily on their ability to capture intricate textual relationships and nonlinear correlations, necessitating a comprehensive examination of the entire TC pipeline. This monograph provides an in-depth exploration of the TC pipeline, with a particular emphasis on evaluating the impact of each component on the overall performance of TC models. The pipeline includes state-of-the-art datasets, text preprocessing techniques, text representation methods, classification models, evaluation metrics, current results and future trends. Each chapter meticulously examines these stages, presenting technical innovations and significant recent findings. The work critically assesses various classification strategies, offering comparative analyses, examples, case studies, and experimental evaluations. These contributions extend beyond a typical survey, providing a detailed and insightful exploration of TC.
Ensemble of Hankel Matrices for Face Emotion Recognition
Jul 14, 2015
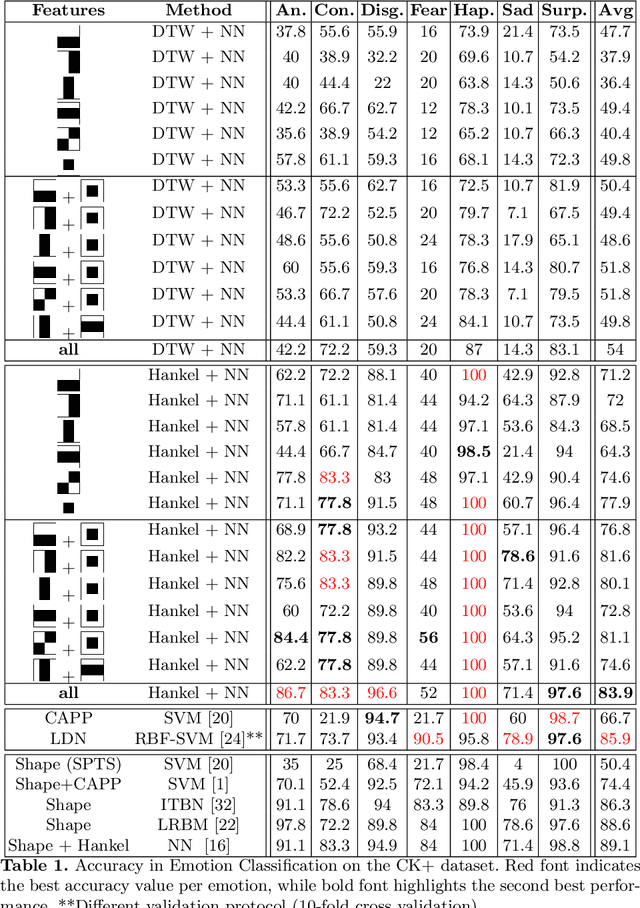
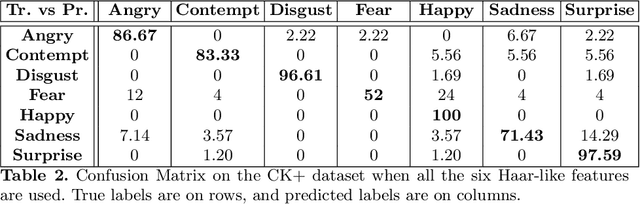
In this paper, a face emotion is considered as the result of the composition of multiple concurrent signals, each corresponding to the movements of a specific facial muscle. These concurrent signals are represented by means of a set of multi-scale appearance features that might be correlated with one or more concurrent signals. The extraction of these appearance features from a sequence of face images yields to a set of time series. This paper proposes to use the dynamics regulating each appearance feature time series to recognize among different face emotions. To this purpose, an ensemble of Hankel matrices corresponding to the extracted time series is used for emotion classification within a framework that combines nearest neighbor and a majority vote schema. Experimental results on a public available dataset shows that the adopted representation is promising and yields state-of-the-art accuracy in emotion classification.
Using Hankel Matrices for Dynamics-based Facial Emotion Recognition and Pain Detection
Jun 16, 2015
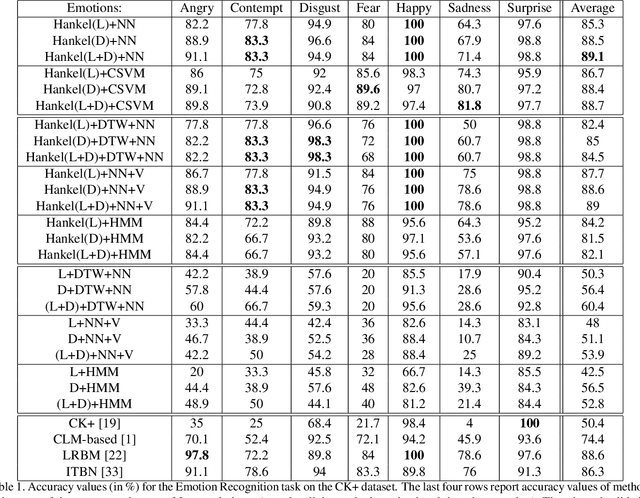
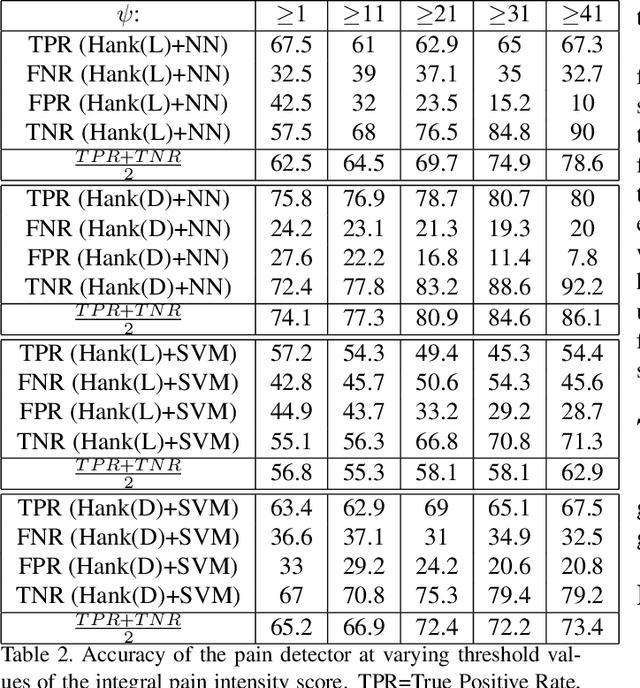
This paper proposes a new approach to model the temporal dynamics of a sequence of facial expressions. To this purpose, a sequence of Face Image Descriptors (FID) is regarded as the output of a Linear Time Invariant (LTI) system. The temporal dynamics of such sequence of descriptors are represented by means of a Hankel matrix. The paper presents different strategies to compute dynamics-based representation of a sequence of FID, and reports classification accuracy values of the proposed representations within different standard classification frameworks. The representations have been validated in two very challenging application domains: emotion recognition and pain detection. Experiments on two publicly available benchmarks and comparison with state-of-the-art approaches demonstrate that the dynamics-based FID representation attains competitive performance when off-the-shelf classification tools are adopted.