 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Powered Arabic Crossword Puzzle Generation for Educational Applications
Dec 03, 2023



This paper presents the first Arabic crossword puzzle generator driven by advanced AI technology. Leveraging cutting-edge large language models including GPT4, GPT3-Davinci, GPT3-Curie, GPT3-Babbage, GPT3-Ada, and BERT, the system generates distinctive and challenging clues. Based on a dataset comprising over 50,000 clue-answer pairs, the generator employs fine-tuning, few/zero-shot learning strategies, and rigorous quality-checking protocols to enforce the generation of high-quality clue-answer pairs. Importantly, educational crosswords contribute to enhancing memory, expanding vocabulary, and promoting problem-solving skills, thereby augmenting the learning experience through a fun and engaging approach, reshaping the landscape of traditional learning methods. The overall system can be exploited as a powerful educational tool that amalgamates AI and innovative learning techniques, heralding a transformative era for Arabic crossword puzzles and the intersection of technology and education.
The WebCrow French Crossword Solver
Nov 27, 2023Crossword puzzles are one of the most popular word games, played in different languages all across the world, where riddle style can vary significantly from one country to another. Automated crossword resolution is challenging, and typical solvers rely on large databases of previously solved crosswords. In this work, we extend WebCrow 2.0, an automatic crossword solver, to French, making it the first program for crossword solving in the French language. To cope with the lack of a large repository of clue-answer crossword data, WebCrow 2.0 exploits multiple modules, called experts, that retrieve candidate answers from heterogeneous resources, such as the web, knowledge graphs, and linguistic rules. We compared WebCrow's performance against humans in two different challenges. Despite the limited amount of past crosswords, French WebCrow was competitive, actually outperforming humans in terms of speed and accuracy, thus proving its capabilities to generalize to new languages.
Italian Crossword Generator: Enhancing Education through Interactive Word Puzzles
Nov 27, 2023Educational crosswords offer numerous benefits for students, including increased engagement, improved understanding, critical thinking, and memory retention. Creating high-quality educational crosswords can be challenging, but recent advances in natural language processing and machine learning have made it possible to use language models to generate nice wordplays. The exploitation of cutting-edge language models like GPT3-DaVinci, GPT3-Curie, GPT3-Babbage, GPT3-Ada, and BERT-uncased has led to the development of a comprehensive system for generating and verifying crossword clues. A large dataset of clue-answer pairs was compiled to fine-tune the models in a supervised manner to generate original and challenging clues from a given keyword. On the other hand, for generating crossword clues from a given text, Zero/Few-shot learning techniques were used to extract clues from the input text, adding variety and creativity to the puzzles. We employed the fine-tuned model to generate data and labeled the acceptability of clue-answer parts with human supervision. To ensure quality, we developed a classifier by fine-tuning existing language models on the labeled dataset. Conversely, to assess the quality of clues generated from the given text using zero/few-shot learning, we employed a zero-shot learning approach to check the quality of generated clues. The results of the evaluation have been very promising, demonstrating the effectiveness of the approach in creating high-standard educational crosswords that offer students engaging and rewarding learning experiences.
Multitask Kernel-based Learning with First-Order Logic Constraints
Nov 08, 2023In this paper we propose a general framework to integrate supervised and unsupervised examples with background knowledge expressed by a collection of first-order logic clauses into kernel machines. In particular, we consider a multi-task learning scheme where multiple predicates defined on a set of objects are to be jointly learned from examples, enforcing a set of FOL constraints on the admissible configurations of their values. The predicates are defined on the feature spaces, in which the input objects are represented, and can be either known a priori or approximated by an appropriate kernel-based learner. A general approach is presented to convert the FOL clauses into a continuous implementation that can deal with the outputs computed by the kernel-based predicates. The learning problem is formulated as a semi-supervised task that requires the optimization in the primal of a loss function that combines a fitting loss measure on the supervised examples, a regularization term, and a penalty term that enforces the constraints on both the supervised and unsupervised examples. Unfortunately, the penalty term is not convex and it can hinder the optimization process. However, it is possible to avoid poor solutions by using a two stage learning schema, in which the supervised examples are learned first and then the constraints are enforced.
* The 20th International Conference on Inductive Logic Programming (ILP 2010). Florence, Italy. June 27-30 2010
Graph Neural Networks for Topological Feature Extraction in ECG Classification
Nov 02, 2023The electrocardiogram (ECG) is a dependable instrument for assessing the function of the cardiovascular system. There has recently been much emphasis on precisely classifying ECGs. While ECG situations have numerous similarities, little attention has been paid to categorizing ECGs using graph neural networks. In this study, we offer three distinct techniques for classifying heartbeats using deep graph neural networks to classify the ECG signals accurately. We suggest using different methods to extract topological features from the ECG signal and then using a branch of the graph neural network named graph isomorphism network for classifying the ECGs. On the PTB Diagnostics data set, we tested the three proposed techniques. According to the findings, the three proposed techniques are capable of making arrhythmia classification predictions with the accuracy of 99.38, 98.76, and 91.93 percent, respectively.
Collectionless Artificial Intelligence
Sep 15, 2023By and large, the professional handling of huge data collections is regarded as a fundamental ingredient of the progress of machine learning and of its spectacular results in related disciplines, with a growing agreement on risks connected to the centralization of such data collections. This paper sustains the position that the time has come for thinking of new learning protocols where machines conquer cognitive skills in a truly human-like context centered on environmental interactions. This comes with specific restrictions on the learning protocol according to the collectionless principle, which states that, at each time instant, data acquired from the environment is processed with the purpose of contributing to update the current internal representation of the environment, and that the agent is not given the privilege of recording the temporal stream. Basically, there is neither permission to store the temporal information coming from the sensors, thus promoting the development of self-organized memorization skills at a more abstract level, instead of relying on bare storage to simulate learning dynamics that are typical of offline learning algorithms. This purposely extreme position is intended to stimulate the development of machines that learn to dynamically organize the information by following human-based schemes. The proposition of this challenge suggests developing new foundations on computational processes of learning and reasoning that might open the doors to a truly orthogonal competitive track on AI technologies that avoid data accumulation by design, thus offering a framework which is better suited concerning privacy issues, control and customizability. Finally, pushing towards massively distributed computation, the collectionless approach to AI will likely reduce the concentration of power in companies and governments, thus better facing geopolitical issues.
Continual Learning with Pretrained Backbones by Tuning in the Input Space
Jun 08, 2023The intrinsic difficulty in adapting deep learning models to non-stationary environments limits the applicability of neural networks to real-world tasks. This issue is critical in practical supervised learning settings, such as the ones in which a pre-trained model computes projections toward a latent space where different task predictors are sequentially learned over time. As a matter of fact, incrementally fine-tuning the whole model to better adapt to new tasks usually results in catastrophic forgetting, with decreasing performance over the past experiences and losing valuable knowledge from the pre-training stage. In this paper, we propose a novel strategy to make the fine-tuning procedure more effective, by avoiding to update the pre-trained part of the network and learning not only the usual classification head, but also a set of newly-introduced learnable parameters that are responsible for transforming the input data. This process allows the network to effectively leverage the pre-training knowledge and find a good trade-off between plasticity and stability with modest computational efforts, thus especially suitable for on-the-edge settings. Our experiments on four image classification problems in a continual learning setting confirm the quality of the proposed approach when compared to several fine-tuning procedures and to popular continual learning methods.
PARTIME: Scalable and Parallel Processing Over Time with Deep Neural Networks
Oct 17, 2022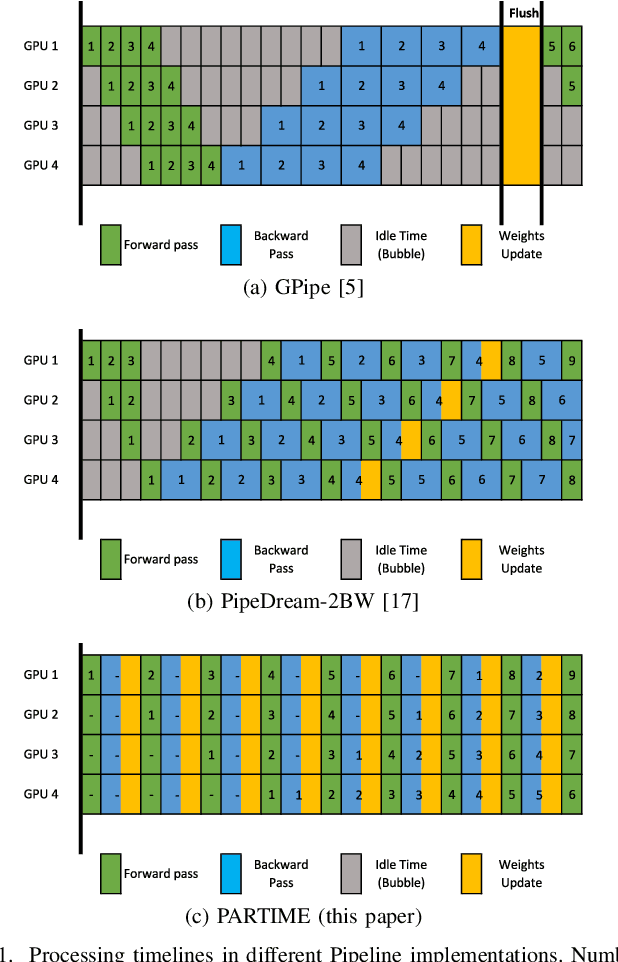


In this paper, we present PARTIME, a software library written in Python and based on PyTorch, designed specifically to speed up neural networks whenever data is continuously streamed over time, for both learning and inference. Existing libraries are designed to exploit data-level parallelism, assuming that samples are batched, a condition that is not naturally met in applications that are based on streamed data. Differently, PARTIME starts processing each data sample at the time in which it becomes available from the stream. PARTIME wraps the code that implements a feed-forward multi-layer network and it distributes the layer-wise processing among multiple devices, such as Graphics Processing Units (GPUs). Thanks to its pipeline-based computational scheme, PARTIME allows the devices to perform computations in parallel. At inference time this results in scaling capabilities that are theoretically linear with respect to the number of devices. During the learning stage, PARTIME can leverage the non-i.i.d. nature of the streamed data with samples that are smoothly evolving over time for efficient gradient computations. Experiments are performed in order to empirically compare PARTIME with classic non-parallel neural computations in online learning, distributing operations on up to 8 NVIDIA GPUs, showing significant speedups that are almost linear in the number of devices, mitigating the impact of the data transfer overhead.
Learning to Identify Drilling Defects in Turbine Blades with Single Stage Detectors
Aug 08, 2022
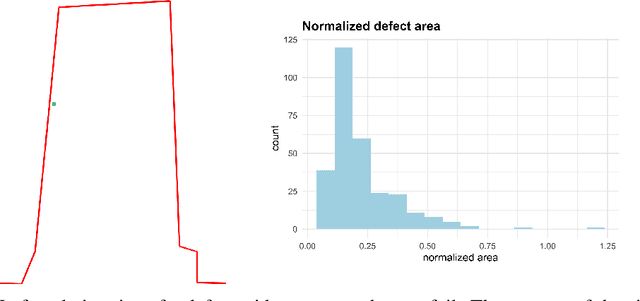
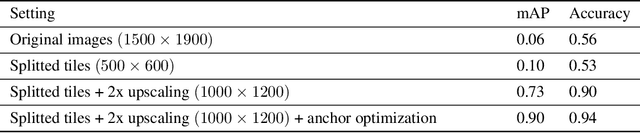
Nondestructive testing (NDT) is widely applied to defect identification of turbine components during manufacturing and operation. Operational efficiency is key for gas turbine OEM (Original Equipment Manufacturers). Automating the inspection process as much as possible, while minimizing the uncertainties involved, is thus crucial. We propose a model based on RetinaNet to identify drilling defects in X-ray images of turbine blades. The application is challenging due to the large image resolutions in which defects are very small and hardly captured by the commonly used anchor sizes, and also due to the small size of the available dataset. As a matter of fact, all these issues are pretty common in the application of Deep Learning-based object detection models to industrial defect data. We overcome such issues using open source models, splitting the input images into tiles and scaling them up, applying heavy data augmentation, and optimizing the anchor size and aspect ratios with a differential evolution solver. We validate the model with $3$-fold cross-validation, showing a very high accuracy in identifying images with defects. We also define a set of best practices which can help other practitioners overcome similar challenges.
Deep Learning to See: Towards New Foundations of Computer Vision
Jun 30, 2022The remarkable progress in computer vision over the last few years is, by and large, attributed to deep learning, fueled by the availability of huge sets of labeled data, and paired with the explosive growth of the GPU paradigm. While subscribing to this view, this book criticizes the supposed scientific progress in the field and proposes the investigation of vision within the framework of information-based laws of nature. Specifically, the present work poses fundamental questions about vision that remain far from understood, leading the reader on a journey populated by novel challenges resonating with the foundations of machine learning. The central thesis is that for a deeper understanding of visual computational processes, it is necessary to look beyond the applications of general purpose machine learning algorithms and focus instead on appropriate learning theories that take into account the spatiotemporal nature of the visual signal.