 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Improving the Evaluation of Visual Attention Models: a Crowdsourcing Approach
Feb 11, 2020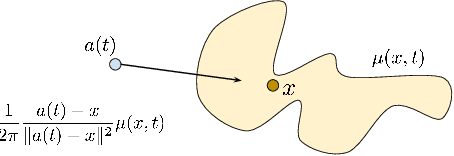
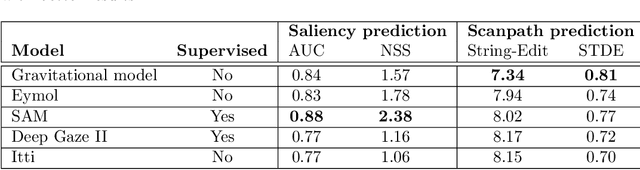
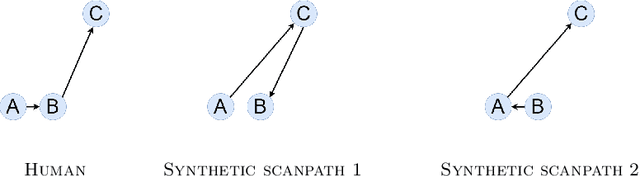

Human visual attention is a complex phenomenon. A computational modeling of this phenomenon must take into account where people look in order to evaluate which are the salient locations (spatial distribution of the fixations), when they look in those locations to understand the temporal development of the exploration (temporal order of the fixations), and how they move from one location to another with respect to the dynamics of the scene and the mechanics of the eyes (dynamics). State-of-the-art models focus on learning saliency maps from human data, a process that only takes into account the spatial component of the phenomenon and ignore its temporal and dynamical counterparts. In this work we focus on the evaluation methodology of models of human visual attention. We underline the limits of the current metrics for saliency prediction and scanpath similarity, and we introduce a statistical measure for the evaluation of the dynamics of the simulated eye movements. While deep learning models achieve astonishing performance in saliency prediction, our analysis shows their limitations in capturing the dynamics of the process. We find that unsupervised gravitational models, despite of their simplicity, outperform all competitors. Finally, exploiting a crowd-sourcing platform, we present a study aimed at evaluating how strongly the scanpaths generated with the unsupervised gravitational models appear plausible to naive and expert human observers.
Relational Neural Machines
Feb 06, 2020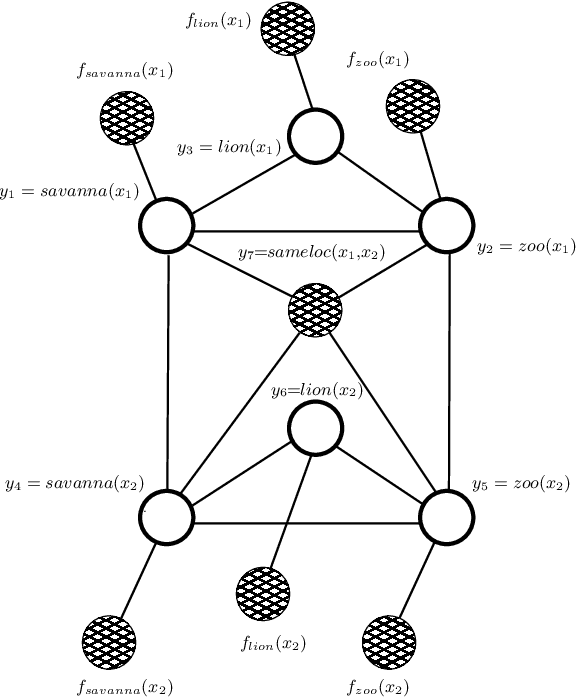


Deep learning has been shown to achieve impressive results in several tasks where a large amount of training data is available. However, deep learning solely focuses on the accuracy of the predictions, neglecting the reasoning process leading to a decision, which is a major issue in life-critical applications. Probabilistic logic reasoning allows to exploit both statistical regularities and specific domain expertise to perform reasoning under uncertainty, but its scalability and brittle integration with the layers processing the sensory data have greatly limited its applications. For these reasons, combining deep architectures and probabilistic logic reasoning is a fundamental goal towards the development of intelligent agents operating in complex environments. This paper presents Relational Neural Machines, a novel framework allowing to jointly train the parameters of the learners and of a First--Order Logic based reasoner. A Relational Neural Machine is able to recover both classical learning from supervised data in case of pure sub-symbolic learning, and Markov Logic Networks in case of pure symbolic reasoning, while allowing to jointly train and perform inference in hybrid learning tasks. Proper algorithmic solutions are devised to make learning and inference tractable in large-scale problems. The experiments show promising results in different relational tasks.
Backprop Diffusion is Biologically Plausible
Dec 10, 2019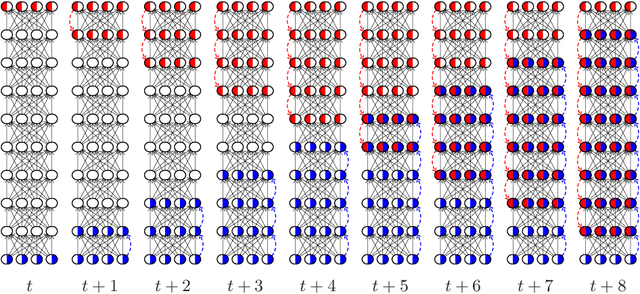


The Backpropagation algorithm relies on the abstraction of using a neural model that gets rid of the notion of time, since the input is mapped instantaneously to the output. In this paper, we claim that this abstraction of ignoring time, along with the abrupt input changes that occur when feeding the training set, are in fact the reasons why, in some papers, Backprop biological plausibility is regarded as an arguable issue. We show that as soon as a deep feedforward network operates with neurons with time-delayed response, the backprop weight update turns out to be the basic equation of a biologically plausible diffusion process based on forward-backward waves. We also show that such a process very well approximates the gradient for inputs that are not too fast with respect to the depth of the network. These remarks somewhat disclose the diffusion process behind the backprop equation and leads us to interpret the corresponding algorithm as a degeneration of a more general diffusion process that takes place also in neural networks with cyclic connections.
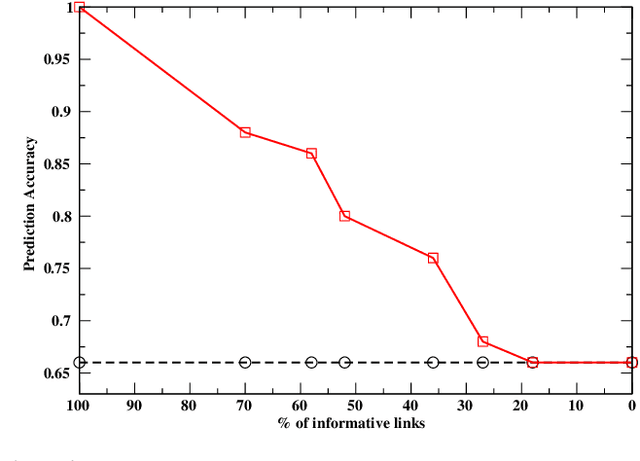
Discrete and Continuous Deep Residual Learning Over Graphs
Nov 26, 2019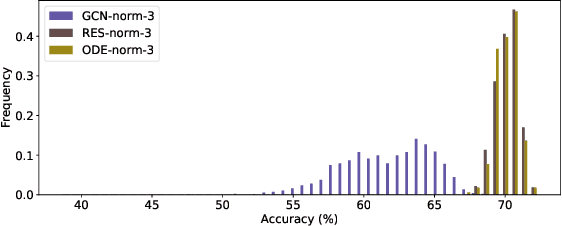
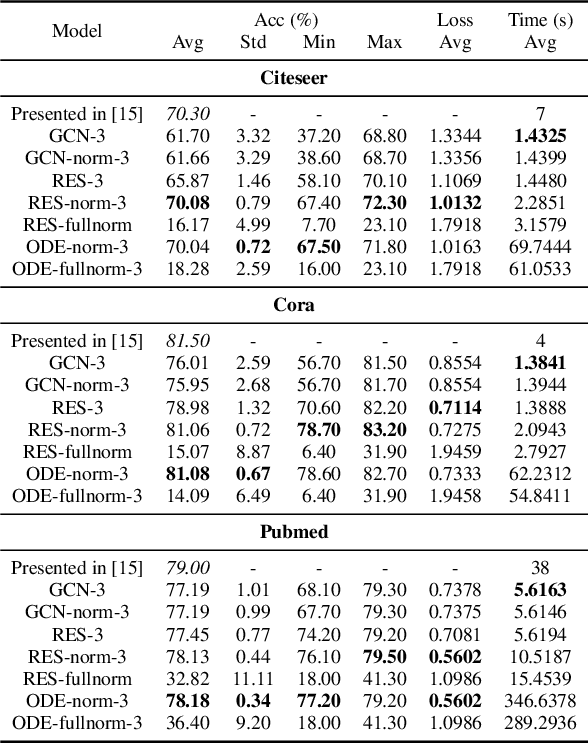
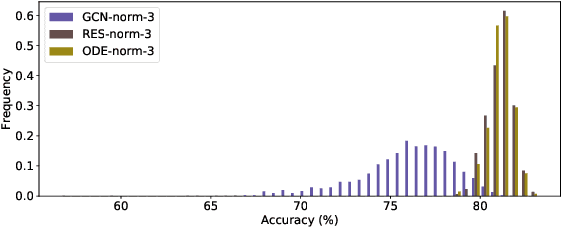
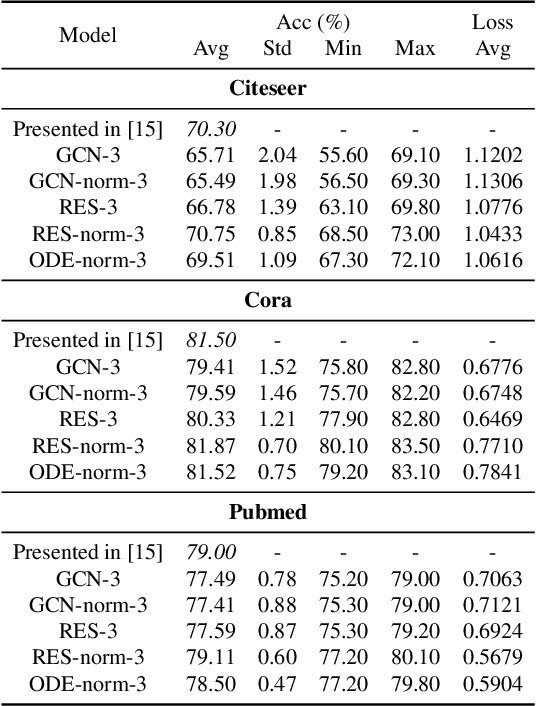
In this paper we propose the use of continuous residual modules for graph kernels in Graph Neural Networks. We show how both discrete and continuous residual layers allow for more robust training, being that continuous residual layers are those which are applied by integrating through an Ordinary Differential Equation (ODE) solver to produce their output. We experimentally show that these residuals achieve better results than the ones with non-residual modules when multiple layers are used, mitigating the low-pass filtering effect of GCN-based models. Finally, we apply and analyse the behaviour of these techniques and give pointers to how this technique can be useful in other domains by allowing more predictable behaviour under dynamic times of computation.
Jointly Learning to Detect Emotions and Predict Facebook Reactions
Sep 24, 2019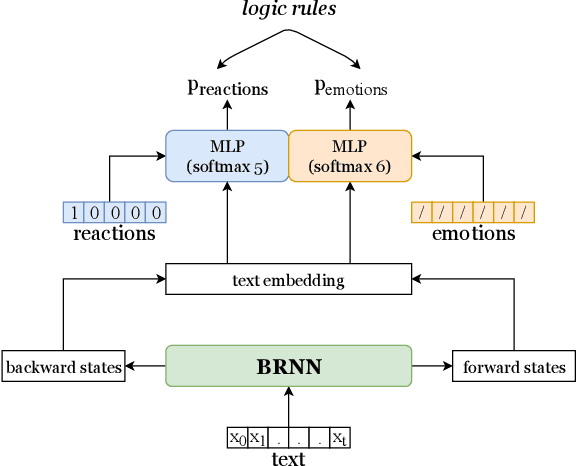
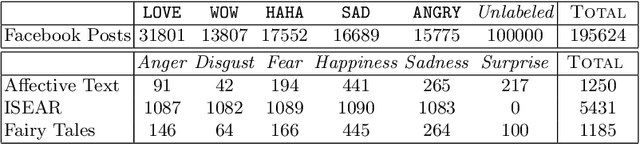
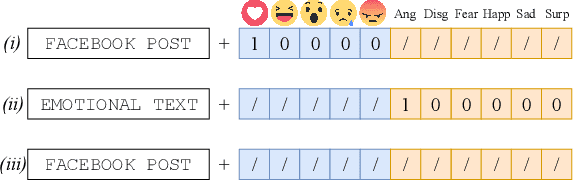
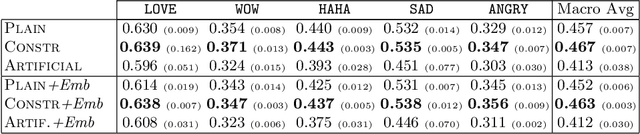
The growing ubiquity of Social Media data offers an attractive perspective for improving the quality of machine learning-based models in several fields, ranging from Computer Vision to Natural Language Processing. In this paper we focus on Facebook posts paired with reactions of multiple users, and we investigate their relationships with classes of emotions that are typically considered in the task of emotion detection. We are inspired by the idea of introducing a connection between reactions and emotions by means of First-Order Logic formulas, and we propose an end-to-end neural model that is able to jointly learn to detect emotions and predict Facebook reactions in a multi-task environment, where the logic formulas are converted into polynomial constraints. Our model is trained using a large collection of unsupervised texts together with data labeled with emotion classes and Facebook posts that include reactions. An extended experimental analysis that leverages a large collection of Facebook posts shows that the tasks of emotion classification and reaction prediction can both benefit from their interaction.
Learning Visual Features Under Motion Invariance
Sep 01, 2019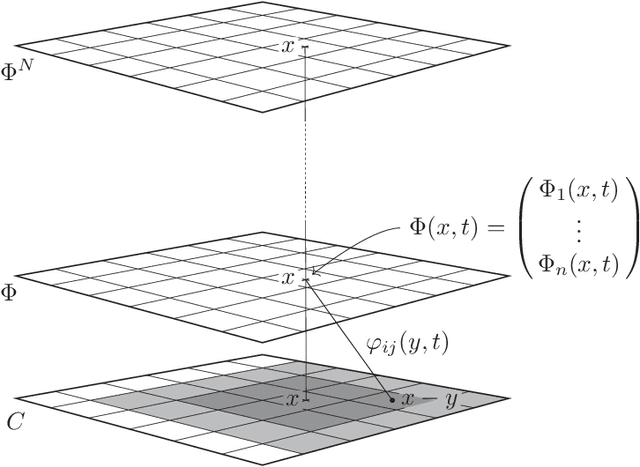

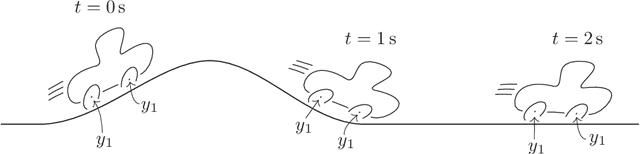
Humans are continuously exposed to a stream of visual data with a natural temporal structure. However, most successful computer vision algorithms work at image level, completely discarding the precious information carried by motion. In this paper, we claim that processing visual streams naturally leads to formulate the motion invariance principle, which enables the construction of a new theory of learning that originates from variational principles, just like in physics. Such principled approach is well suited for a discussion on a number of interesting questions that arise in vision, and it offers a well-posed computational scheme for the discovery of convolutional filters over the retina. Differently from traditional convolutional networks, which need massive supervision, the proposed theory offers a truly new scenario for the unsupervised processing of video signals, where features are extracted in a multi-layer architecture with motion invariance. While the theory enables the implementation of novel computer vision systems, it also sheds light on the role of information-based principles to drive possible biological solutions.
Learning and T-Norms Theory
Jul 26, 2019


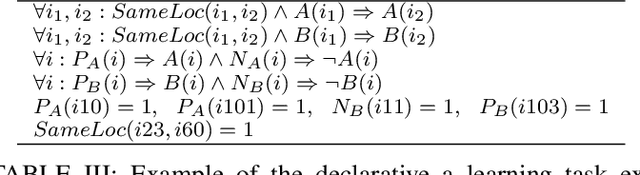
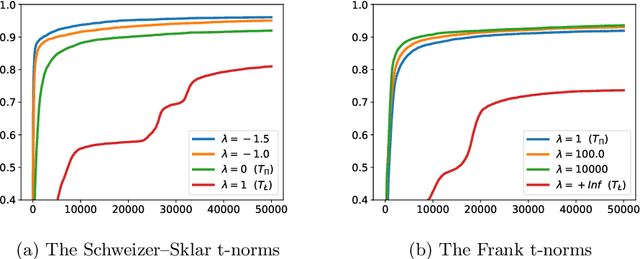
Deep learning has been shown to achieve impressive results in several domains like computer vision and natural language processing. Deep architectures are typically trained following a supervised scheme and, therefore, they rely on the availability of a large amount of labeled training data to effectively learn their parameters. Neuro-symbolic approaches have recently gained popularity to inject prior knowledge into a deep learner without requiring it to induce this knowledge from data. These approaches can potentially learn competitive solutions with a significant reduction of the amount of supervised data. A large class of neuro-symbolic approaches is based on First-Order Logic to represent prior knowledge, that is relaxed to a differentiable form using fuzzy logic. This paper shows that the loss function expressing these neuro-symbolic learning tasks can be unambiguously determined given the selection of a t-norm generator. When restricted to simple supervised learning, the presented theoretical apparatus provides a clean justification to the popular cross-entropy loss, that has been shown to provide faster convergence and to reduce the vanishing gradient problem in very deep structures. One advantage of the proposed learning formulation is that it can be extended to all the knowledge that can be represented by a neuro-symbolic method, and it allows the development of a novel class of loss functions, that the experimental results show to lead to faster convergence rates than other approaches previously proposed in the literature.
On the relation between Loss Functions and T-Norms
Jul 18, 2019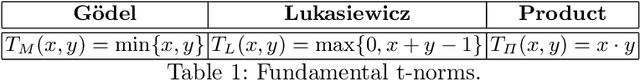
Deep learning has been shown to achieve impressive results in several domains like computer vision and natural language processing. A key element of this success has been the development of new loss functions, like the popular cross-entropy loss, which has been shown to provide faster convergence and to reduce the vanishing gradient problem in very deep structures. While the cross-entropy loss is usually justified from a probabilistic perspective, this paper shows an alternative and more direct interpretation of this loss in terms of t-norms and their associated generator functions, and derives a general relation between loss functions and t-norms. In particular, the presented work shows intriguing results leading to the development of a novel class of loss functions. These losses can be exploited in any supervised learning task and which could lead to faster convergence rates that the commonly employed cross-entropy loss.
On the Role of Time in Learning
Jul 14, 2019By and large the process of learning concepts that are embedded in time is regarded as quite a mature research topic. Hidden Markov models, recurrent neural networks are, amongst others, successful approaches to learning from temporal data. In this paper, we claim that the dominant approach minimizing appropriate risk functions defined over time by classic stochastic gradient might miss the deep interpretation of time given in other fields like physics. We show that a recent reformulation of learning according to the principle of Least Cognitive Action is better suited whenever time is involved in learning. The principle gives rise to a learning process that is driven by differential equations, that can somehow descrive the process within the same framework as other laws of nature.
Spatiotemporal Local Propagation
Jul 11, 2019
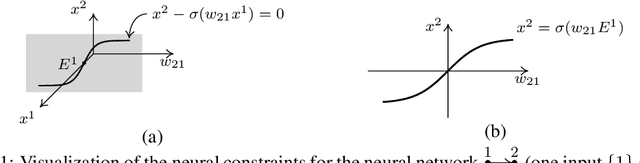
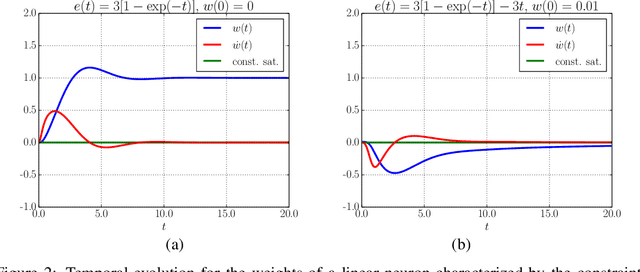
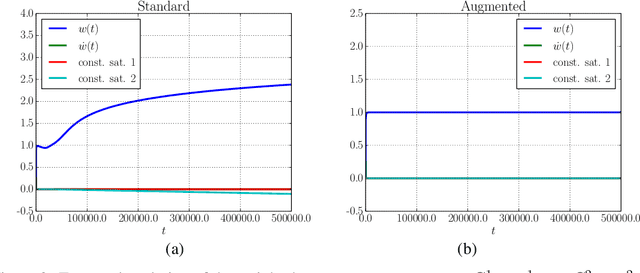
This paper proposes an in-depth re-thinking of neural computation that parallels apparently unrelated laws of physics, that are formulated in the variational framework of the least action principle. The theory holds for neural networks that are also based on any digraph, and the resulting computational scheme exhibits the intriguing property of being truly biologically plausible. The scheme, which is referred to as SpatioTemporal Local Propagation (STLP), is local in both space and time. Space locality comes from the expression of the network connections by an appropriate Lagrangian term, so as the corresponding computational scheme does not need the backpropagation (BP) of the error, while temporal locality is the outcome of the variational formulation of the problem. Overall, in addition to conquering the often invoked biological plausibility missed by BP, the locality in both space and time that arises from the proposed theory can neither be exhibited by Backpropagation Through Time (BPTT) nor by Real-Time Recurrent Learning (RTRL).