 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn&Drop: Fast Learning of CNNs based on Layer Dropping
Apr 25, 2026This paper proposes a new method to improve the training efficiency of deep convolutional neural networks. During training, the method evaluates scores to measure how much each layer's parameters change and whether the layer will continue learning or not. Based on these scores, the network is scaled down such that the number of parameters to be learned is reduced, yielding a speed up in training. Unlike state-of-the-art methods that try to compress the network to be used in the inference phase or to limit the number of operations performed in the backpropagation phase, the proposed method is novel in that it focuses on reducing the number of operations performed by the network in the forward propagation during training. The proposed training strategy has been validated on two widely used architecture families: VGG and ResNet. Experiments on MNIST, CIFAR-10 and Imagenette show that, with the proposed method, the training time of the models is more than halved without significantly impacting accuracy. The FLOPs reduction in the forward propagation during training ranges from 17.83\% for VGG-11 to 83.74\% for ResNet-152. These results demonstrate the effectiveness of the proposed technique in speeding up learning of CNNs. The technique will be especially useful in applications where fine-tuning or online training of convolutional models is required, for instance because data arrive sequentially.
* Preprint. Paper accepted to Springer Neural Computing and Applications
One-Step Time-Dependent Future Video Frame Prediction with a Convolutional Encoder-Decoder Neural Network
Jul 24, 2017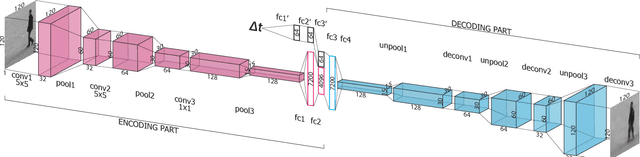
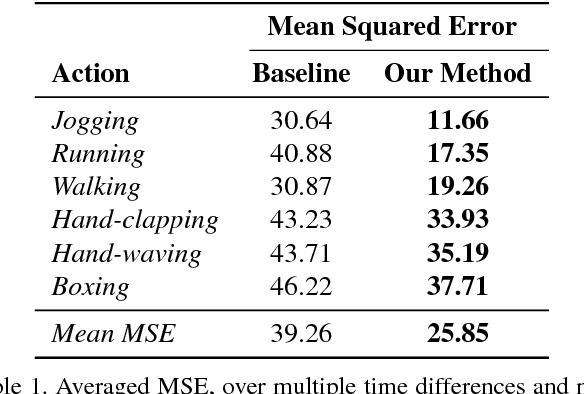


There is an inherent need for autonomous cars, drones, and other robots to have a notion of how their environment behaves and to anticipate changes in the near future. In this work, we focus on anticipating future appearance given the current frame of a video. Existing work focuses on either predicting the future appearance as the next frame of a video, or predicting future motion as optical flow or motion trajectories starting from a single video frame. This work stretches the ability of CNNs (Convolutional Neural Networks) to predict an anticipation of appearance at an arbitrarily given future time, not necessarily the next video frame. We condition our predicted future appearance on a continuous time variable that allows us to anticipate future frames at a given temporal distance, directly from the input video frame. We show that CNNs can learn an intrinsic representation of typical appearance changes over time and successfully generate realistic predictions at a deliberate time difference in the near future.