 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGP: Un algorithme de planification temps réel prenant en compte l'évolution dynamique du but
Oct 22, 2018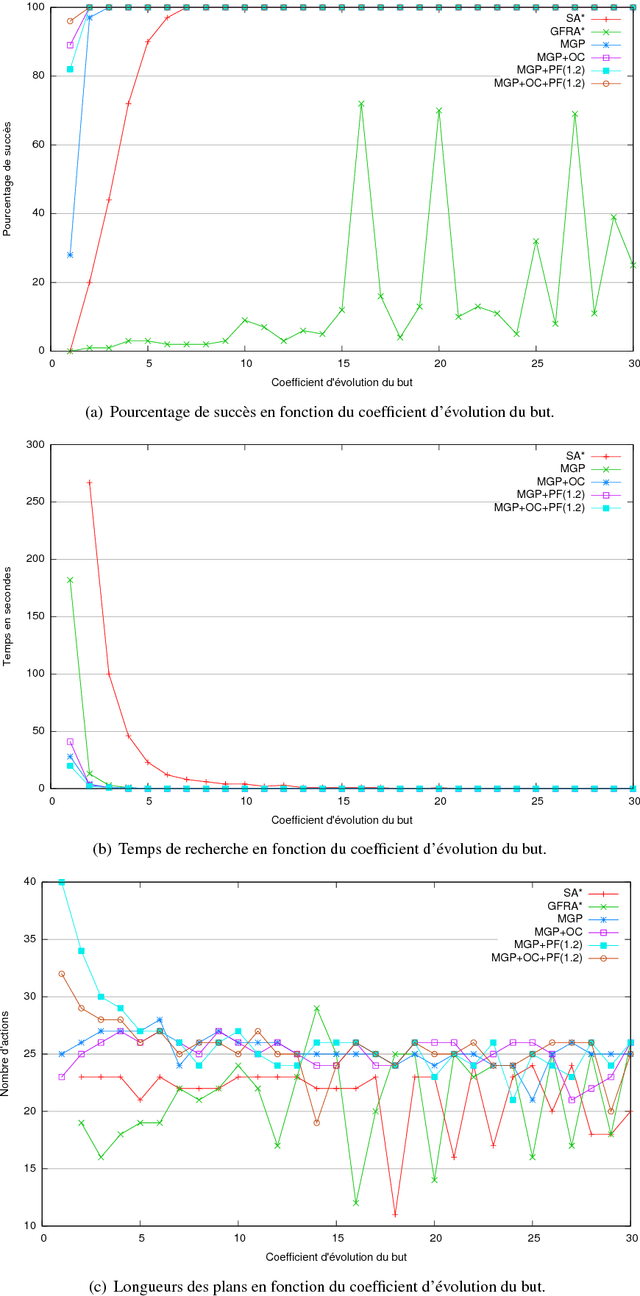
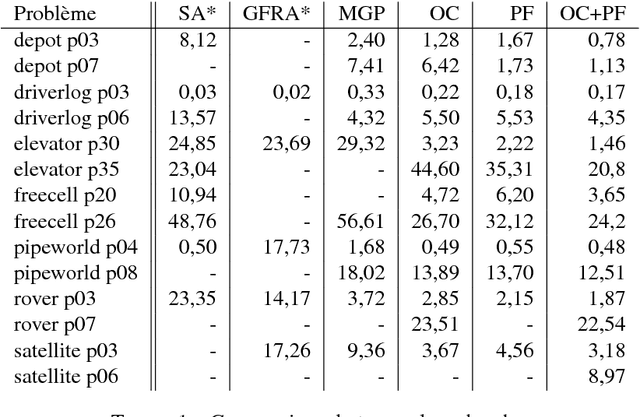
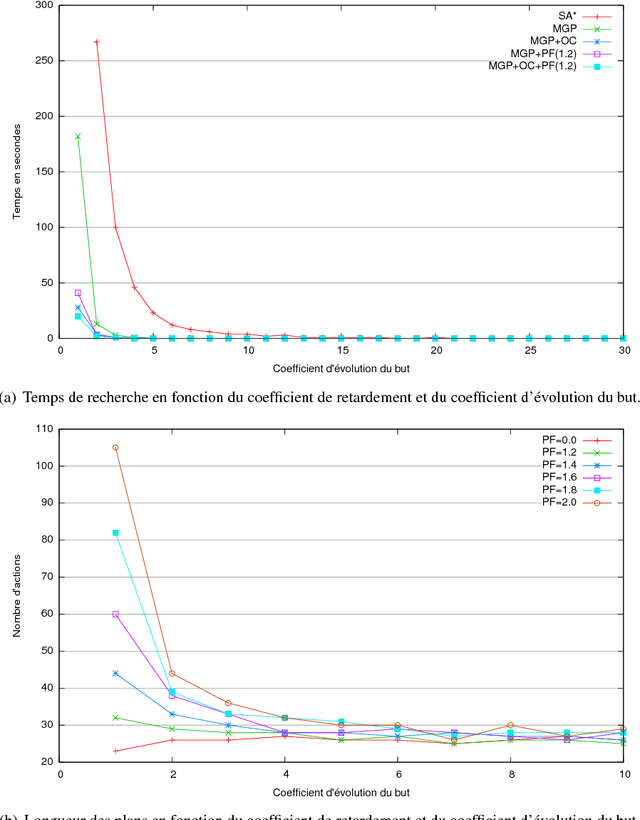
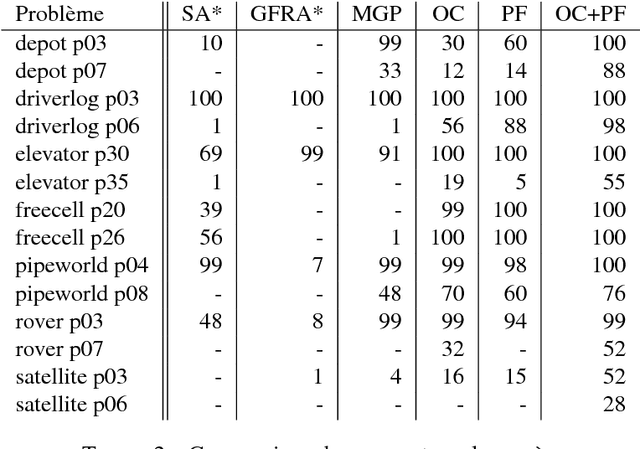
Devising intelligent robots or agents that interact with humans is a major challenge for artificial intelligence. In such contexts, agents must constantly adapt their decisions according to human activities and modify their goals. In this paper, we tackle this problem by introducing a novel planning approach, called Moving Goal Planning (MGP), to adapt plans to goal evolutions. This planning algorithm draws inspiration from Moving Target Search (MTS) algorithms. In order to limit the number of search iterations and to improve its efficiency, MGP delays as much as possible triggering new searches when the goal changes over time. To this purpose, MGP uses two strategies: Open Check (OC) that checks if the new goal is still in the current search tree and Plan Follow (PF) that estimates whether executing actions of the current plan brings MGP closer to the new goal. Moreover, MGP uses a parsimonious strategy to update incrementally the search tree at each new search that reduces the number of calls to the heuristic function and speeds up the search. Finally, we show evaluation results that demonstrate the effectiveness of our approach.
* in French
Planification en temps réel avec agenda de buts et sauts
Oct 22, 2018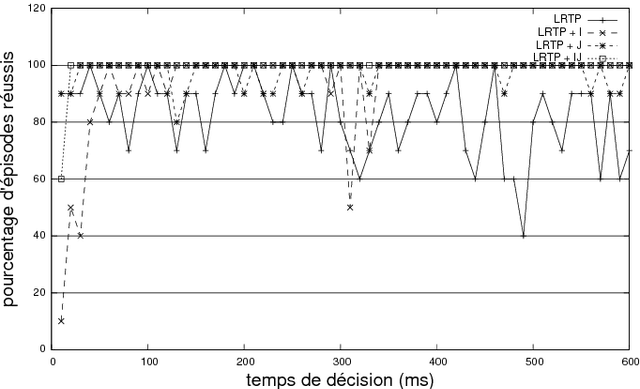
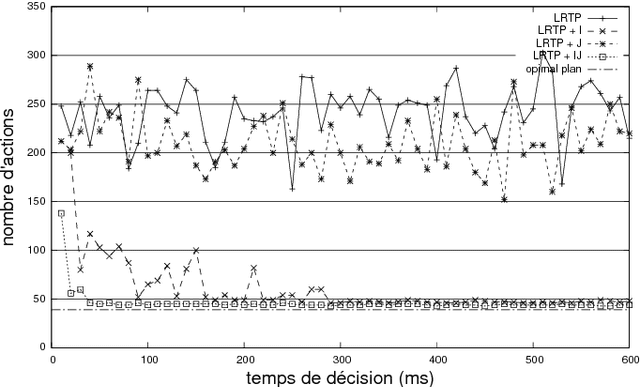
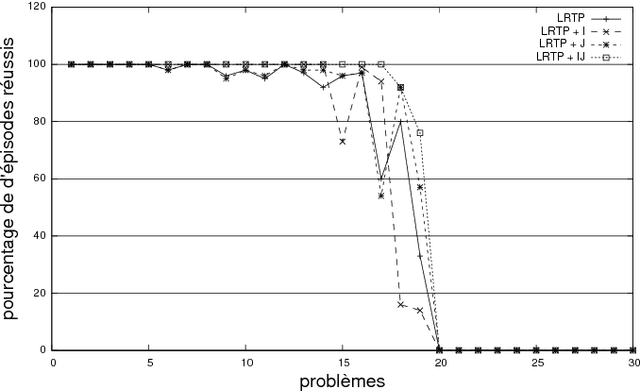
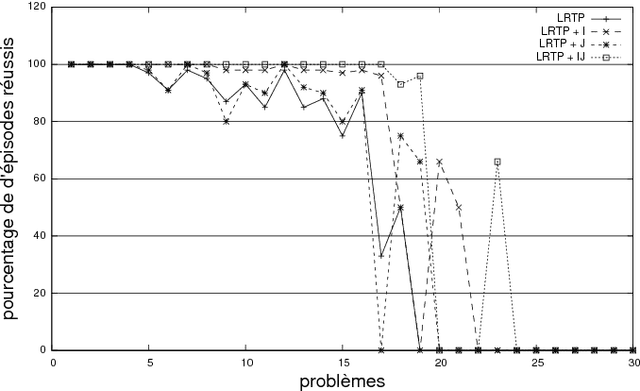
In the context of real-time planning, this paper investigates the contributions of two enhancements for selecting actions. First, the agenda-driven planning enhancement ranks relevant atomic goals and solves them incrementally in a best-first manner. Second, the committed jump enhancement commits a sequence of actions to be executed at the following time steps. To assess these two enhancements, we developed a real-time planning algorithm in which action selection can be driven by a goal-agenda, and committed jumps can be done. Experimental results, performed on classical planning problems, show that agenda-planning and committed jumps are clear advantages in the real-time context. Used simultaneously, they enable the planner to be several orders of magnitude faster and solution plans to be shorter.
* in French, Journ\'ees Francophones de Planification, D\'ecision, Apprentissage pour la conduite de syst\`emes, 2011
Mean-based Heuristic Search for Real-Time Planning
Oct 22, 2018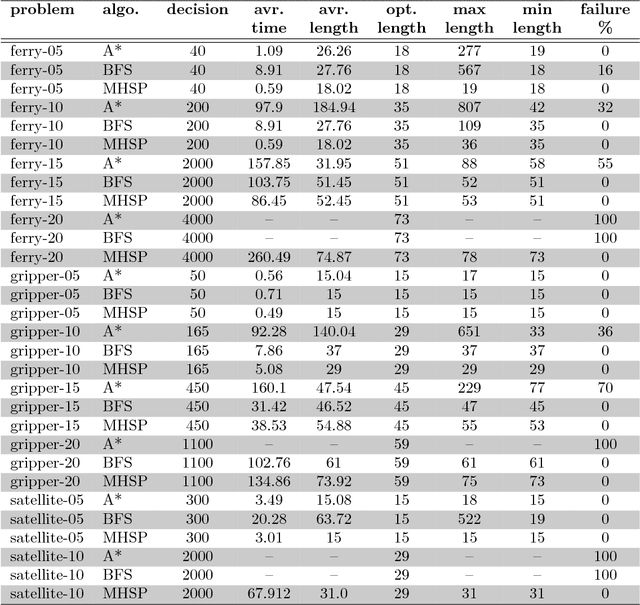
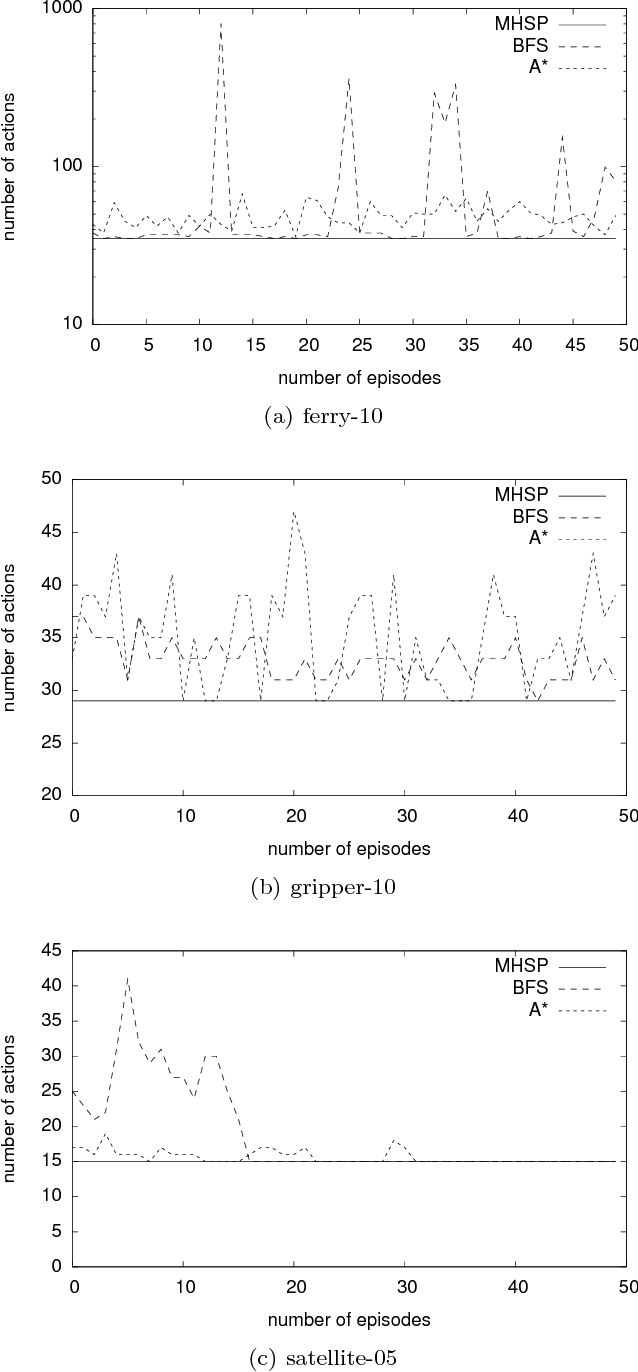
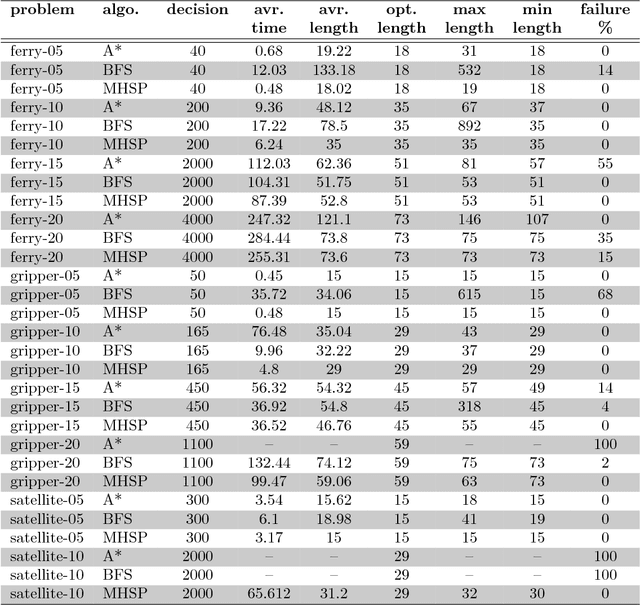
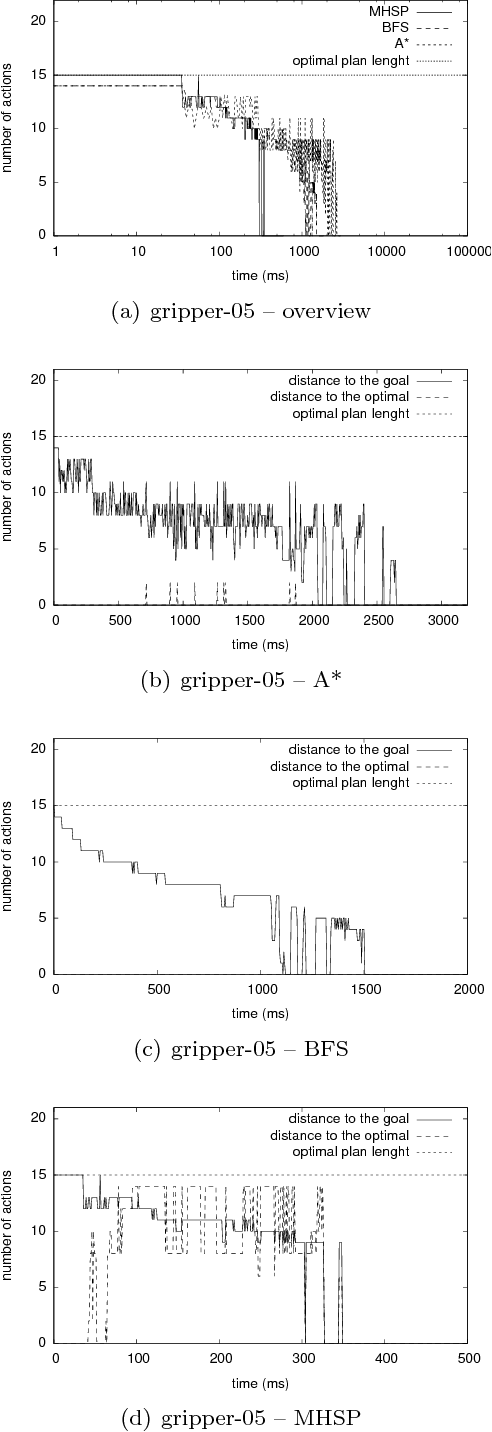
In this paper, we introduce a new heuristic search algorithm based on mean values for real-time planning, called MHSP. It consists in associating the principles of UCT, a bandit-based algorithm which gave very good results in computer games, and especially in Computer Go, with heuristic search in order to obtain a real-time planner in the context of classical planning. MHSP is evaluated on different planning problems and compared to existing algorithms performing on-line search and learning. Besides, our results highlight the capacity of MHSP to return plans in a real-time manner which tend to an optimal plan over the time which is faster and of better quality compared to existing algorithms in the literature.
Hedging Algorithms and Repeated Matrix Games
Oct 15, 2018

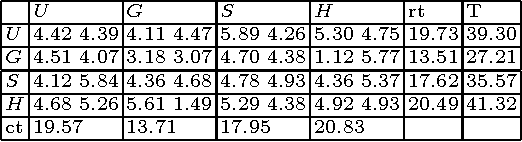
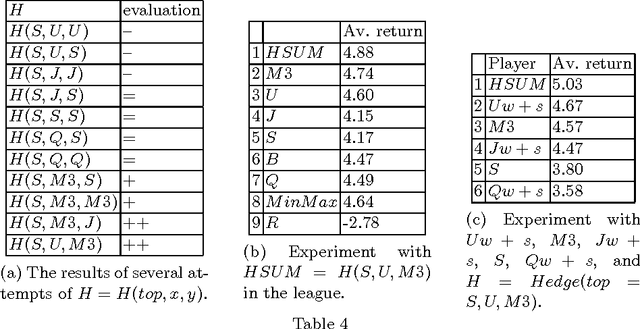
Playing repeated matrix games (RMG) while maximizing the cumulative returns is a basic method to evaluate multi-agent learning (MAL) algorithms. Previous work has shown that $UCB$, $M3$, $S$ or $Exp3$ algorithms have good behaviours on average in RMG. Besides, hedging algorithms have been shown to be effective on prediction problems. An hedging algorithm is made up with a top-level algorithm and a set of basic algorithms. To make its decision, an hedging algorithm uses its top-level algorithm to choose a basic algorithm, and the chosen algorithm makes the decision. This paper experimentally shows that well-selected hedging algorithms are better on average than all previous MAL algorithms on the task of playing RMG against various players. $S$ is a very good top-level algorithm, and $UCB$ and $M3$ are very good basic algorithms. Furthermore, two-level hedging algorithms are more effective than one-level hedging algorithms, and three levels are not better than two levels.
* 12 pages, Workshop of the European Conference on Machine Learning on Machine Learning and Data Mining in and around Games, 2011