 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting on the Stiefel Manifold: When Does Adaptive Subspace Selection Help for Cross-Domain EEG Decoding?
May 29, 2026Cross-domain EEG decoding remains challenging despite advances in Riemannian deep learning: covariance matrices from different subjects occupy systematically distinct regions of the SPD manifold, yet existing domain adaptation methods either require target-domain calibration data or learn subject-specific components that cannot generalise across domains. We propose dynamic Stiefel routing: a pool of $K$ expert projection filters on the Stiefel manifold, each specialised for a different region of the SPD manifold, with each input covariance routed to the most appropriate filter via cross-attention, adapting the subspace projection per sample. A central finding is that this approach, implemented naively, provably collapses to ensemble averaging: when routing weights are uniform, the adaptive filter reduces exactly to an equal-contribution combination of experts, indistinguishable from a single fixed filter. Three structural properties break this degeneracy: a symmetric anchor $W_{\mathrm{base}} \in \mathrm{St}(n,k)$ that removes proximity bias among experts; a frozen domain-discriminative query encoder that decouples routing from task optimisation; and a decoupled key alignment loss that trains expert keys toward stable domain attractors. Together they produce the first genuinely committed and domain-structured routing on SPD manifolds, with consistent gains across three datasets: balanced accuracy improves from $0.773\to 0.823$, $0.757\to 0.809$, and $0.801\to 0.839$, with the alignment strategy determined automatically by a single data-driven rule and no dataset-specific hyperparameter search.
Improved Riemannian potato field: an Automatic Artifact Rejection Method for EEG
Sep 11, 2025



Electroencephalography (EEG) signal cleaning has long been a critical challenge in the research community. The presence of artifacts can significantly degrade EEG data quality, complicating analysis and potentially leading to erroneous interpretations. While various artifact rejection methods have been proposed, the gold standard remains manual visual inspection by human experts-a process that is time-consuming, subjective, and impractical for large-scale EEG studies. Existing techniques are often hindered by a strong reliance on manual hyperparameter tuning, sensitivity to outliers, and high computational costs. In this paper, we introduce the improved Riemannian Potato Field (iRPF), a fast and fully automated method for EEG artifact rejection that addresses key limitations of current approaches. We evaluate iRPF against several state-of-the-art artifact rejection methods, using two publicly available EEG databases, labeled for various artifact types, comprising 226 EEG recordings. Our results demonstrate that iRPF outperforms all competitors across multiple metrics, with gains of up to 22% in recall, 102% in specificity, 54% in precision, and 24% in F1-score, compared to Isolation Forest, Autoreject, Riemannian Potato, and Riemannian Potato Field, respectively. Statistical analysis confirmed the significance of these improvements (p < 0.001) with large effect sizes (Cohen's d > 0.8) in most comparisons. Additionally, on a typical EEG recording iRPF performs artifact cleaning in under 8 milliseconds per epoch using a standard laptop, highlighting its efficiency for large-scale EEG data processing and real-time applications. iRPF offers a robust and data-driven artifact rejection solution for high-quality EEG pre-processing in brain-computer interfaces and clinical neuroimaging applications.
The Riemannian Means Field Classifier for EEG-Based BCI Data
Apr 24, 2025A substantial amount of research has demonstrated the robustness and accuracy of the Riemannian minimum distance to mean (MDM) classifier for all kinds of EEG-based brain--computer interfaces (BCIs). This classifier is simple, fully deterministic, robust to noise, computationally efficient, and prone to transfer learning. Its training is very simple, requiring just the computation of a geometric mean of a symmetric positive-definite (SPD) matrix per class. We propose an improvement of the MDM involving a number of power means of SPD matrices instead of the sole geometric mean. By the analysis of 20 public databases, 10 for the motor-imagery BCI paradigm and 10 for the P300 BCI paradigm, comprising 587 individuals in total, we show that the proposed classifier clearly outperforms the MDM, approaching the state-of-the art in terms of performance while retaining the simplicity and the deterministic behavior. In order to promote reproducible research, our code will be released as open source.
Approximate Joint Diagonalization and Geometric Mean of Symmetric Positive Definite Matrices
May 26, 2015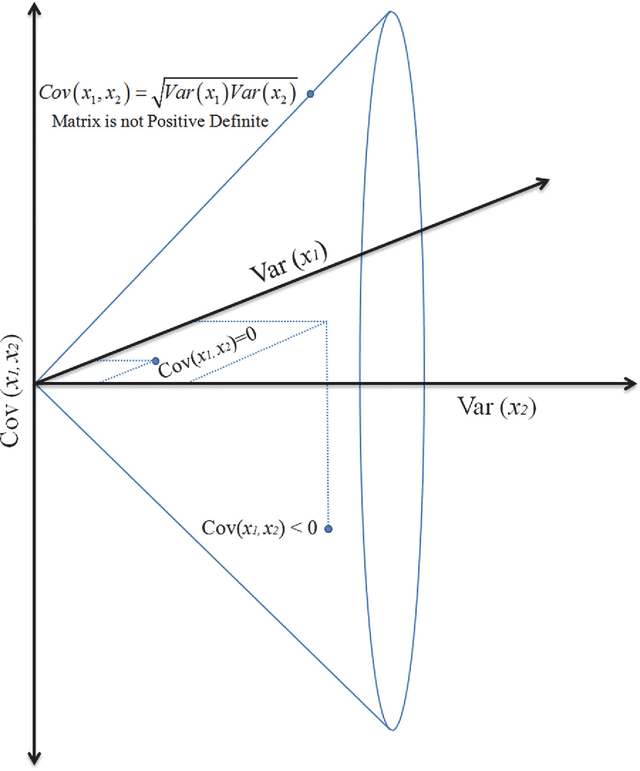


We explore the connection between two problems that have arisen independently in the signal processing and related fields: the estimation of the geometric mean of a set of symmetric positive definite (SPD) matrices and their approximate joint diagonalization (AJD). Today there is a considerable interest in estimating the geometric mean of a SPD matrix set in the manifold of SPD matrices endowed with the Fisher information metric. The resulting mean has several important invariance properties and has proven very useful in diverse engineering applications such as biomedical and image data processing. While for two SPD matrices the mean has an algebraic closed form solution, for a set of more than two SPD matrices it can only be estimated by iterative algorithms. However, none of the existing iterative algorithms feature at the same time fast convergence, low computational complexity per iteration and guarantee of convergence. For this reason, recently other definitions of geometric mean based on symmetric divergence measures, such as the Bhattacharyya divergence, have been considered. The resulting means, although possibly useful in practice, do not satisfy all desirable invariance properties. In this paper we consider geometric means of co-variance matrices estimated on high-dimensional time-series, assuming that the data is generated according to an instantaneous mixing model, which is very common in signal processing. We show that in these circumstances we can approximate the Fisher information geometric mean by employing an efficient AJD algorithm. Our approximation is in general much closer to the Fisher information geometric mean as compared to its competitors and verifies many invariance properties. Furthermore, convergence is guaranteed, the computational complexity is low and the convergence rate is quadratic. The accuracy of this new geometric mean approximation is demonstrated by means of simulations.
A Plug&Play P300 BCI Using Information Geometry
Aug 30, 2014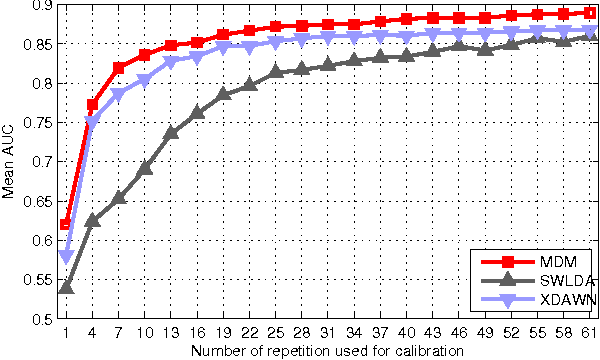
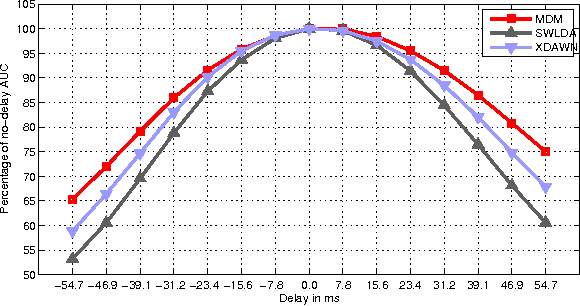
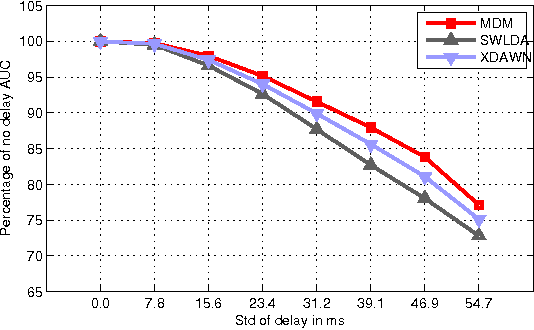
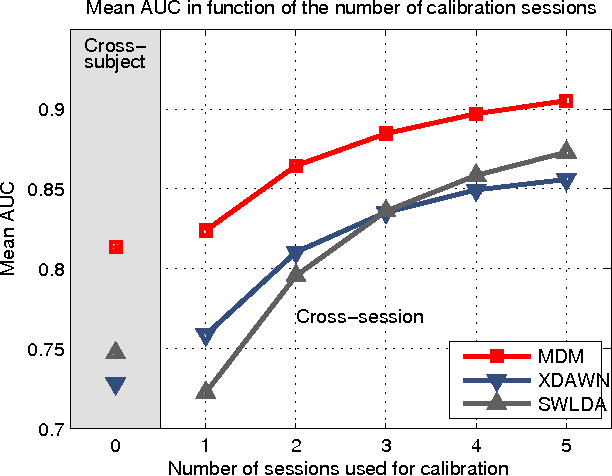
This paper presents a new classification methods for Event Related Potentials (ERP) based on an Information geometry framework. Through a new estimation of covariance matrices, this work extend the use of Riemannian geometry, which was previously limited to SMR-based BCI, to the problem of classification of ERPs. As compared to the state-of-the-art, this new method increases performance, reduces the number of data needed for the calibration and features good generalisation across sessions and subjects. This method is illustrated on data recorded with the P300-based game brain invaders. Finally, an online and adaptive implementation is described, where the BCI is initialized with generic parameters derived from a database and continuously adapt to the individual, allowing the user to play the game without any calibration while keeping a high accuracy.
Mixed-norm Regularization for Brain Decoding
Mar 14, 2014



This work investigates the use of mixed-norm regularization for sensor selection in Event-Related Potential (ERP) based Brain-Computer Interfaces (BCI). The classification problem is cast as a discriminative optimization framework where sensor selection is induced through the use of mixed-norms. This framework is extended to the multi-task learning situation where several similar classification tasks related to different subjects are learned simultaneously. In this case, multi-task learning helps in leveraging data scarcity issue yielding to more robust classifiers. For this purpose, we have introduced a regularizer that induces both sensor selection and classifier similarities. The different regularization approaches are compared on three ERP datasets showing the interest of mixed-norm regularization in terms of sensor selection. The multi-task approaches are evaluated when a small number of learning examples are available yielding to significant performance improvements especially for subjects performing poorly.